
15个模板复制粘贴,让同一个AI聪明十倍:上下文工程实战手册
15个模板复制粘贴,让同一个AI聪明十倍:上下文工程实战手册Nav Toor 的上一篇上下文工程文章火了——上百万人阅读,上千人私信他同一个问题:"道理我都懂了,但我到底该打什么字?"
来自主题: AI技术研报
8114 点击 2026-04-10 08:37
 搜索
搜索
Nav Toor 的上一篇上下文工程文章火了——上百万人阅读,上千人私信他同一个问题:"道理我都懂了,但我到底该打什么字?"

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。
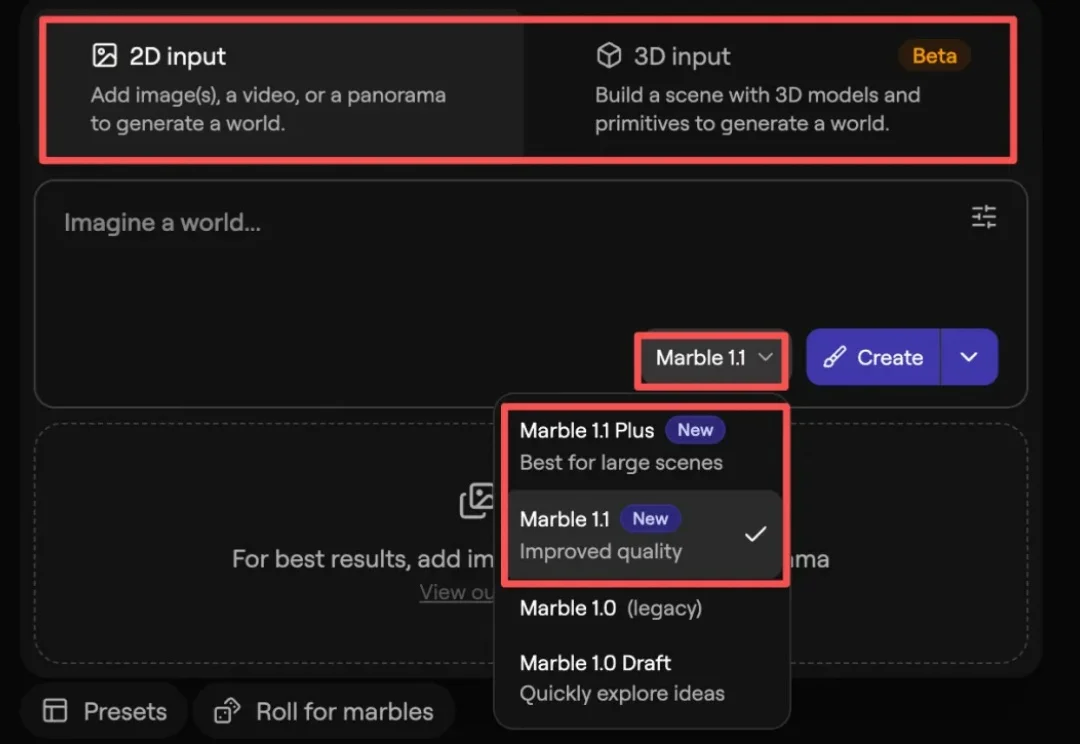
李飞飞的 World Labs 又更新模型了。

Claude Code这样私有的编程智能体虽然能力强大,但有着封闭、昂贵、难以定制的局限。艾伦研究院推出的Open Coding Agents,让你只需要400美元就能训练一个32B的专属编程智能体。

