
别跟风买Mac Mini了!国产算力跑OpenClaw,只需5分钟
别跟风买Mac Mini了!国产算力跑OpenClaw,只需5分钟Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!
来自主题: AI资讯
12203 点击 2026-02-03 16:14
 搜索
搜索
Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!

为了给OpenAI凑齐3000亿美金的算力投名状,硅谷老教父Larry Ellison杀疯了!3万名员工集体祭天,283亿美金买回来的医疗巨头Cerner直接送上拍卖台。为了买显卡,甲骨文正在自残?
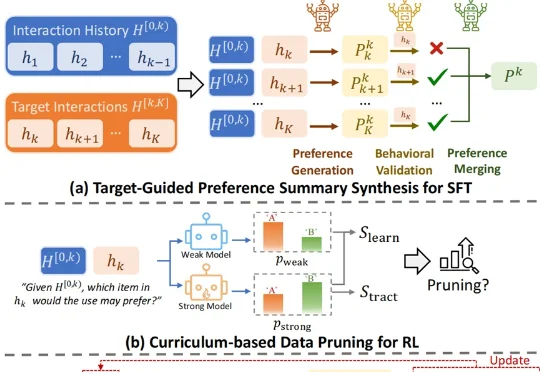
怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
国产算力基建跑了这么多年,大家最关心的逻辑一直没变:芯片够不够多?但对开发者来说,真正扎心的问题其实是:好不好使?
中国算力的增长新范式。

过去一年,AI 技术已从概念热潮深度渗透至产业肌理,成为驱动 IT 基础设施重构的核心引擎。当大模型、异构算力、智能体(Agent)等技术要素持续冲击传统技术体系,操作系统作为软硬件协同的核心枢纽,其 AI 进化的本质也引发了行业的深刻思考:OS 的 AI 进化,究竟是换汤不换药的 “新瓶旧酒”,还是颠覆底层逻辑的 “涅槃重生”?

岁末年初,全球AI竞争聚焦到了最新趋势—— 太空算力。

过去一整年,具身智能成了 AI 行业里最被反复提及、却最难真正落地的方向。一边是人形机器人发布会密集登场,另一边却始终缺乏可规模部署的现实成果。算法在进步,算力在堆叠,但问题始终没有改变:机器人到底该如何被教会在真实世界中行动。

斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
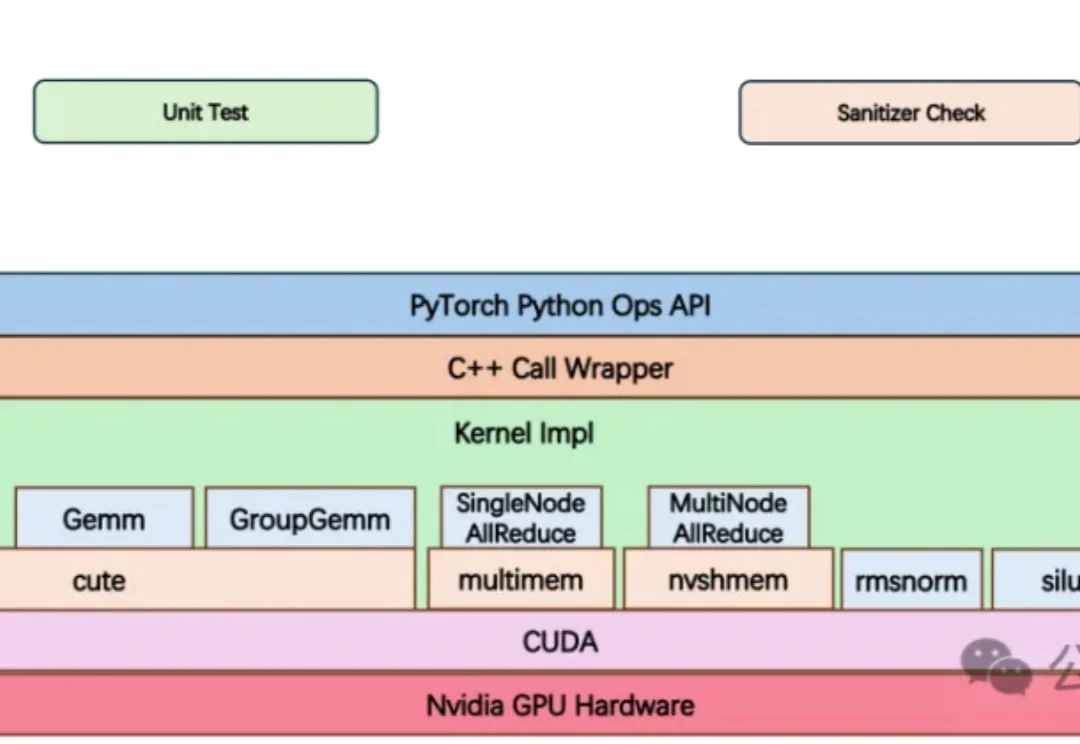
大模型竞赛中,算力不再只是堆显卡,更是抢效率。