
李曼玲、李飞飞、吴佳俊等联手:评估具身大模型的新范式!
李曼玲、李飞飞、吴佳俊等联手:评估具身大模型的新范式!全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
来自主题: AI技术研报
10963 点击 2026-03-04 13:46
 搜索
搜索
全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
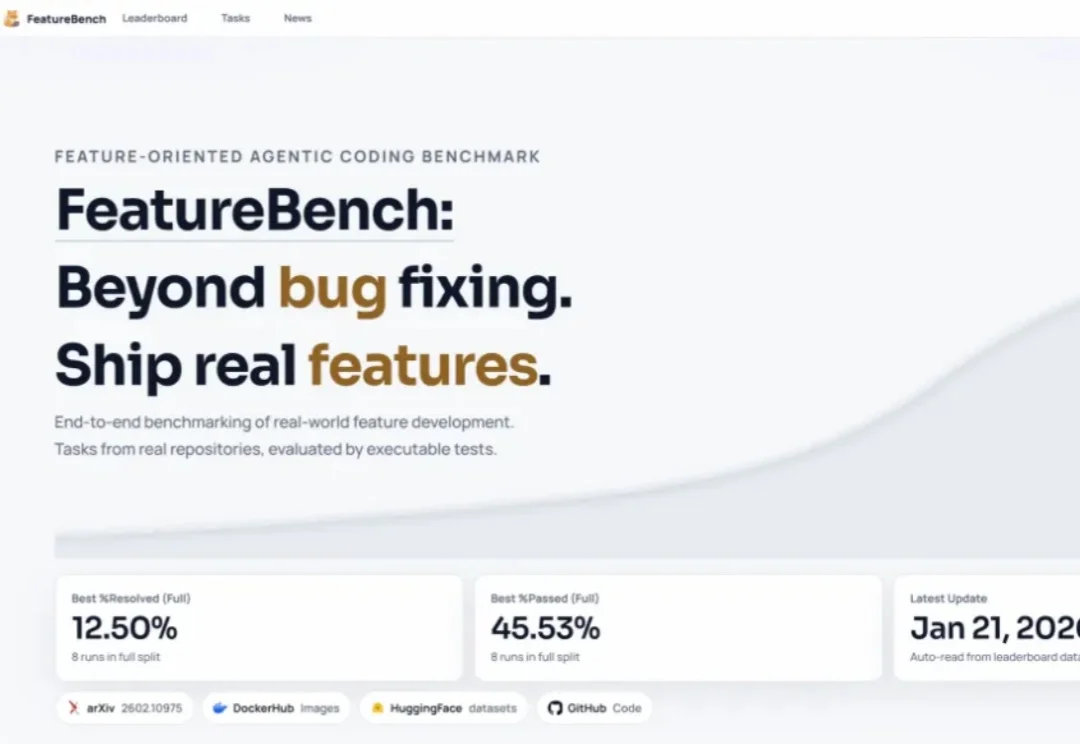
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。
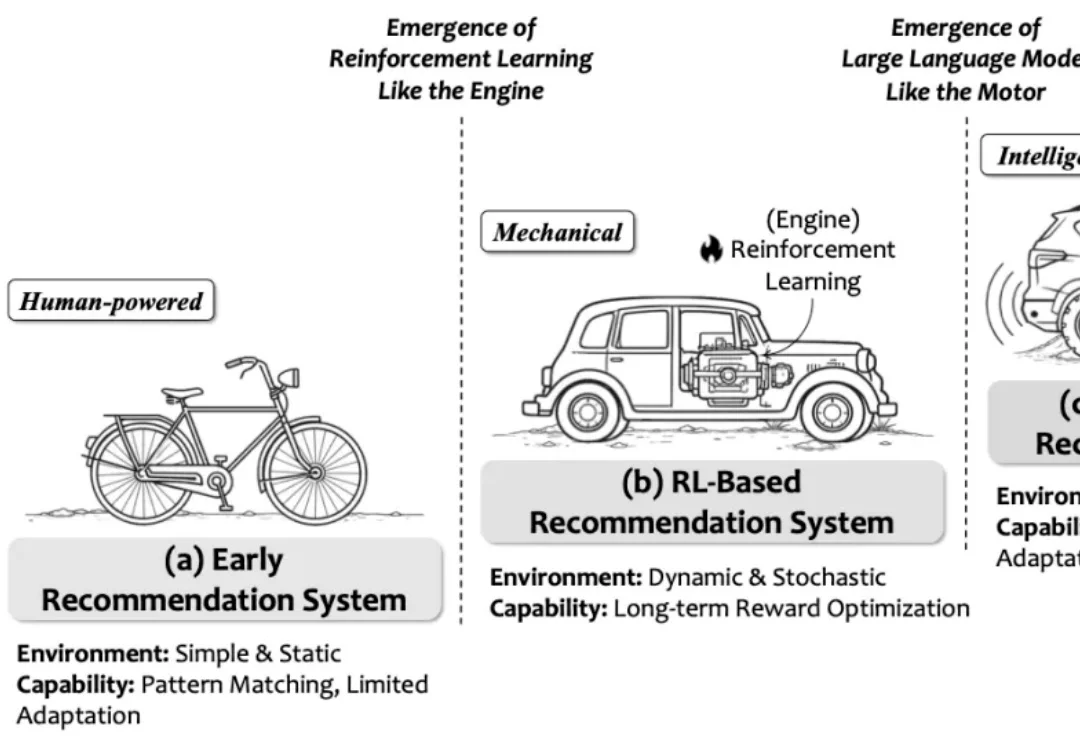
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。
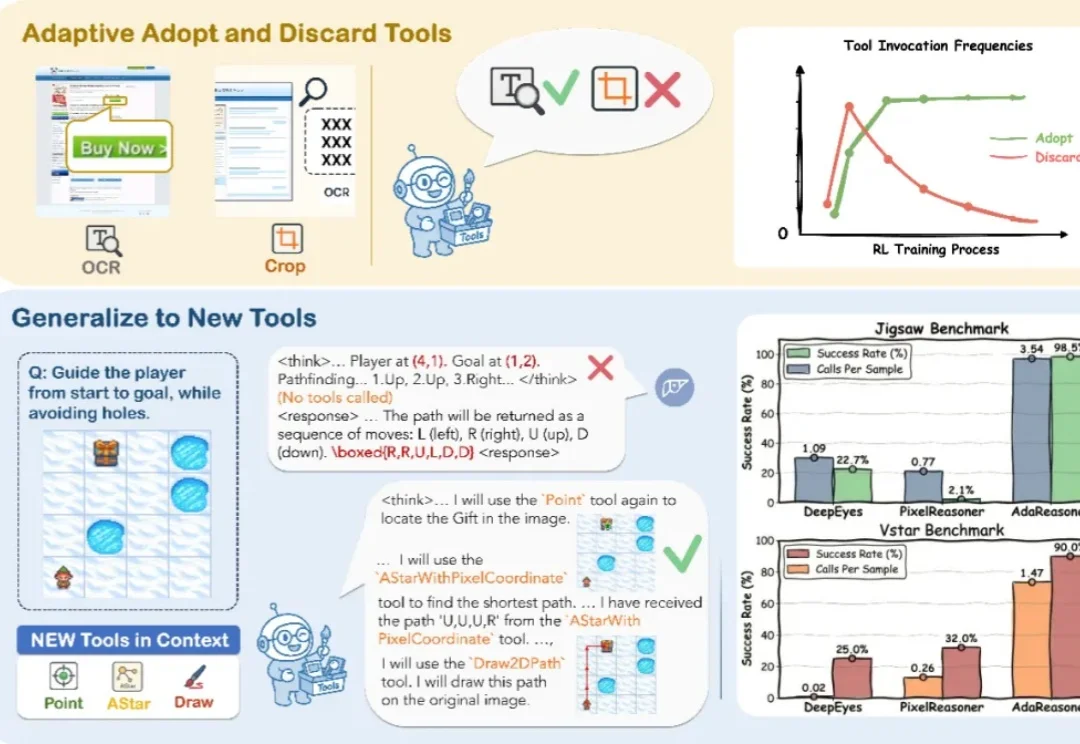
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
