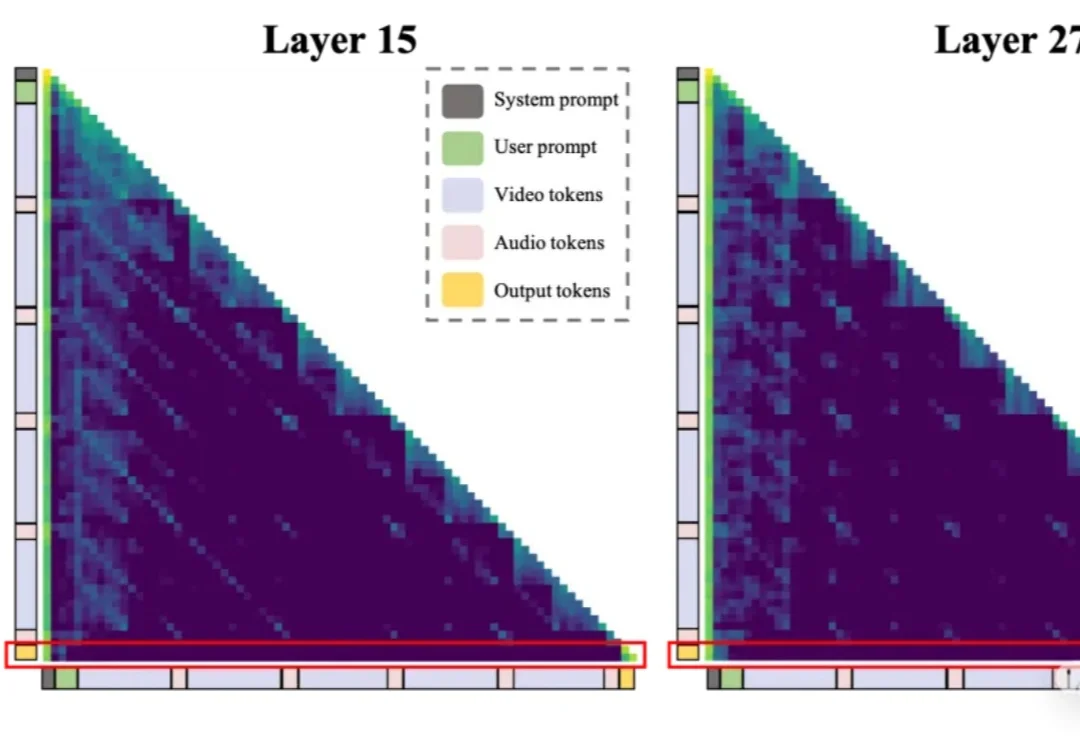
仅保留35% Token,性能反超原模型!快手可灵等用视觉信息引导音频压缩,推理时间直降42%
仅保留35% Token,性能反超原模型!快手可灵等用视觉信息引导音频压缩,推理时间直降42%一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。
来自主题: AI技术研报
8682 点击 2026-03-11 15:06
 搜索
搜索
一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。

近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。

对比学习已成为表征学习中的一种强大范式,能够在不依赖标签的情况下有效利用无标注数据。

扩散模型终于学会“看题下菜碟”了!

用强化学习微调扩散模型,还有更好的办法吗?

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。

DragStream,首次实现视频生成时的实时拖拽编辑。用户可随时拖动画面中的物体,自由平移、旋转或变形,系统自动保持后续帧连贯自然,无需重训模型,无缝适配主流AI视频生成器,真正实现「所见即所得」。

视频生成进入大规模时代,但计算成本也炸了。
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。