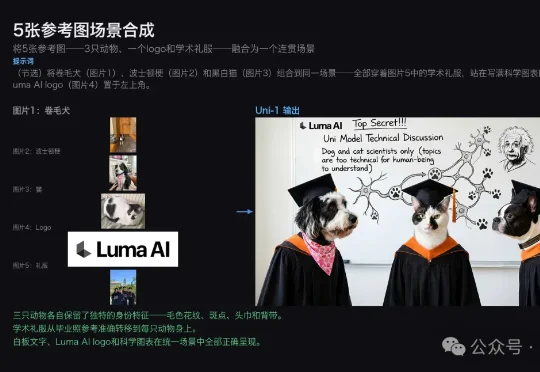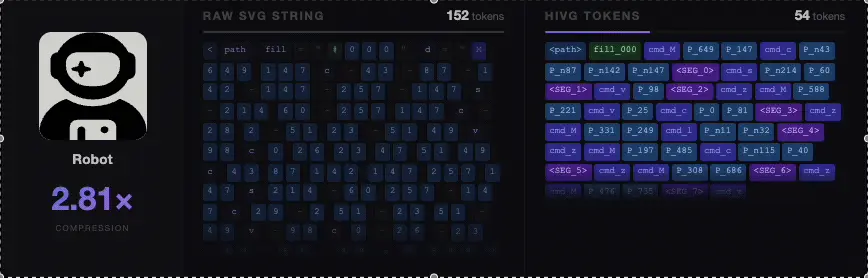
SVG性能比肩GPT/Claude,腾讯开源3B模型HiVG,让Token「懂几何」
SVG性能比肩GPT/Claude,腾讯开源3B模型HiVG,让Token「懂几何」HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。
来自主题: AI资讯
7860 点击 2026-04-10 16:04