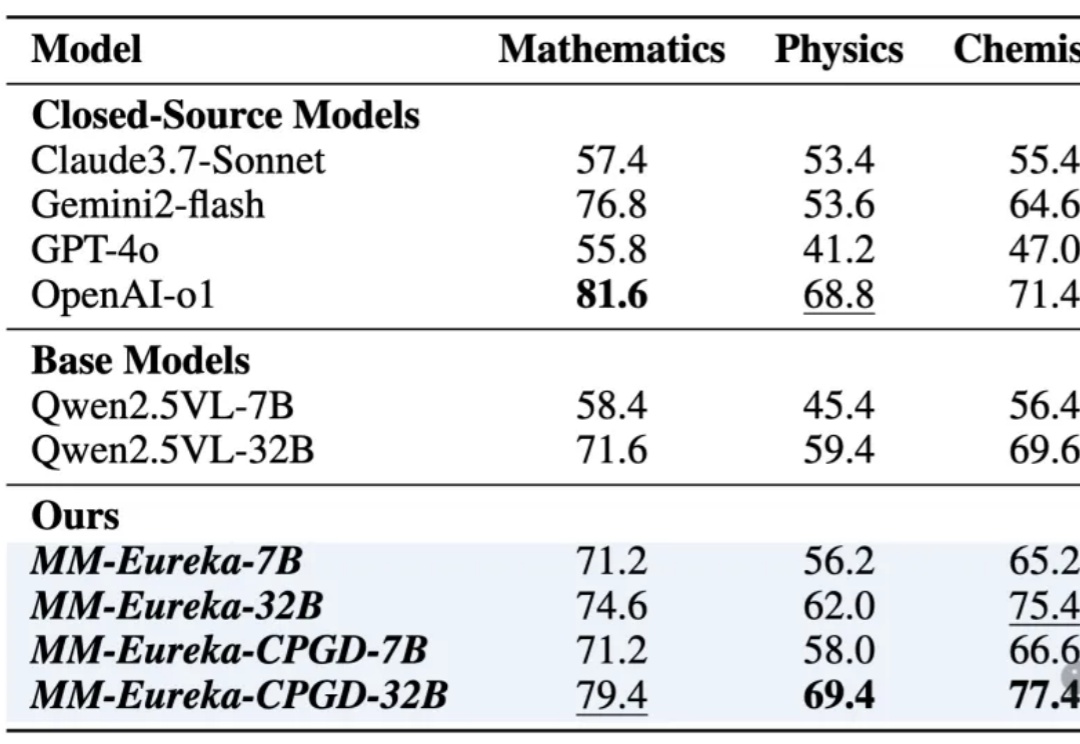
只训练数学,却在物理化学生物战胜o1!新强化学习算法带来显著性能提升,还缓解训练崩溃问题
只训练数学,却在物理化学生物战胜o1!新强化学习算法带来显著性能提升,还缓解训练崩溃问题只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
来自主题: AI技术研报
9784 点击 2025-06-23 14:29
 搜索
搜索
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。
人类在学习新知识时,总是遵循从“记忆事实”到“理解概念”再到“掌握技能”的认知路径。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
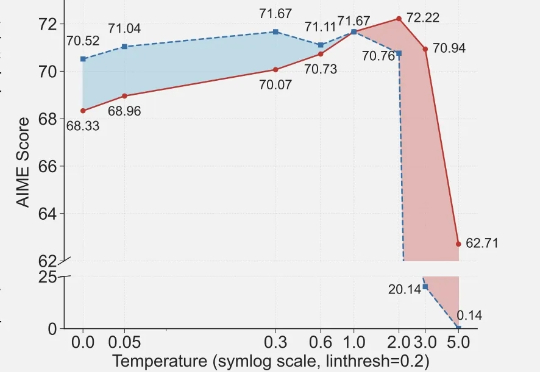
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。
大模型推理,无疑是当下最受热议的科技话题之一。
孙子兵法有云:“故其疾如风,其徐如林”,意指在行进迅速时,如狂风飞旋;而在行进从容时,如森林徐徐展开。
1+1等于几?

近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。