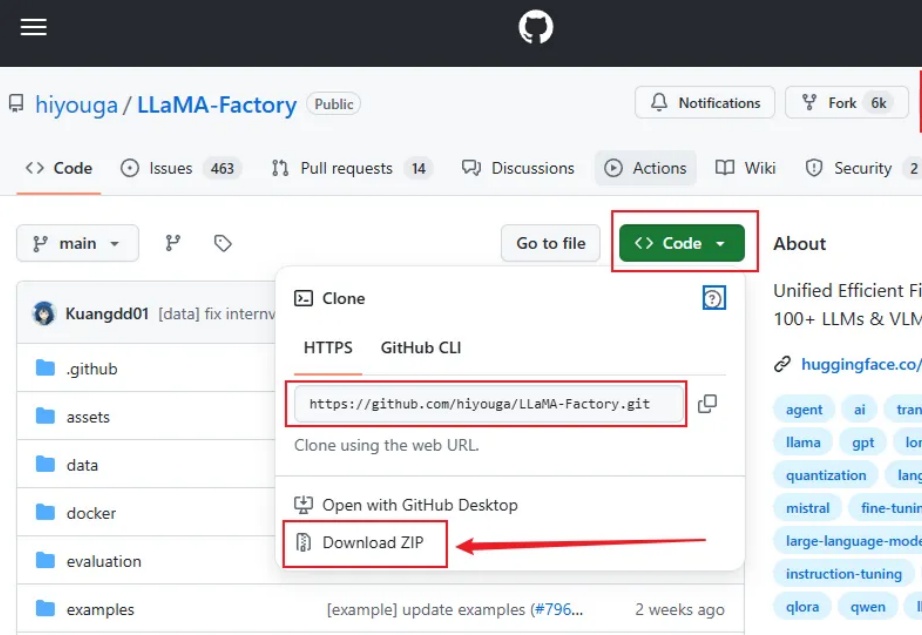
3步轻松微调Qwen3,本地电脑就能搞,这个方案可以封神了!【喂饭级教程】
3步轻松微调Qwen3,本地电脑就能搞,这个方案可以封神了!【喂饭级教程】大家好,我是袋鼠帝 今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。
来自主题: AI技术研报
10314 点击 2025-05-27 13:38
 搜索
搜索
大家好,我是袋鼠帝 今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。

今天凌晨,OpenAI 发布了新模型 GPT-4.1,相对比 4o,GPT-4.1 在编程和指令遵循方面的能力显著提升,同时还宣布 GPT-4.5 将会在几个月后下线。不少人吐槽 OpenAI 让人迷惑的产品发布逻辑——GPT-4.1 晚于 4.5 发布,以及混乱的模型命名,这些问题,都能在 OpenAI CPO Kevin Weil 最近的一期播客访谈中得到解答。

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。
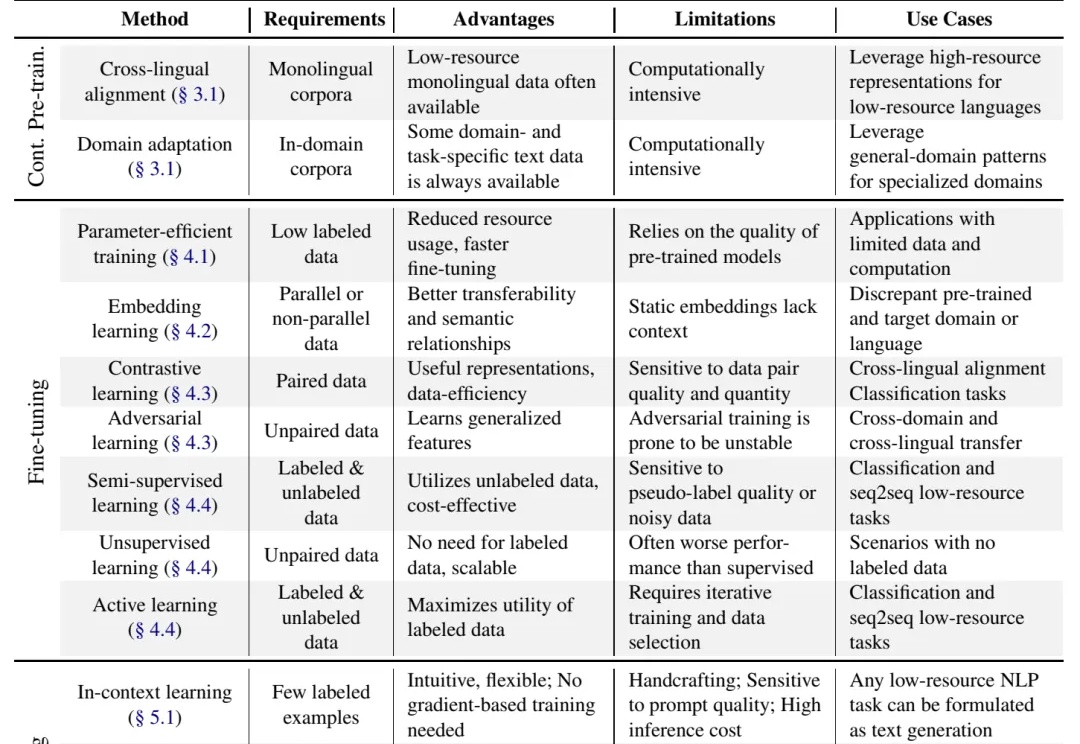
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。

比LoRA更高效的模型微调方法来了——

OpenAI推出GPT-4o模型微调功能。

开源大语言模型(LLM)百花齐放,为了让它们适应各种下游任务,微调(fine-tuning)是最广泛采用的基本方法。基于自动微分技术(auto-differentiation)的一阶优化器(SGD、Adam 等)虽然在模型微调中占据主流,然而在模型越来越大的今天,却带来越来越大的显存压力。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。

在上一篇文章「Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存」中,我们介绍了Unsloth,这是一个大模型训练加速和显存高效的训练框架,我们已将其整合到Firefly训练框架中,并且对Llama3-8B的训练进行了测试,Unsloth可大幅提升训练速度和减少显存占用。

在微调大型模型的过程中,一个常用的策略是“知识蒸馏”,这意味着借助高性能模型,如GPT-4,来优化性能较低的开源模型。这种方法背后隐含的哲学理念与logos中心论相似,把GPT-4等模型视为更接近唯一的逻辑或真理的存在。