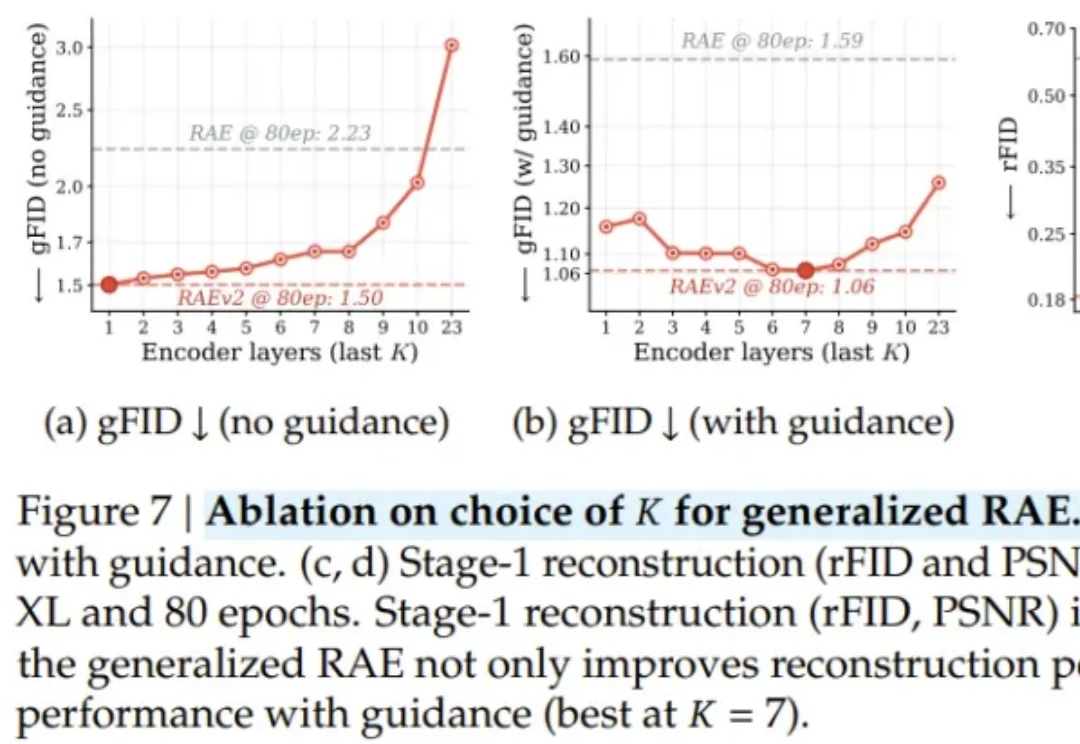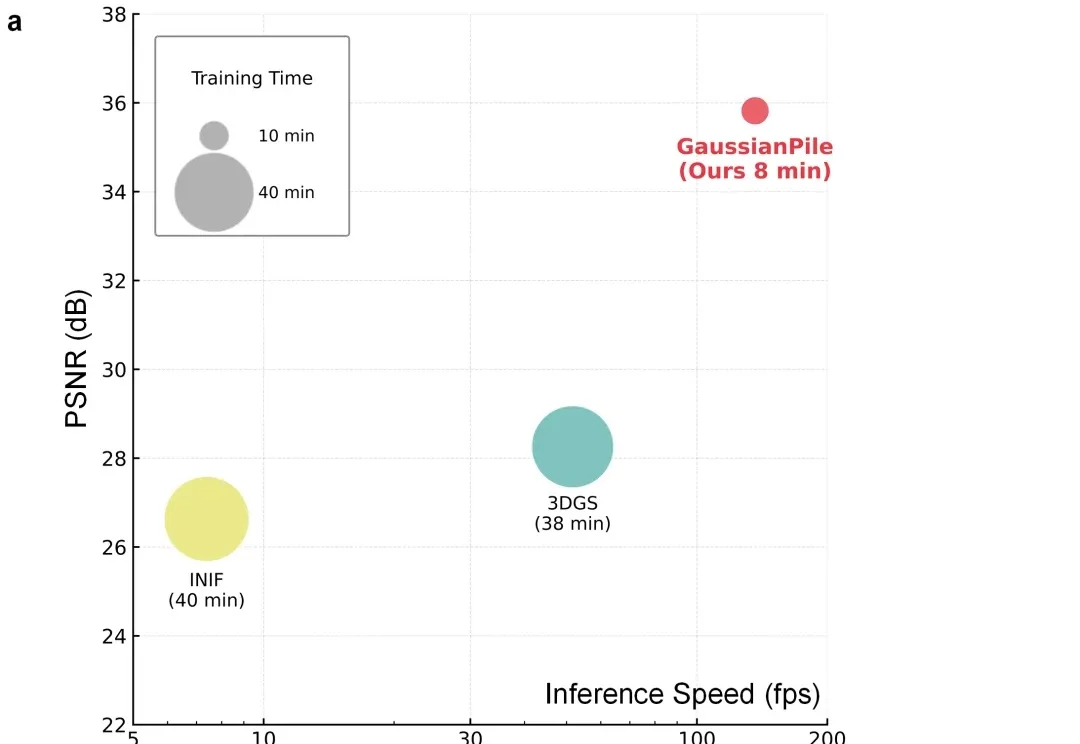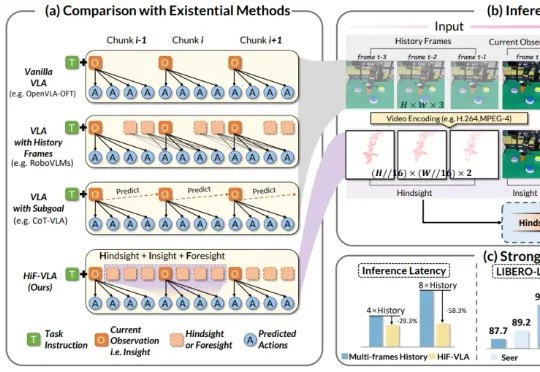
CVPR 2026 | 突破短视,理解变化!HiF-VLA:以motion为中心打造「边想边做」的世界动作模型
CVPR 2026 | 突破短视,理解变化!HiF-VLA:以motion为中心打造「边想边做」的世界动作模型来自西湖大学、浙江大学、西湖机器人等机构的研究团队提出了一种以运动(Motion)为中心的全新双向时空推理框架 HiF-VLA。抛弃冗余的像素级输入,HiF-VLA 巧妙提取低维紧凑的 Motion 向量作为动态先验,在一个创新的「联合专家」模块中,同步完成未来视觉运动的预测与高精度动作序列的生成。
来自主题: AI技术研报
8208 点击 2026-05-23 09:55