ACMMM 2025 | 北大团队提出 InteractMove:3D场景中人与可移动物体交互动作生成新框架
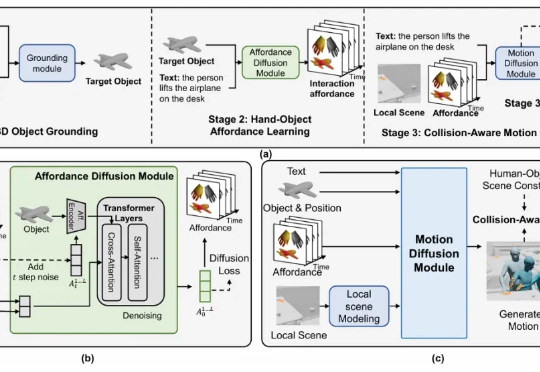
ACMMM 2025 | 北大团队提出 InteractMove:3D场景中人与可移动物体交互动作生成新框架该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
来自主题: AI技术研报
7905 点击 2025-10-20 14:40
 搜索
搜索
该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
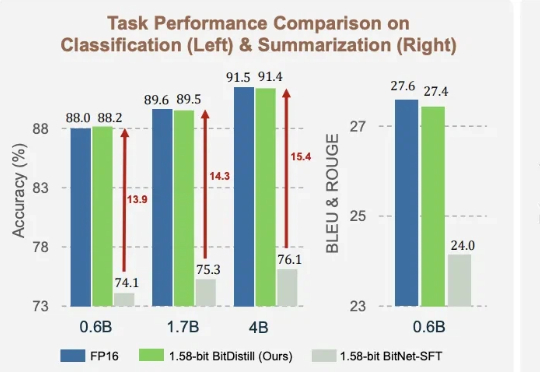
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
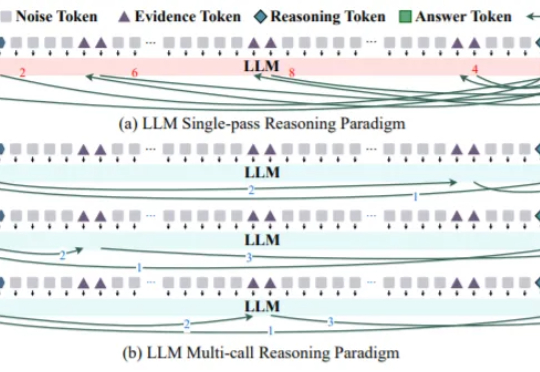
近日,来自阿联酋穆罕默德·本·扎耶德人工智能大学 MBZUAI 和保加利亚 INSAIT 研究所的研究人员发现一个针对大模型单次推理的“法诺式准确率上限”,借此不仅揭示了单次生成范式的根本性脆弱点,也揭示了“准确率悬崖”这一现象。

具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
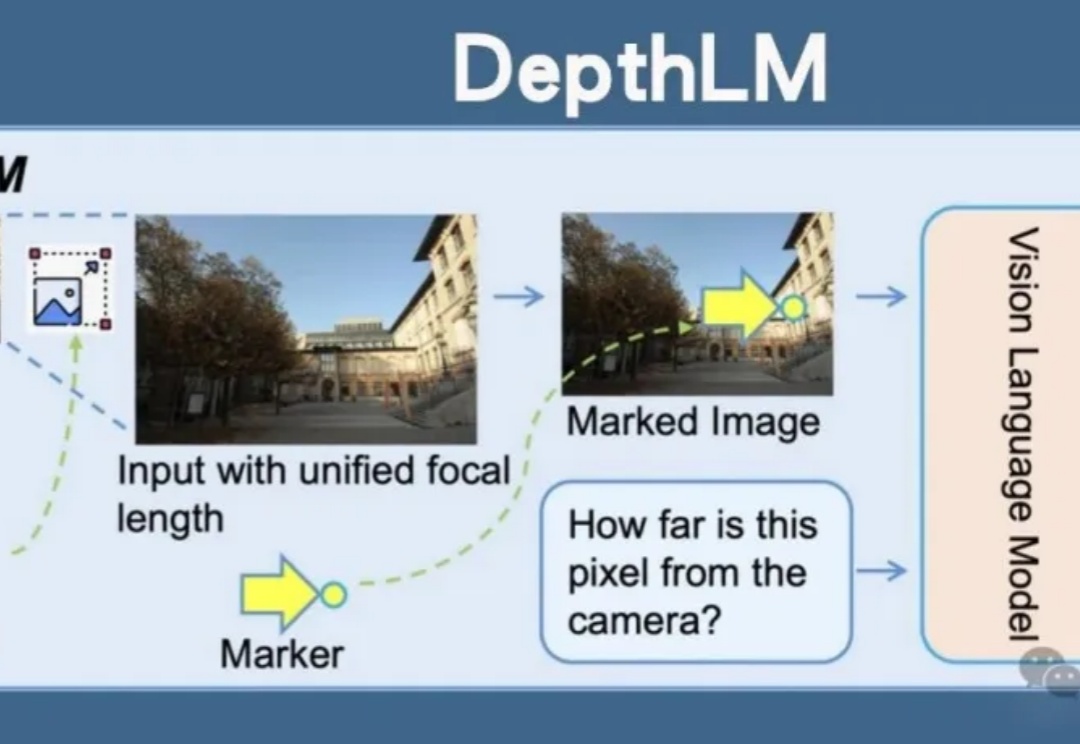
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。

每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。

Meta提出早期经验(Early Experience)让代理在无奖励下从自身经验中学习:在专家状态上采样替代动作、执行并收集未来状态,将这些真实后果当作监督信号。核心是把“自己造成的未来状态”转为可规模化的监督。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。

OpenAI的封闭模型在IOI 2025竞赛夺金的同时,英伟达团队交出了一份同样令人振奋的答卷——他们利用完全开源的大模型和全新的GenCluster策略,在IOI 2025竞赛中跑出了媲美金牌选手的成绩!开源模型首次达到了IOI金牌水准。这究竟是怎样实现的?