视觉模型既懂语义,又能还原细节,南洋理工&商汤提出棱镜假说
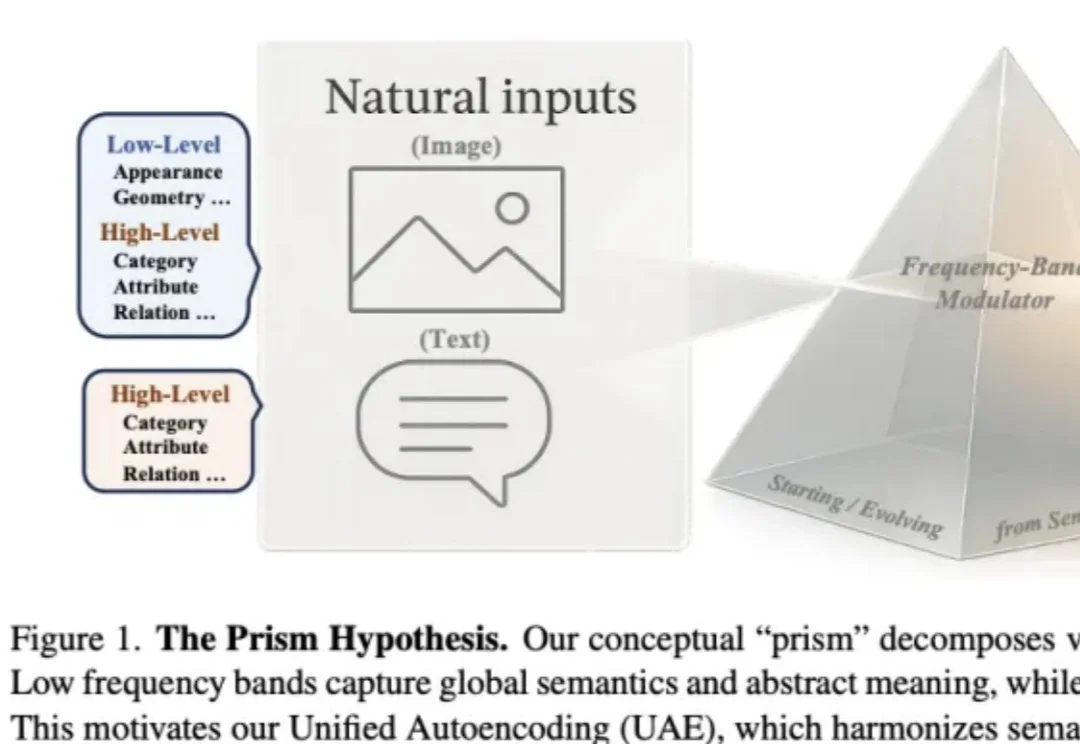
视觉模型既懂语义,又能还原细节,南洋理工&商汤提出棱镜假说作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
来自主题: AI技术研报
11078 点击 2026-01-15 09:20