马斯克刚关注了这份AI报告
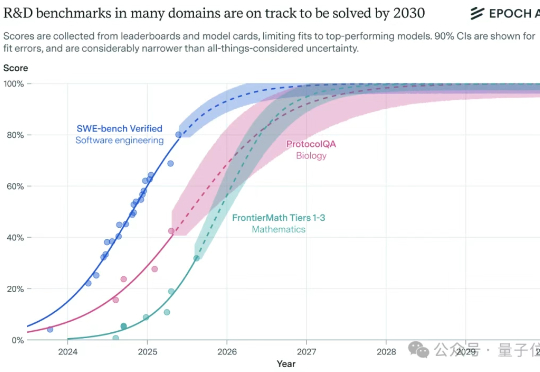
马斯克刚关注了这份AI报告2030年的人工智能将会是什么样子?受谷歌DeepMind委托,Epoch发布新报告,从算力、数据、收入等方面进行了详细剖析。
来自主题: AI技术研报
10036 点击 2025-09-25 14:53
 搜索
搜索
2030年的人工智能将会是什么样子?受谷歌DeepMind委托,Epoch发布新报告,从算力、数据、收入等方面进行了详细剖析。
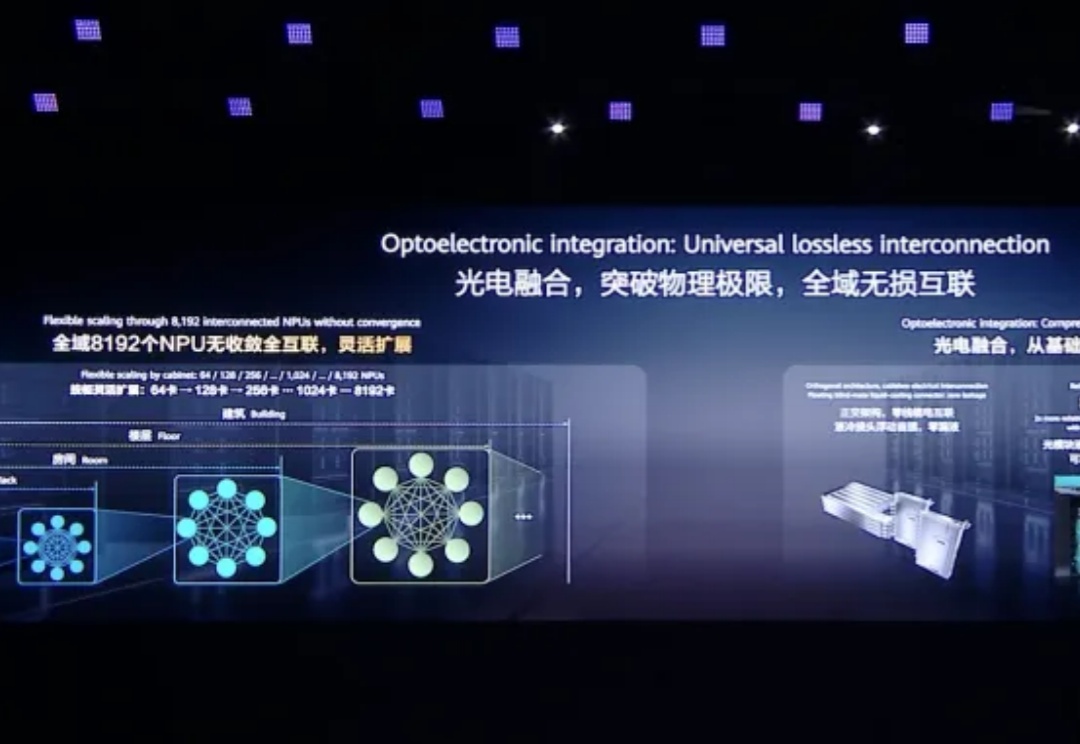
上周,华为全联接大会集中展示了华为最新最强的一系列创新。

如果说云计算市场的上半场比的是谁胆子大、折扣狠,那么下半场则要拼的是谁口袋深、生态牢,任何战略摇摆都可能被直接踢出牌桌。

英伟达刚刚计划给OpenAI一千万美元新投资,OpenAI就宣布了钱的用法:将和甲骨文及软银合作建数据中心,而且一口气就是五个。

AGI时代或将带来前所未有的繁荣:算力推动经济狂飙,但人类工资却被钉死在「算力成本」上,与增长彻底脱钩。耶鲁学者Restrepo的研究指出,劳动份额将归零,财富全面流向算力资本。人类或许仍被需要,却只停留在护理、陪伴等附属岗位。在这样的未来,工作还有意义吗?

继英伟达千亿投资OpenAI之后,「星际之门」立即官宣新增五个站点,预计年底前达成10GW目标。奥特曼发文称,目标打造一个每周GW级「AI工厂」,AI无限算力或将治愈癌症。

在AI热潮中,大模型最「渴求」的究竟是什么?是算力、是存储,还是复杂的网络互联?在Hot Chips 2025 上,Transformer发明者之一、谷歌Gemini联合负责人Noam Shazeer给出了答案。
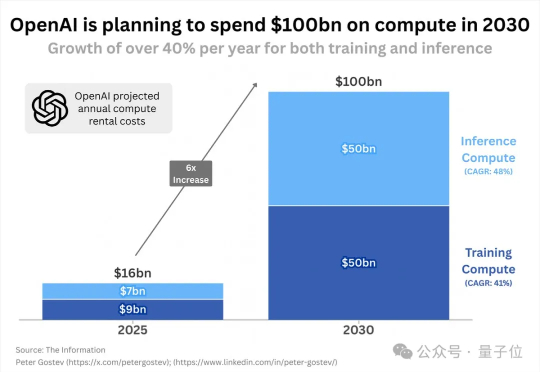
OpenAI已经花了160亿美元(约人民币1138亿)租用计算资源。相当于每天一睁眼,就有几千万花出去租服务器。但这还不是最夸张的。据The Information消息,OpenAI计划在未来五年额外支出约1000亿美元,用于从云服务提供商处租用备用服务器 。

没有永恒的同盟,只有永恒的资本和利益

AI浪潮席卷全球,金融行业正迎来深刻变革。华为以全栈技术为依托,携手金融机构打造高效算力底座,重磅发布「金融智能体加速器FAB」,让AI智能体加速在金融落地生根。