

比知识蒸馏好用,田渊栋等提出连续概念混合,再度革新Transformer预训练框架
比知识蒸馏好用,田渊栋等提出连续概念混合,再度革新Transformer预训练框架自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,
来自主题: AI技术研报
6178 点击 2025-02-16 13:12
自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,

问题挺严重,大模型说的话可不能全信。

人类智慧的一大特征是能够分步骤创造复杂作品,例如绘画、手工艺和烹饪等,这些过程体现了逻辑与美学的融合。

最新大语言模型推理测试引众议,DeepSeek R1常常在提供错误答案前就“我放弃”了?? Cursor刚刚参与了一项研究,他们基于NPR周日谜题挑战(The Sunday Puzzle),构建了一个包含近600个问题新基准测试。

7B大小的视频理解模型中的新SOTA,来了!
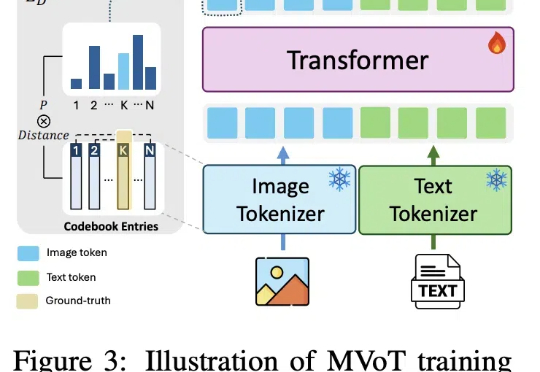
近日,微软和剑桥大学公布推理新方法:多模态思维可视化MVoT。新方法可以边推理,边「想象」,同时利用文本和图像信息学习,在实验中比CoT拥有更好的可解释性和稳健性,复杂情况下甚至比CoT强20%。还可以与CoT组合,进一步提升模型性能。

史上最大规模视觉语言数据集:1000亿图像-文本对!
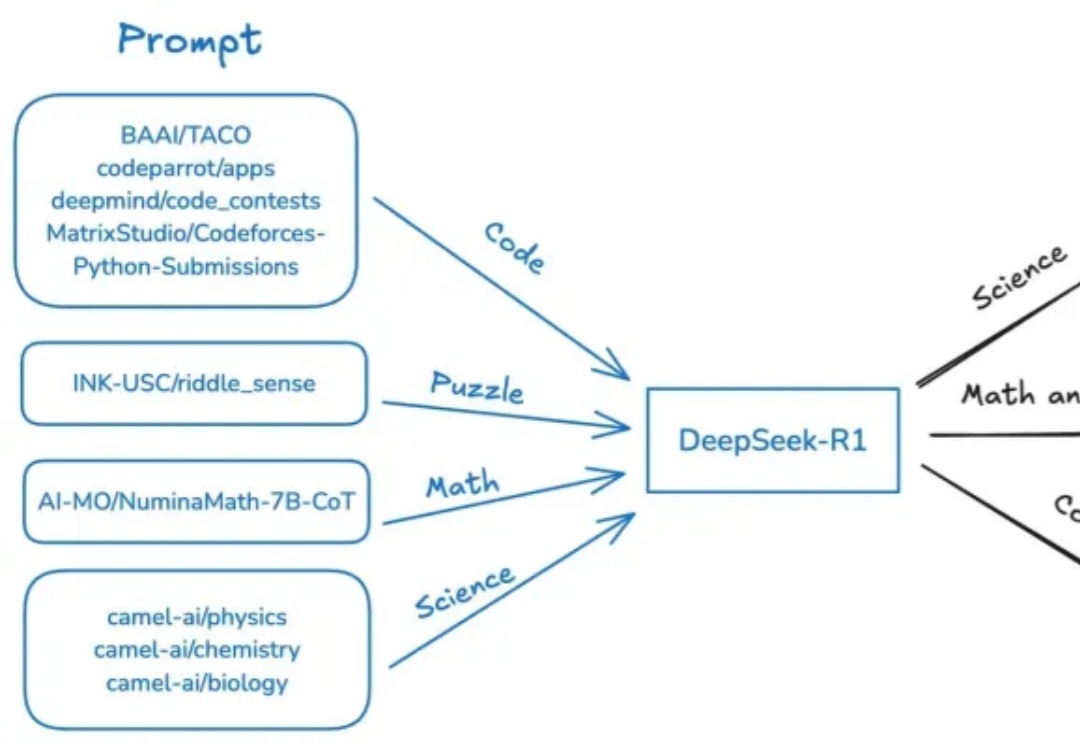
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

一个简单的笑脸😀可能远不止这么简单?最近,AI大神Karpathy发现,一个😀竟然占用了多达53个token!这背后隐藏着Unicode编码的哪些秘密?如何利用这些「隐形字符」在文本中嵌入、传递甚至「隐藏」任意数据。更有趣的是,这种「数据隐藏术」甚至能对AI模型进行「提示注入」!

今天向大家介绍一项来自香港大学黄超教授实验室的最新科研成果 VideoRAG。这项创新性的研究突破了超长视频理解任务中的时长限制,仅凭单张 RTX 3090 GPU (24GB) 就能高效理解数百小时的超长视频内容。