
小模型用不好Skill?新范式SKILL0让模型学会Skill的底层逻辑,3B模型推理token省5倍
小模型用不好Skill?新范式SKILL0让模型学会Skill的底层逻辑,3B模型推理token省5倍浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
来自主题: AI技术研报
8648 点击 2026-04-12 11:56
 搜索
搜索
浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
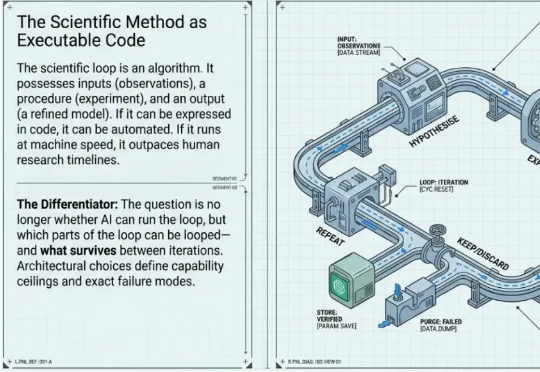
今天 Interesting Engineering++ 发了一篇长文,把这些系统放在同一个分析框架里做了横评,回答的就是这些问题。原文地址:interestingengineering.substack.com/p/the-loop-is-the-lab

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。
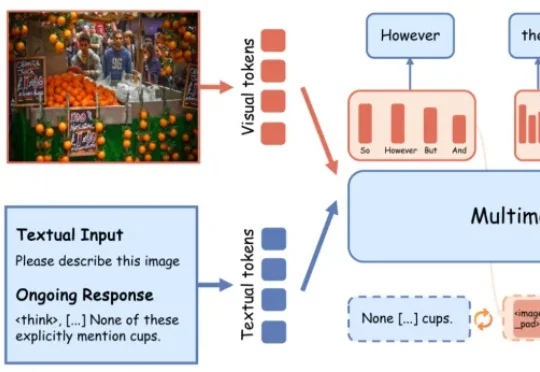
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。

最近,来自Meta与University of Copenhagen的研究者提出了OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory(收录于CVPR 2026)。这项工作聚焦于一个核心问题:如何在生成多镜头视频时,有效保留长程跨镜头上下文,从而实现更强的叙事一致性。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。
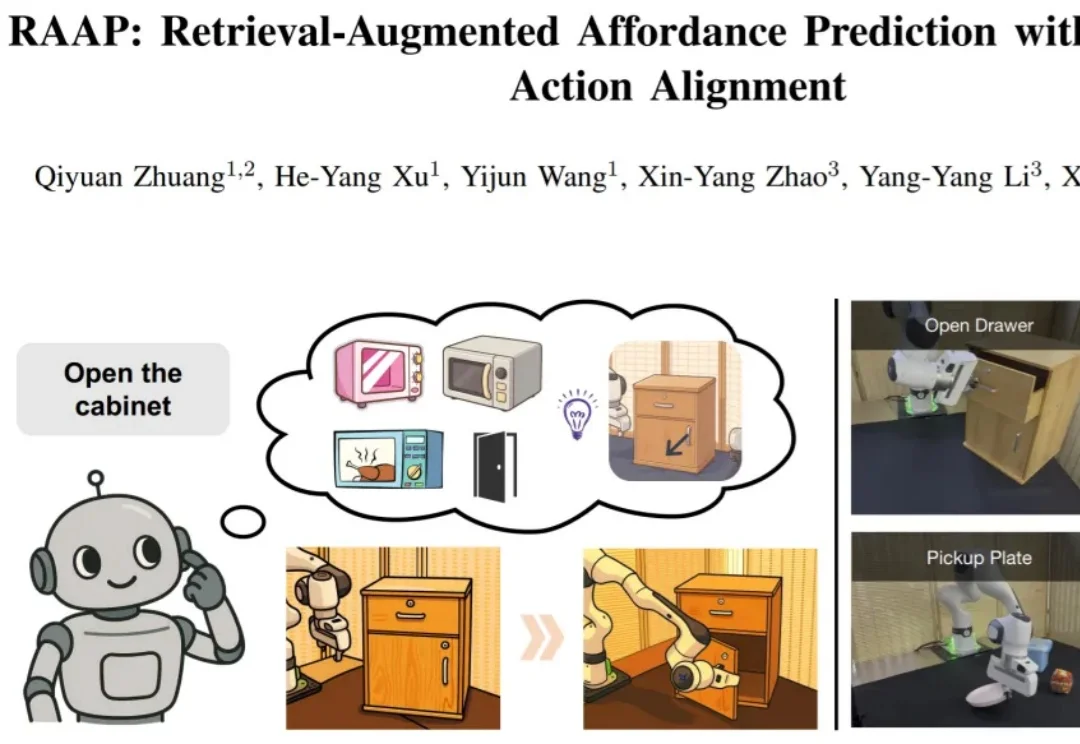
在具身智能领域,可供性(affordance)预测 —— 即让机器人从视觉观测中理解 "在哪里操作"(接触点)与 "如何操作"(动作方向)—— 是实现精细化机器人操作的基础之一。精细操作要求机器人不仅能定位到物体的可交互区域,更要掌握接触后的准确运动方向,例如判断抽屉把手的精确拉动方向完成开合。