Anthropic 发布了史上最强的模型 Claude Mythos。

MSL交出首张答卷。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。
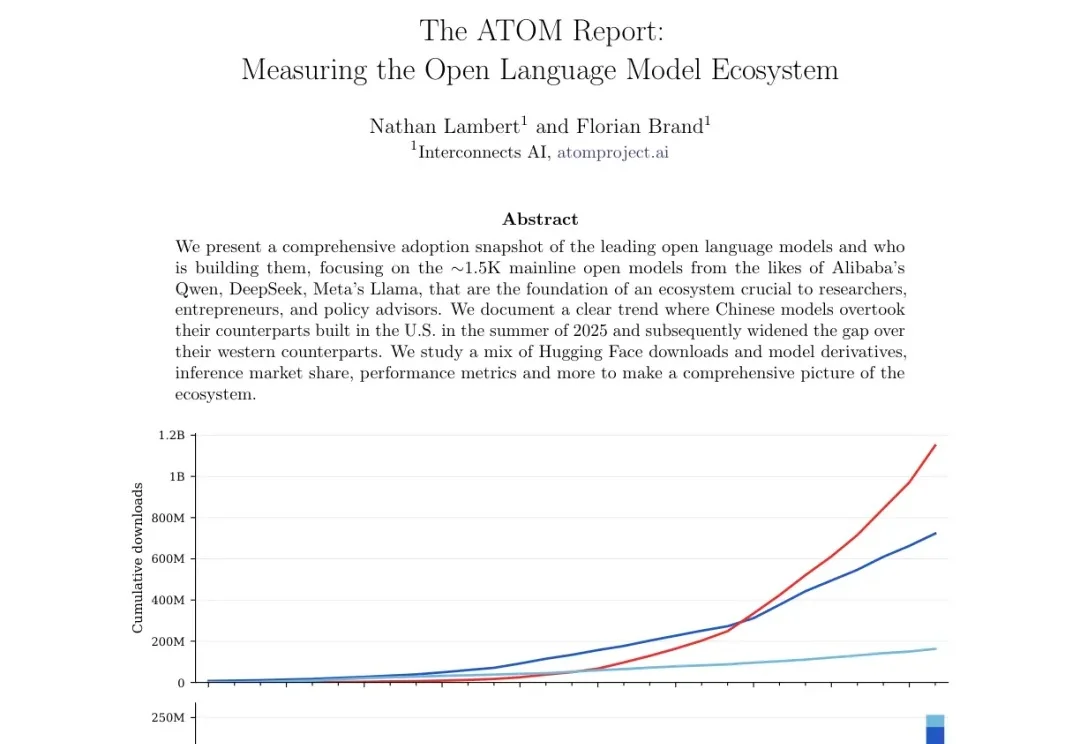
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月
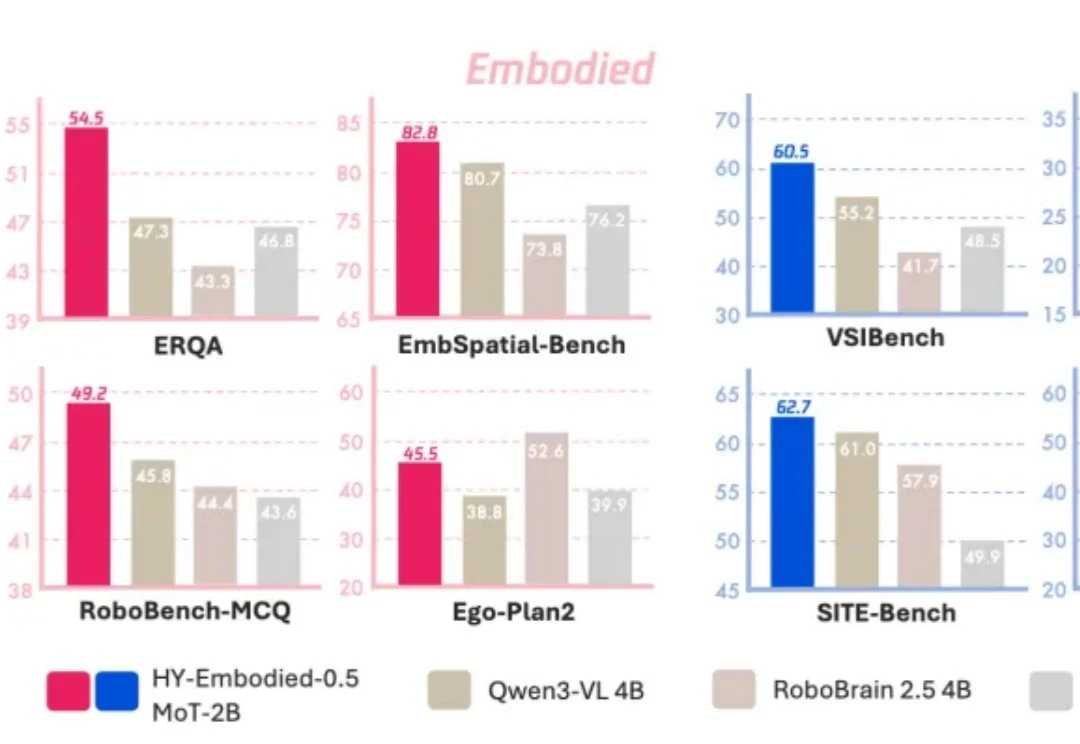
让大模型真正走进现实世界,是当下最迫切的需求之一。