ACM MM 2025 | EventVAD:7B参数免训练,视频异常检测新SOTA
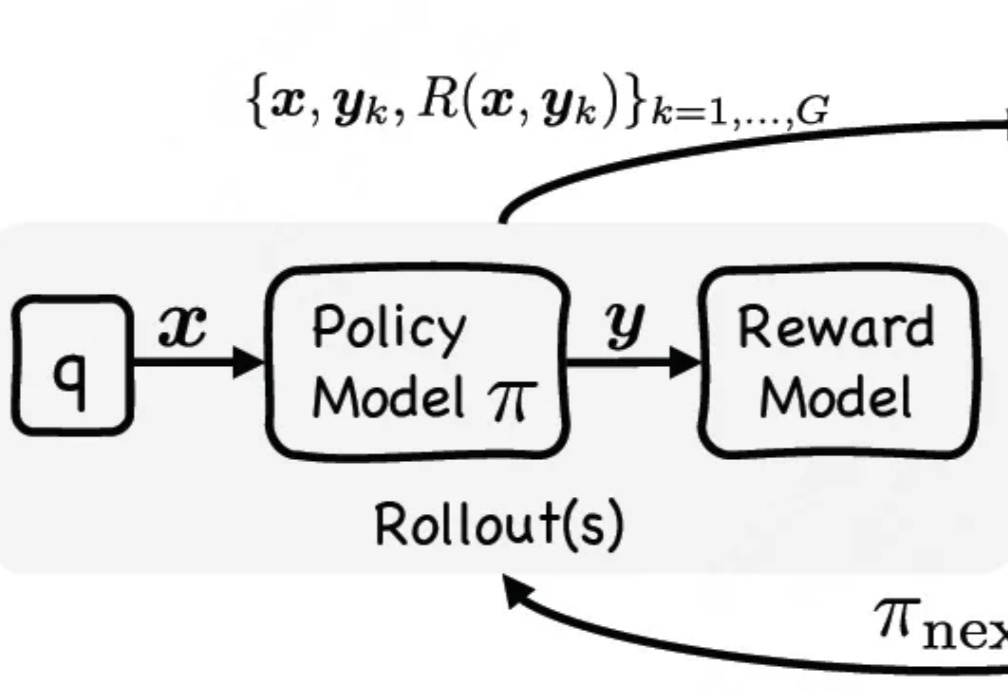
ACM MM 2025 | EventVAD:7B参数免训练,视频异常检测新SOTA现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。
来自主题: AI技术研报
8146 点击 2025-07-21 10:28