告别「一条路走到黑」:通过自我纠错,打造更聪明的Search Agent
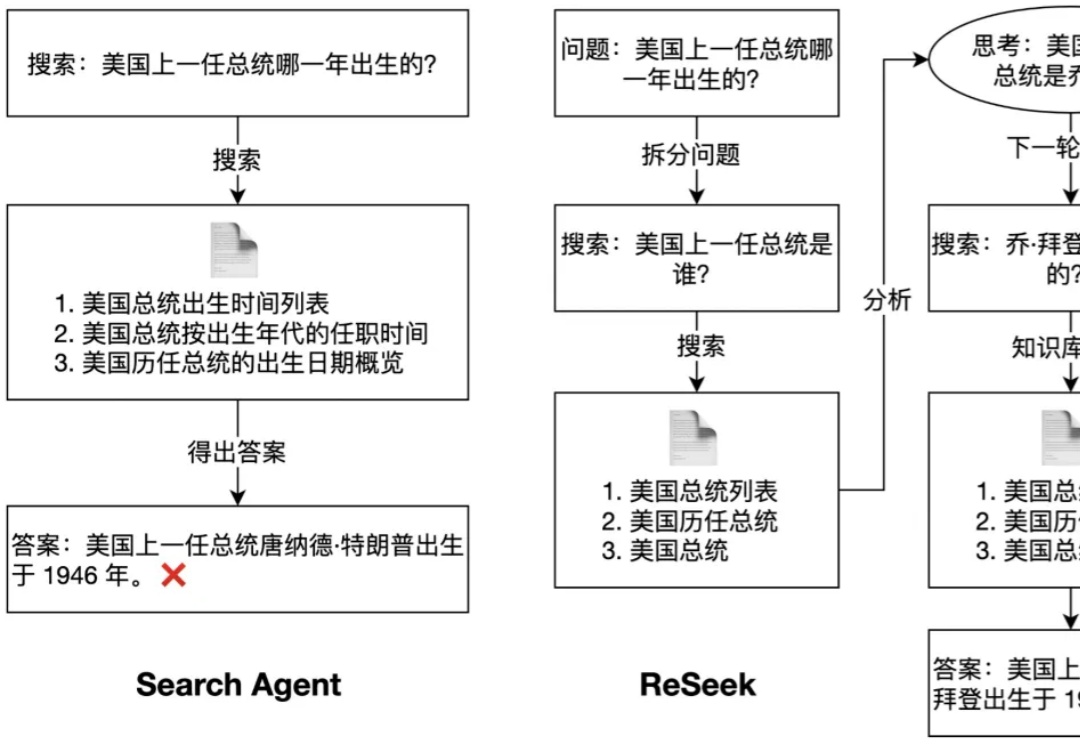
告别「一条路走到黑」:通过自我纠错,打造更聪明的Search Agent为了同时解决知识的实时性和推理的复杂性这两大挑战,搜索智能体(Search Agent)应运而生。它与 RAG 的核心区别在于,Search Agent 能够通过与实时搜索引擎进行多轮交互来分解并执行复杂任务。这种能力在人物画像构建,偏好搜索等任务中至关重要,因为它能模拟人类专家进行深度、实时的资料挖掘。
来自主题: AI技术研报
7703 点击 2025-11-18 14:39