
警惕 AI“罕见”危险行为!Anthropic 发文:一次评估失败也可能造成灾难性后果
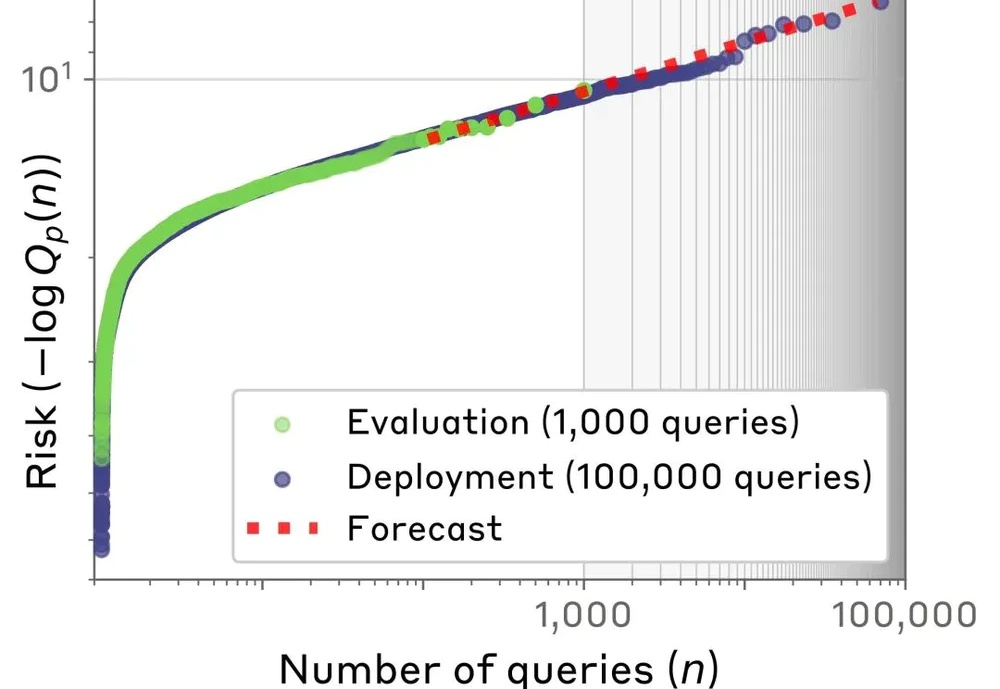
警惕 AI“罕见”危险行为!Anthropic 发文:一次评估失败也可能造成灾难性后果对齐科学的主要目标之一,是在危险行为发生之前,预测人工智能(AI)模型的危险行为倾向。
来自主题: AI资讯
5707 点击 2025-02-27 10:05
对齐科学的主要目标之一,是在危险行为发生之前,预测人工智能(AI)模型的危险行为倾向。

大自然的分形之美,蕴藏着宇宙的设计规则。刚刚,何恺明团队祭出「分形生成模型」,首次实现高分辨率逐像素建模,让计算效率飙升4000倍,开辟AI图像生成新范式。
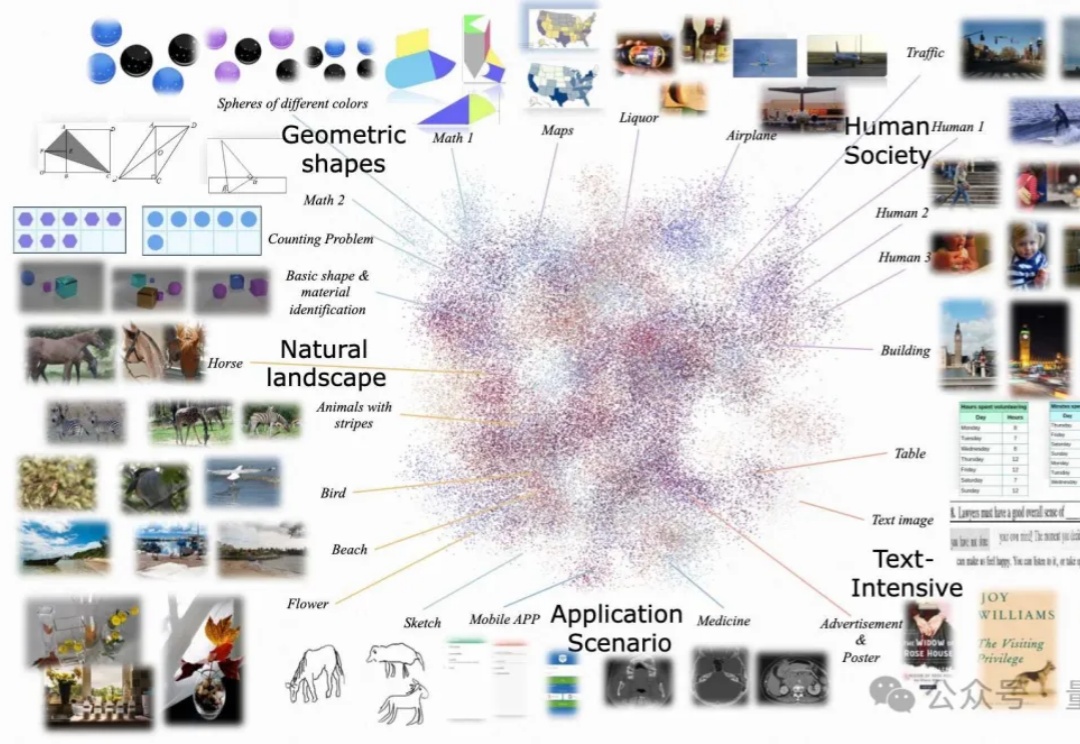
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
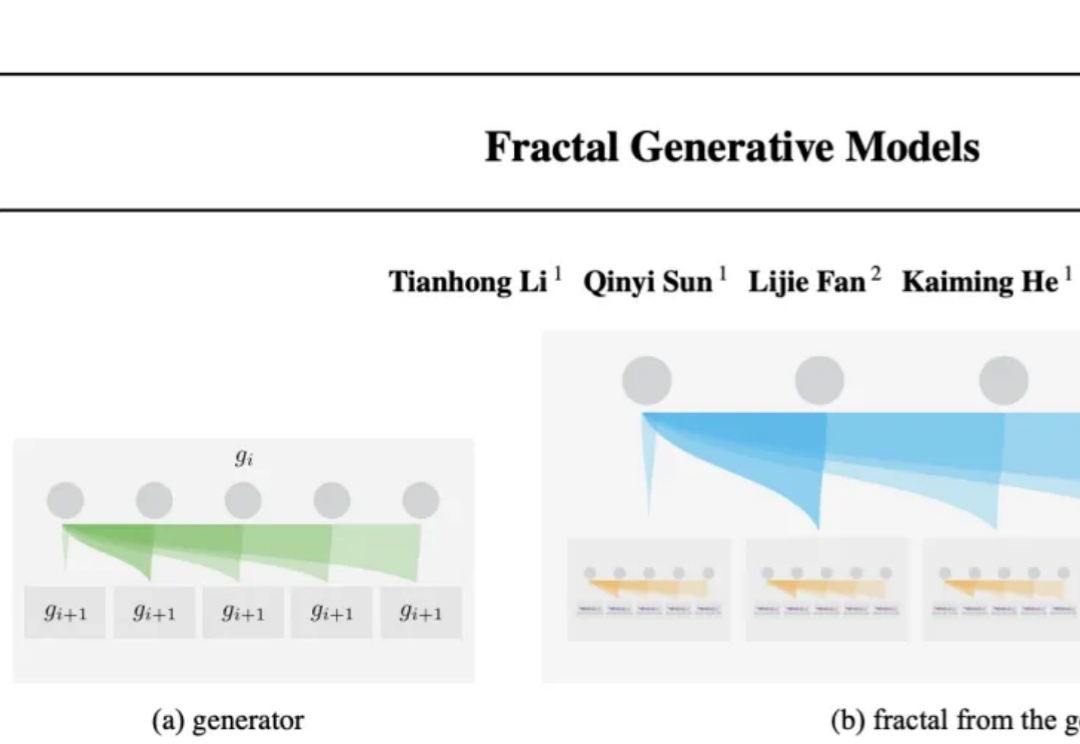
