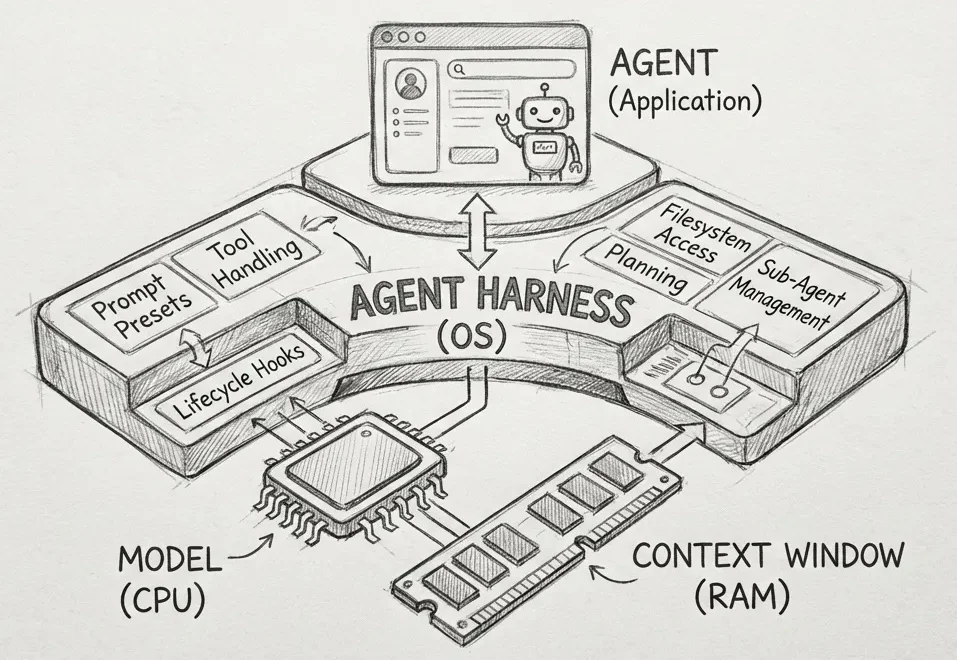
一些大模型,高分低能,为何?
一些大模型,高分低能,为何?这篇文章的思路来自 Philipp Schmid,由 minghao 推荐 https://www.philschmid.de/agent-harness-2026
来自主题: AI资讯
10026 点击 2026-01-07 16:01
 搜索
搜索
这篇文章的思路来自 Philipp Schmid,由 minghao 推荐 https://www.philschmid.de/agent-harness-2026

OpenRouter 创立于 2023 年初,给用户提供一个统一的 API Key,用于调用自身接入的所有模型,既包括了市面上的主流基础模型,也包括部分开源模型,一些开源模型还有多个不同的供应商。如果用户选择使用自有的 Key ,也可以同时享受 OpenRouter 的统一接口与其他服务。

人类一眼就能看懂的文字,AI居然全军覆没。

又一个让大模型几乎全军覆没的难题出现了。
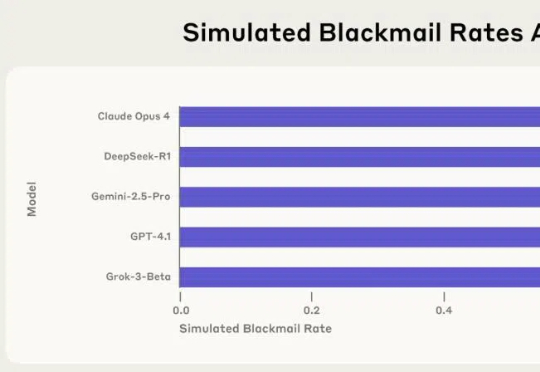
AI不一定是“邪恶”的,但它也远非“中立无害”。 过去几年里,我们习惯了通过 ChatGPT 等 AI 产品提问、聊天、生成代码。

拷打AI的难度还在升级?这不,图像推理又出现了新难题。
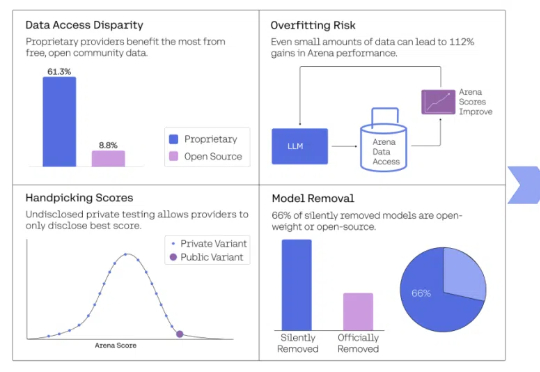
大模型竞技场的可信度,再次被锤。

数学题, 一直是检验 AI 实力的 “硬核考场” —— 公式推导、逻辑链条、抽象思维缺一不可 。最近,我好了几天时间对国内外 7 款大厂模型展开了一场 “数学高考 ”,用阿里全球数学竞赛 + 中国奥赛真题实测它们的智商上限。

AI界「智商大考」ARC-AGI-2重磅出炉了!一个人类用5分钟轻松解开的谜题,却让最顶尖LLM全线崩盘得分挂零,o3更是从曾经76%暴跌至4%。它正式宣告,人类还未实现AGI。

先是三星宣布智谱的Agentic GLM成为其新手机Galaxy S25的AI能力来源,紧接着The Information爆料,在经历了近一年的模型测试与合作伙伴探索后,苹果终于敲定了中国市场的合作伙伴:阿里巴巴。这意味着,中国iPhone用户很可能在今年迎来一个由国产大模型驱动的iPhone。