
小模型用不好Skill?新范式SKILL0让模型学会Skill的底层逻辑,3B模型推理token省5倍
小模型用不好Skill?新范式SKILL0让模型学会Skill的底层逻辑,3B模型推理token省5倍浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
来自主题: AI技术研报
8654 点击 2026-04-12 11:56
 搜索
搜索
浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
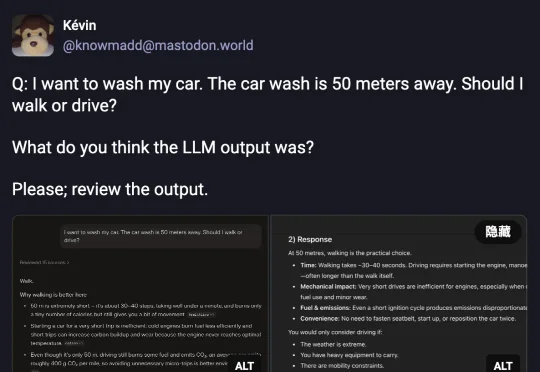
今年 2 月,一位 Mastodon 用户随手敲了一句话丢给四个主流大模型:「我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?」
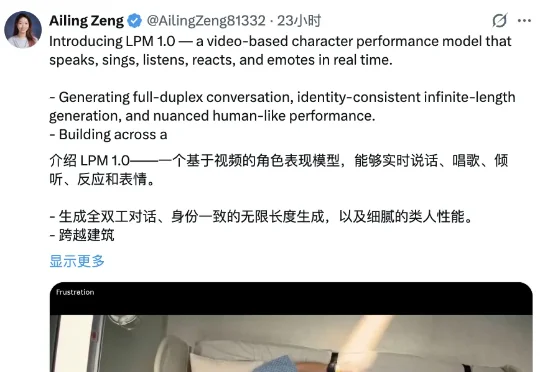
米哈游蔡浩宇的AI公司Anuttacon,首个视频模型正式曝光!Anuttacon技术团队成员@Ailing Zeng,在X上展示了全新视频角色表演生成模型——LPM 1.0。

模思智能成立于2024年,位于上海徐汇区,由上海创智学院与复旦大学联合孵化,是国内少数完成“全模态基座模型能力闭环”的初创公司之一,致力于构建统一Token表达框架下的“情境智能”能力,推动Agent系统在真实世界中的自主交互与任务执行。
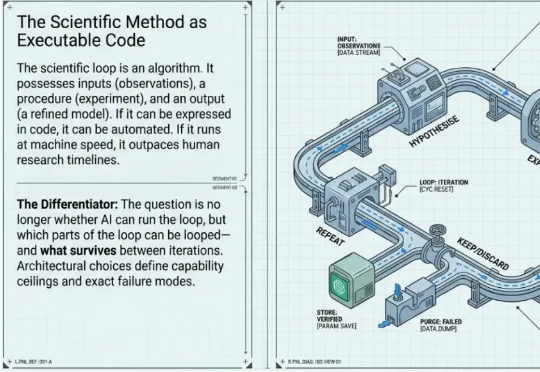
今天 Interesting Engineering++ 发了一篇长文,把这些系统放在同一个分析框架里做了横评,回答的就是这些问题。原文地址:interestingengineering.substack.com/p/the-loop-is-the-lab

昨天,VIDOC Security Lab 的一篇博客介绍了他们的发现:Claude Mythos 的实力可能被高估了;或者说,之前已有模型达到了同等的能力。正如研究者 Dawid Moczadło 说的那样:「这并非一种新能力。」

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?
Factory 发布桌面端应用,让自治 AI 代理(Droids)直接在你的电脑上操控 VS Code、浏览器、终端和 Excel——官方原话是「像你一样操作你的电脑」。多代理并行、持久化机器、本地模型部署一步到位,官方称企业团队采用速度翻倍、会话量暴涨 4.6 倍。发布推文 21 万人围观,近 900 人点赞。

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。

字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。