何恺明再次开宗立派!开辟了生成模型的全新范式——
DeepSeek 的开源周已经进行到了第三天(前两天报道见文末「相关阅读」)。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。

推理黑马出世,仅以5%参数量撼动AI圈。360、北大团队研发的中等量级推理模型Tiny-R1-32B-Preview正式亮相,32B参数,能够匹敌DeepSeek-R1-671B巨兽。
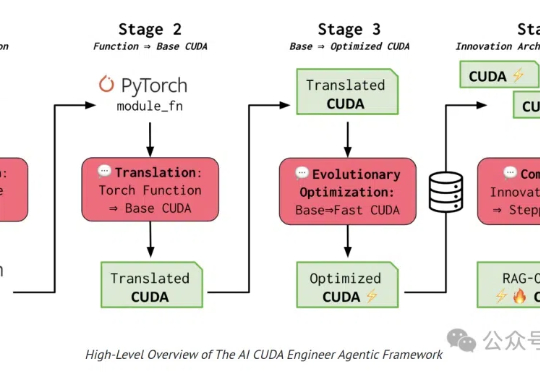
高调亮相的世界首个「AI CUDA工程师」,宣称能让模型训练速度飙升100倍,如今却上演了一场「作弊」闹剧。OpenAI研究员用o3-mini,11秒便发现了内核代码有bug!
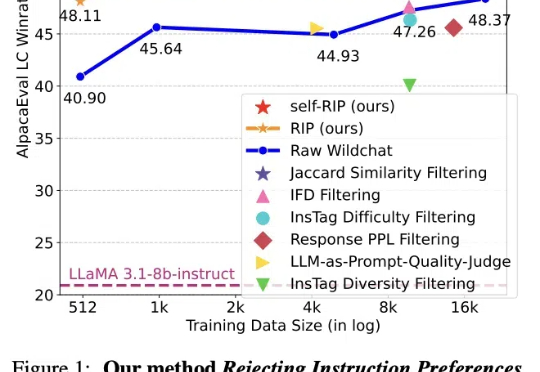
近日,Meta等机构发表的论文介绍了一种通过进化算法构造高质量数据集的方法:拒绝指令偏好(RIP),得到了Yann LeCun的转赞。相比未经过滤的数据,使用RIP构建的数据集让模型在多个基准测试中都实现了显著提升。