

MM-Eureka:极少数据实现多模态推理的R1-Zero时刻
MM-Eureka:极少数据实现多模态推理的R1-Zero时刻尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。
来自主题: AI技术研报
8322 点击 2025-03-14 15:32
尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。
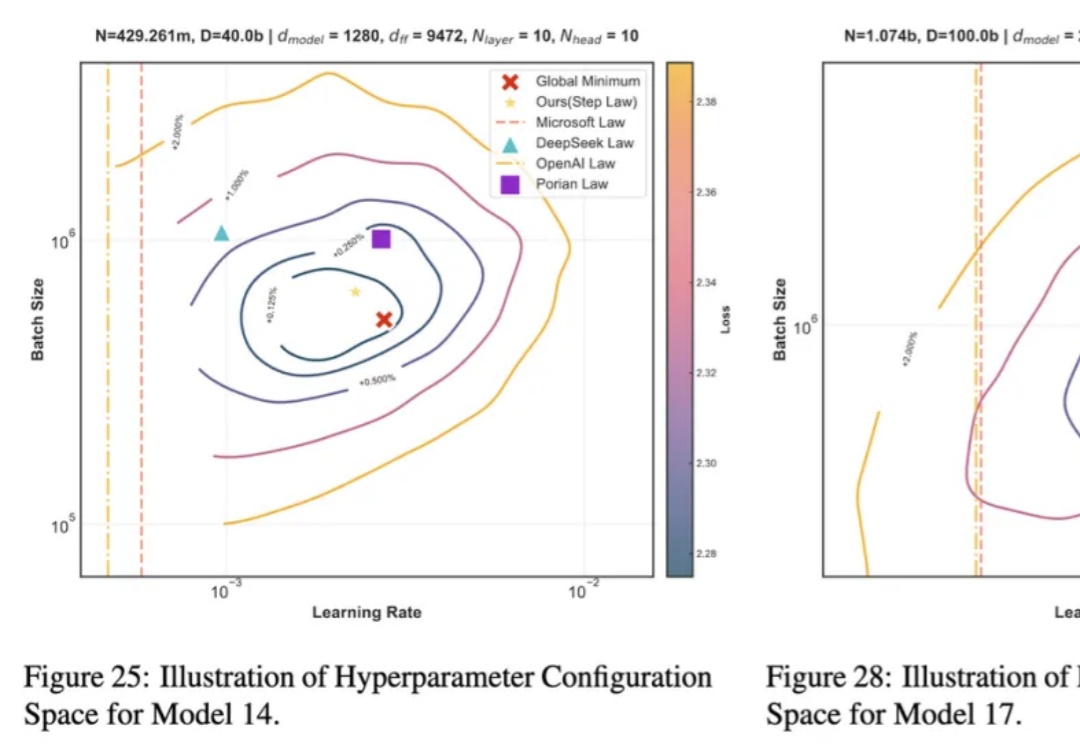
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。
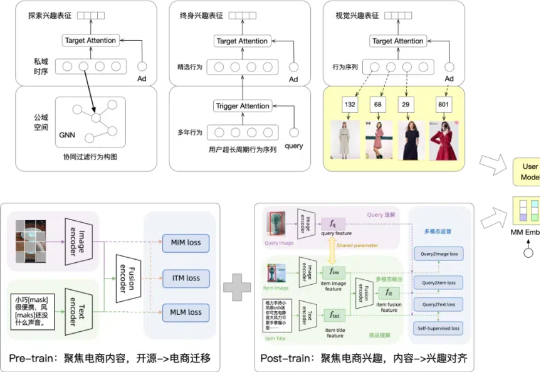
随着大模型时代的到来,搜推广模型是否具备新的进化空间?能否像深度学习时期那样迸发出旺盛的迭代生命力?带着这样的期待,阿里妈妈搜索广告在过去两年的持续探索中,逐步厘清了一些关键问题,成功落地了多个优化方向。

不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!

