
5亿热钱砸向清华AI Infra明星:最大化算力效能筑造智能体基建
5亿热钱砸向清华AI Infra明星:最大化算力效能筑造智能体基建成立两年半,再添近5亿元A+轮融资—— 截至目前,无问芯穹已累计吸金近15亿,成为AI基础设施领域最受资本追捧的“黑马”企业之一。
来自主题: AI资讯
9002 点击 2025-11-28 10:04
 搜索
搜索
成立两年半,再添近5亿元A+轮融资—— 截至目前,无问芯穹已累计吸金近15亿,成为AI基础设施领域最受资本追捧的“黑马”企业之一。

当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。

前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道《用「传心术」替代「对话」,清华大学联合无问芯穹、港中文等机构提出 Cache-to-Cache 模型通信新范式》。
科幻作家刘慈欣在小说《超新星纪元》中描述了一个令人难忘的场景——几个十几岁的孩子被带到一个小山环绕的地方,他们的面前是一条单轨铁路,上面停着十一列载货火车,每列车有二十节车皮。这些车首尾相接成一个巨大的弧形,根本看不到尽头。这些车中,其中一列装的是味精,另外十列装的是盐。

谷歌AI掌舵人Jeff Dean点赞了一项新研究,还是出自清华姚班校友钟沛林团队之手。Nested Learning嵌套学习,给出了大语言模型灾难性遗忘这一问题的最新答案!简单来说,Nested Learning(下称NL)就是让模型从扁平的计算网,变成像人脑一样有层次、能自我调整的学习系统。
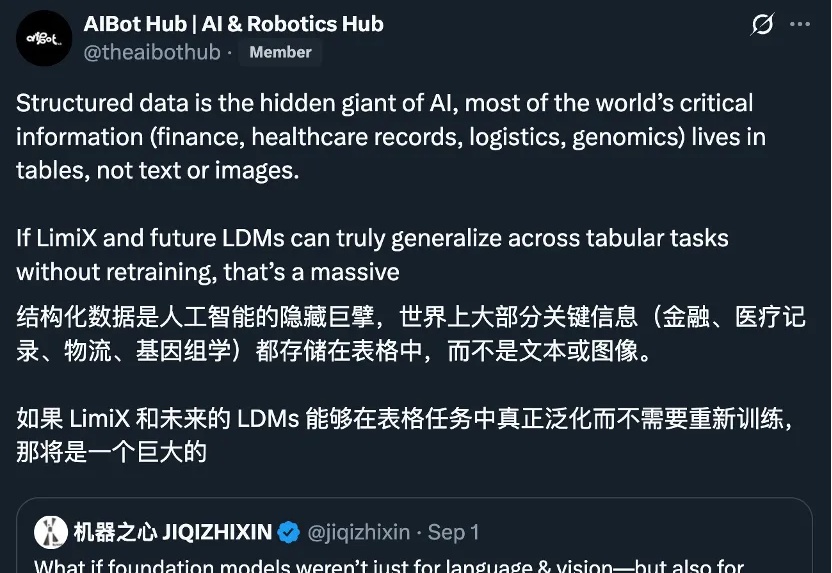
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。
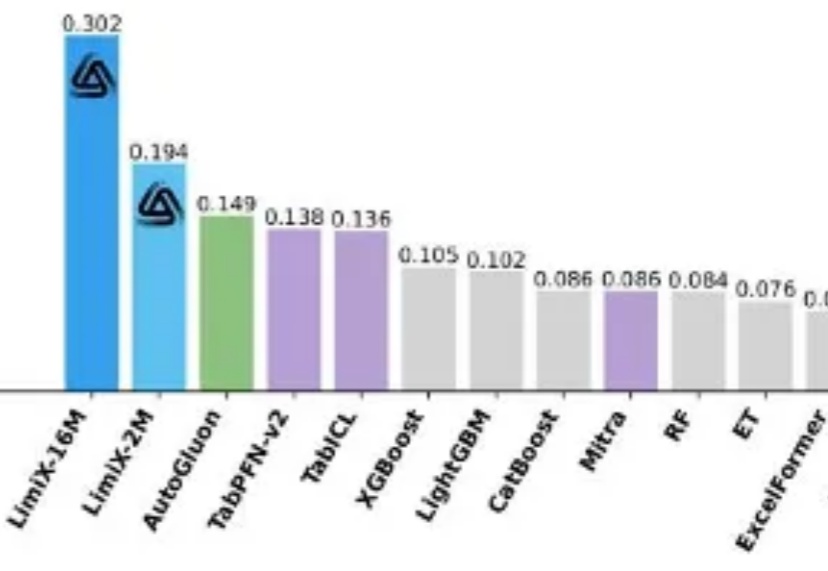
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?

「紫荆智康」日前完成近亿元天使轮融资,由星连资本领投,英诺天使和尚势资本跟投,本轮融资将主要用于紫荆AI医院(Agent Hospital)系统的研发、迭代与升级。紫荆智康成立于2024年9月,由清华大学智能产业研究院(AIR)孵化,清华大学计算机系教授、智能产业研究院执行院长刘洋发起

AI正在以「教育革命」的名义,占领全球校园!清华的新生靠AI助理报到,加州州立大学把52万师生接入ChatGPT Edu,Google更直接向全球学生免费开放Gemini。看似高效的学习浪潮,却在悄悄重写权力格局:谁还在定义「什么叫学会」?当算法成为新的老师,大学的主权,是否已经被温柔地夺走?
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。