Scaling Law没死!Gemini核心大佬爆料,谷歌已有颠覆性密钥
Scaling Law没死!Gemini核心大佬爆料,谷歌已有颠覆性密钥谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!
来自主题: AI资讯
8719 点击 2025-12-20 10:13
 搜索
搜索
谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。

月之暗面最新发布的开源Kimi Linear架构,用一种全新的注意力机制,在相同训练条件下首次超越了全注意力模型。在长上下文任务中,它不仅减少了75%的KV缓存需求,还实现了高达6倍的推理加速。
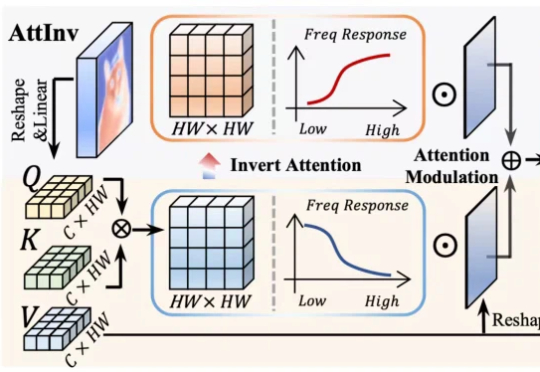
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。
刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
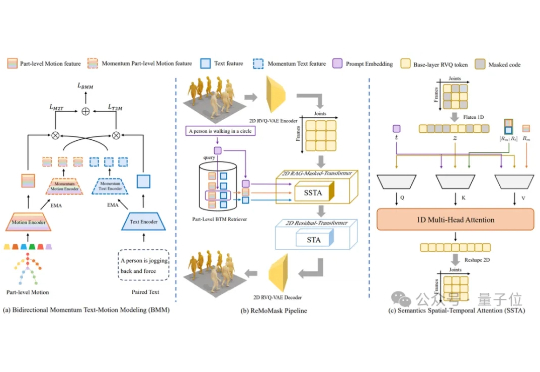
北京大学提出了ReMoMask:一种全新的基于检索增强生成的Text-to-Motion框架。它是一个集成三项关键创新的统一框架:(1)基于动量的双向文本-动作模型,通过动量队列将负样本的尺度与批次大小解耦,显著提高了跨模态检索精度;(2)语义时空注意力机制,在部件级融合过程中强制执行生物力学约束,消除异步伪影;(3)RAG-无分类器引导结合轻微的无条件生成以增强泛化能力。

gpt5来临前夕,oai疑似发布的小模型gpt-oss 120B的架构图已经满天飞了。难得openai要open一次,自然调动了我的全部注意力机制。本来以为oai还要掏出gpt2意思意思,结果看到了一个120B moe。欸?!
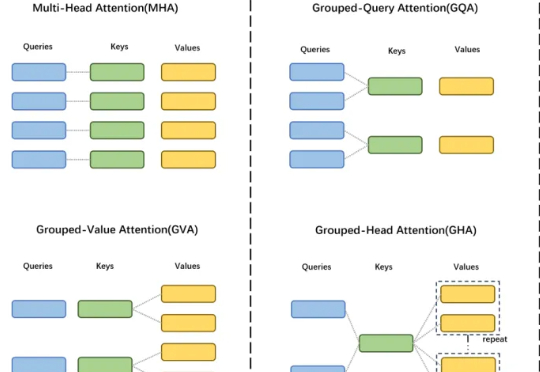
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。