
ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力
ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
来自主题: AI技术研报
9357 点击 2025-08-22 10:35
 搜索
搜索
在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
在AI浪潮席卷全球的2025年,大语言模型(LLM)已从单纯的聊天工具演变为能规划、决策的智能体。但问题来了:这些智能体一旦部署,就如「冻结的冰块」,难以适应瞬息万变的世界。

这真的是一种平衡艺术——要搞清楚模型应该具备哪些特性,以及我们希望它给人的“感觉”是什么。GPT-5发布时,我们觉得正好是一次重置和重新思考的机会。尤其是,现在要让一个模型变得很“有互动感”其实很容易,但有时候这种互动可能是不健康的,所以我们想让它成为一个健康、有帮助的助手。
AI 有意识吗? 无论是古今中外的文艺作品中,还是 AI 迅猛发展的当下,好像都难以给出一个绝对的答案。
AI 下半场,模型评估比模型训练更重要。我们需要从根本上重新思考评估的方式。
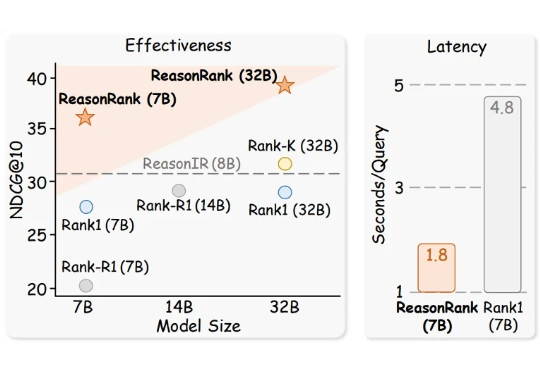
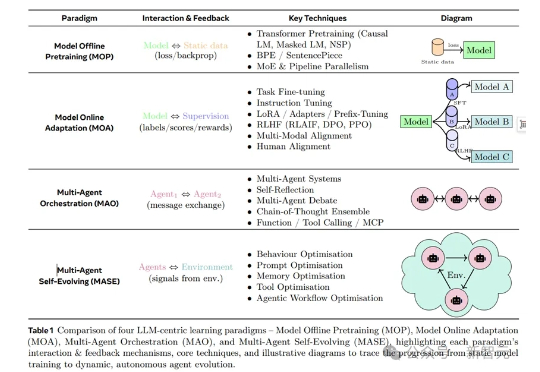
推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
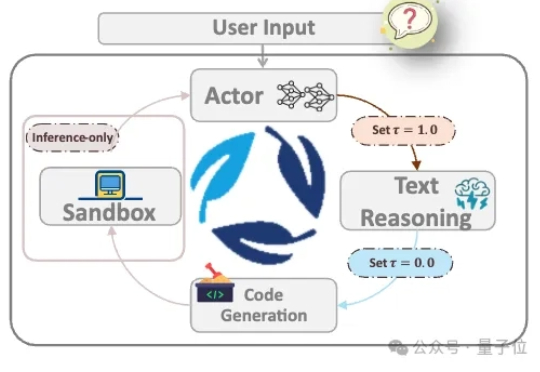
在Openai 发布o3后,think with image功能得到了业界和学术界的广泛关注。
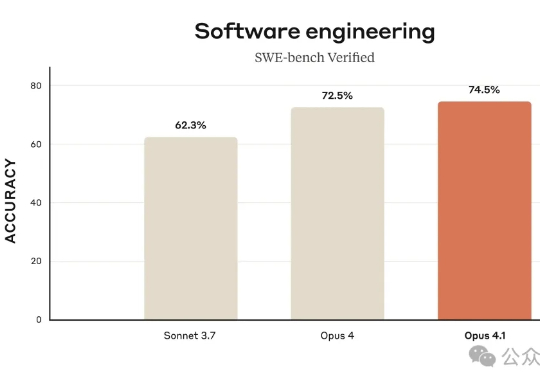
OpenAI在SWE-bench Verified编程测试中仅完成477道题却公布74.9%高分,对比之下,Anthropic的Claude完成全部500题。
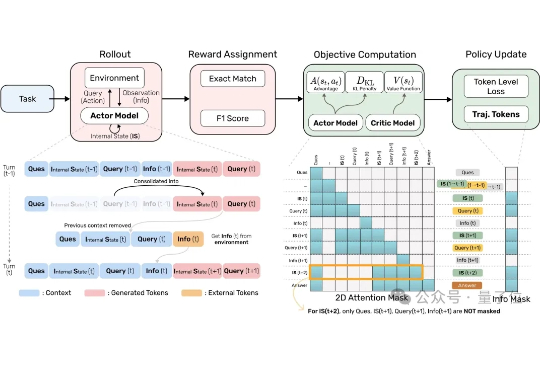
AI Agent正在被要求处理越来越多复杂的任务。 但当它要不停地查资料、跳页面、筛选信息时,显存狂飙、算力吃紧的问题就来了。

从 Sora 的惊艳亮相到多款高性能开源模型的诞生,视频生成在过去两年迎来爆发式进步,已能生成几十秒的高质量短片。然而,要想生成时长超过 1 分钟、内容与运动可控、风格统一的超长视频,仍面临巨大挑战。