最新研究显示,以超强推理爆红的DeepSeek-R1模型竟藏隐形危险——
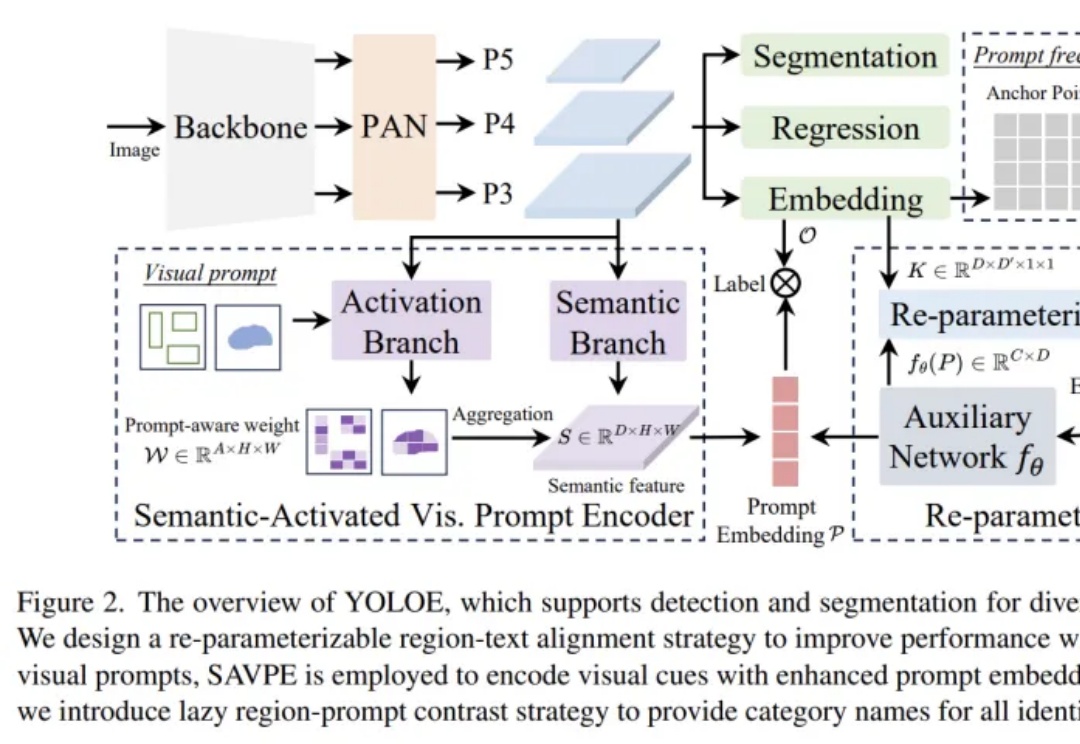
它能像人眼一样,在文本、视觉输入和无提示范式等不同机制下进行检测和分割。
近些年,大模型的发展可谓是繁花似锦、烈火烹油。从 2018 年 OpenAI 公司提出了 GPT-1 开始,到 2022 年底的 GPT-3,再到现在国内外大模型的「百模争锋」,DeepSeek 异军突起,各类大模型应用层出不穷。
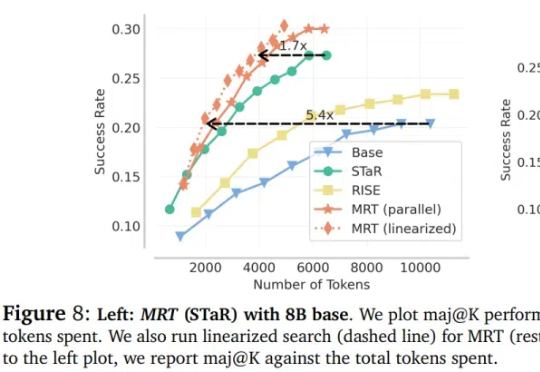
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。
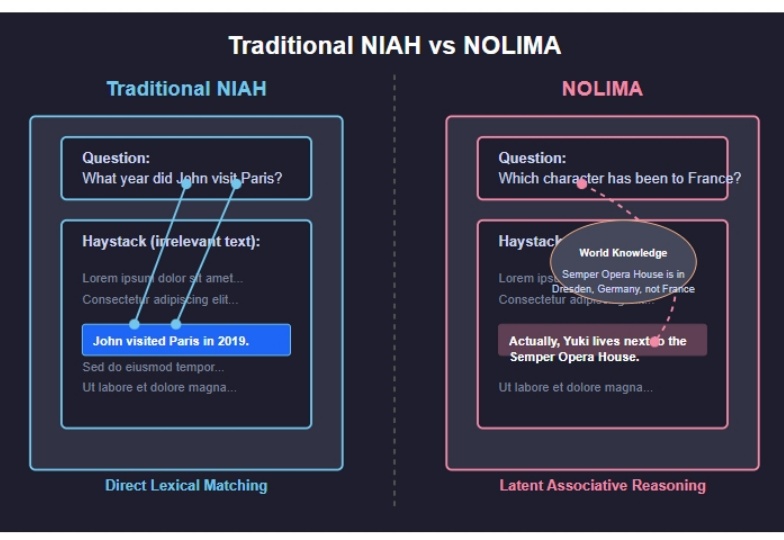
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。