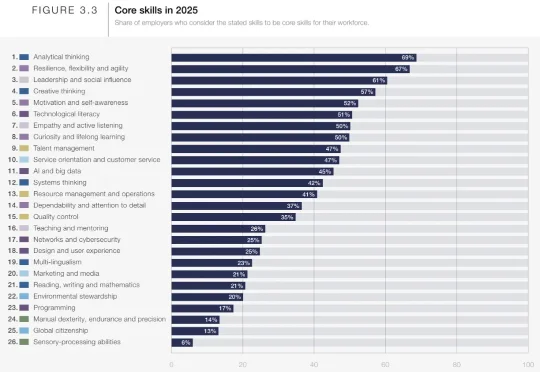
几千年都没考过这个?谷歌「最毒」AI考局,专测你在压力下怎么做人
几千年都没考过这个?谷歌「最毒」AI考局,专测你在压力下怎么做人最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
来自主题: AI技术研报
10206 点击 2026-05-03 23:04
 搜索
搜索
最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
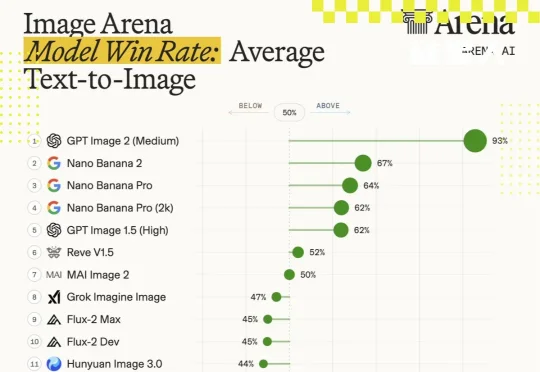
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
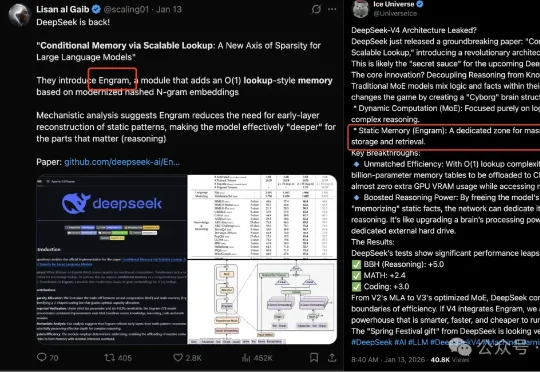
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。

为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。
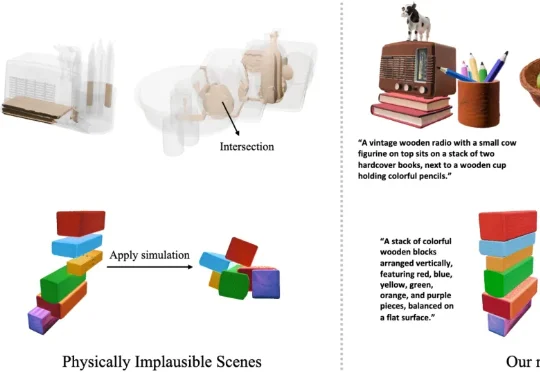
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。

在 AGI-Next 前沿峰会上,腾讯姚顺雨举了一个很生活化的例子:当你问 AI “今天吃什么” 时,真正限制答案质量的,可能不是模型不够大,也不是推理不够强,而是它不知道你今天冷不冷、想不想吃热的、最近和朋友聊过什么、家人又有什么偏好需要纳入考虑。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。

今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。