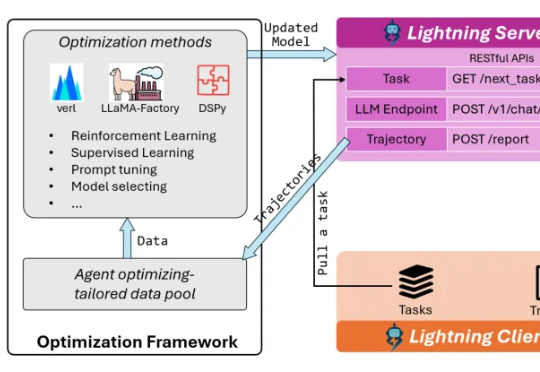
任意Agent皆可强化学习!微软推出Agent Lightning框架,无需修改任何代码
任意Agent皆可强化学习!微软推出Agent Lightning框架,无需修改任何代码AI Agent已逐渐从科幻走进现实!不仅能够执行编写代码、调用工具、进行多轮对话等复杂任务,甚至还可以进行端到端的软件开发,已经在金融、游戏、软件开发等诸多领域落地应用。
来自主题: AI技术研报
9656 点击 2025-10-11 11:44
 搜索
搜索
AI Agent已逐渐从科幻走进现实!不仅能够执行编写代码、调用工具、进行多轮对话等复杂任务,甚至还可以进行端到端的软件开发,已经在金融、游戏、软件开发等诸多领域落地应用。
写代码的规则,正在被悄悄改写!不再是「人+AI一起盯屏幕」,而是一次性放出十几个任务,让代理们各自跑。真正的门槛,也不再是你能写多少行代码,而是你能不能写清楚需求、明确地拆分任务、快速浏览结果。
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。

奇多多AI学伴机是由无界方舟发布的国内首款基于「端到端实时多模态互动模型」的AI互动机器人,于本月2025外滩大会首次亮相。京东预售仅上线一周,销量便突破了10000台,在看似红海的儿童早教市场掀起波澜。在功能体验方面,它带来了三大突破:能“看”世界的眼睛、堪比真人的低延迟反馈速度、能“成长”的个性化陪伴感。
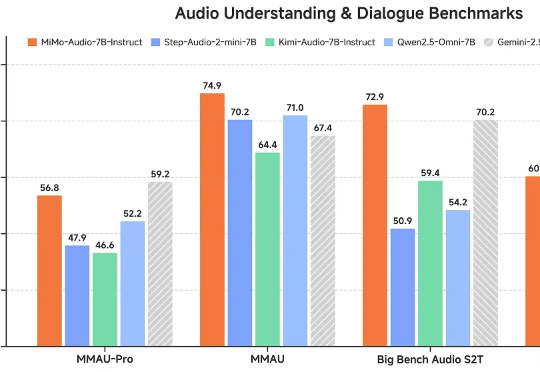
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
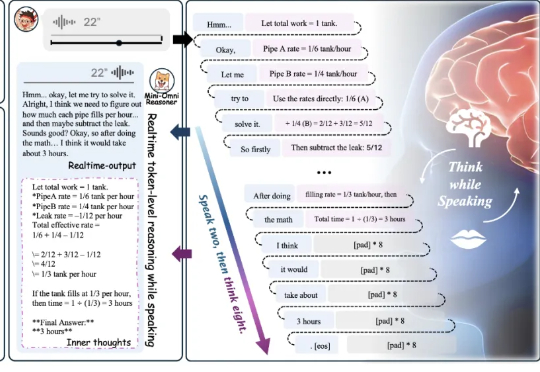
基于这一挑战,我们提出了 Mini-Omni-Reasoner——一种专为对话场景打造的实时推理新范式。它通过「Thinking-in-Speaking」实现边思考边表达,既能实时反馈、输出自然流畅的语音内容,又能保持高质量且可解释的推理过程。

智东西9月15日报道,今天,阿里巴巴通义实验室推出了FunAudio-ASR端到端语音识别大模型。这款模型通过创新的Context模块,针对性优化了“幻觉”、“串语种”等关键问题,在高噪声的场景下,幻觉率从78.5%下降至10.7%,下降幅度接近70%。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。
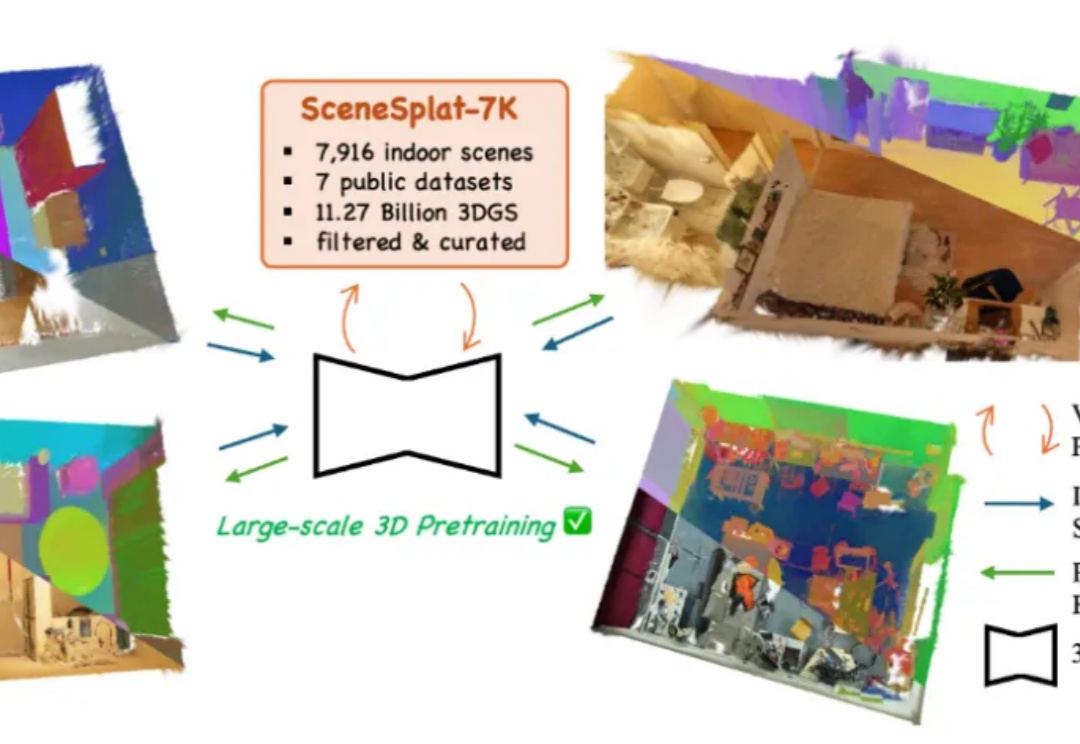
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。

虽然大家都期待未来的 Agent 能够真正端到端完成所有任务,并且在出错时也知道如何重新开始,但目前 AI 还没有达到这种能力。