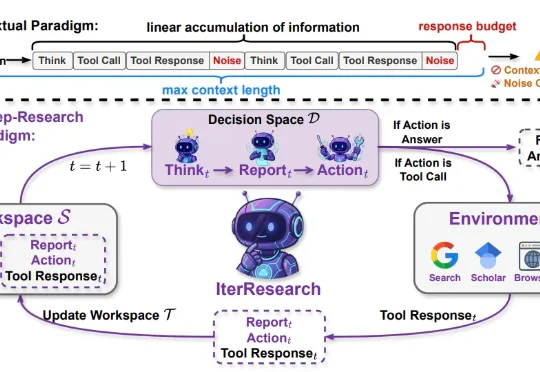
来自中国人民大学与阿里巴巴通义实验室的研究团队提出了 IterResearch,一种全新的迭代式深度研究范式。通过马尔可夫式的工作空间重构,IterResearch 让 Agent 在仅 40K 上下文长度下完成了 2048 次工具交互且性能不衰减,在 BrowseComp 上从 3.5% 一路攀升至 42.5%。
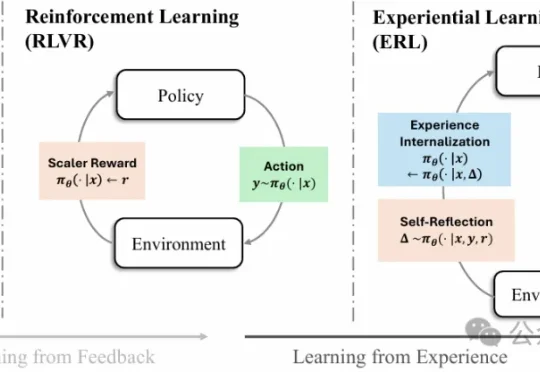
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。
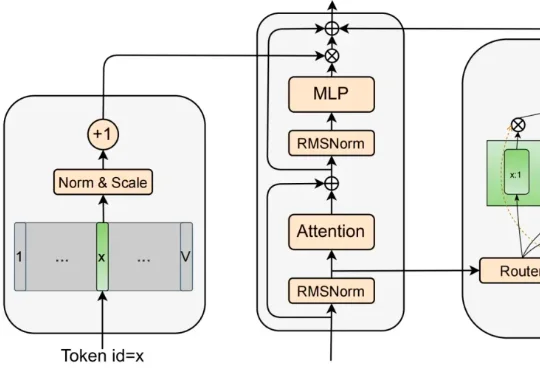
为了松绑参数与计算量,MoE 曾被寄予厚望 。它靠着稀疏激活的专家子网络,在一定程度上实现了模型容量与计算量的解耦 。然而,近期的研究表明,这并非没有代价的免费午餐 :稀疏模型通常具有更低的样本效率 ;随着稀疏度增大,路由负载均衡变得更加困难 ,且巨大的显存开销和通信压力导致其推理吞吐量往往远低于同等激活参数量的 dense 模型 。