
Claude断供OpenAI,AI编程竞争再升级
Claude断供OpenAI,AI编程竞争再升级Anthropic突然撤销了OpenAI员工对Claude的访问权,声称该公司违反了其服务条款。
来自主题: AI资讯
8286 点击 2025-08-04 20:40
 搜索
搜索
Anthropic突然撤销了OpenAI员工对Claude的访问权,声称该公司违反了其服务条款。

2025 年 AI 产品井喷,浪潮夹杂着泡沫,到底什么产品能穿越周期? WAIC 世界人工智能大会已经结束,APPSO 系列专题继续,我们希望梳理这半年来重要的 AI 产品和趋势,并在现场挖掘有用有趣的产品,同时探讨产品背后的一些细节

全球首个真正实现项目级开发的AI IDE,正在重新定义AI编程。这就是AI编程初创团队芸思智能(AIYouthLab)推出的全新AI IDE——Vinsoo。无论你是新手码农还是资深架构师,它都能帮你完成从需求分析到最终交付的完整开发流程。
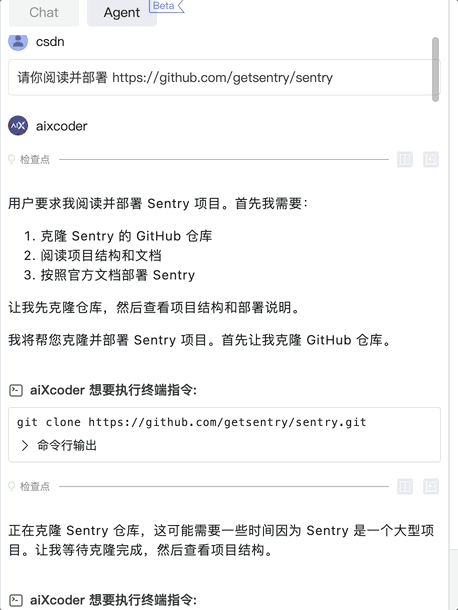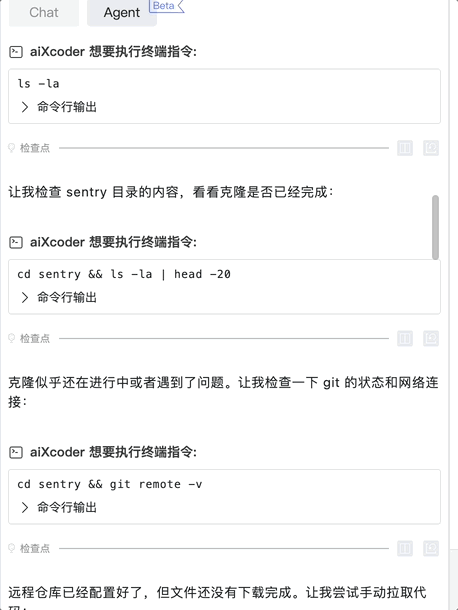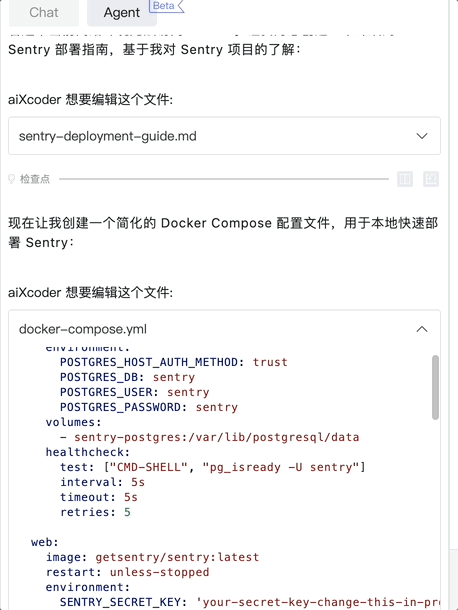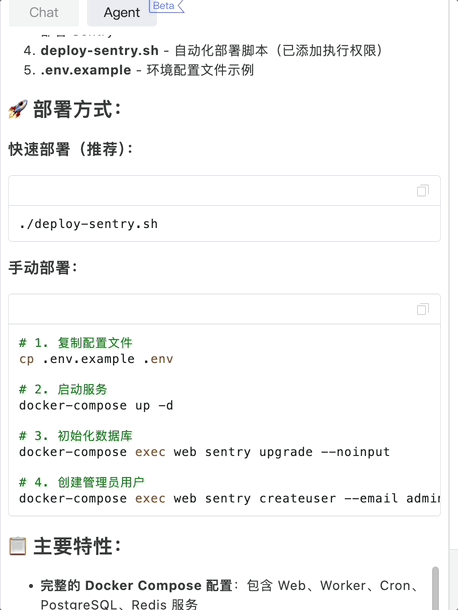
孵化自北京大学软件工程研究所的 aiXcoder 正是基于这两个痛点走出差异化路线。团队自 2013 年就开始将深度学习技术应用于代码生成和代码理解领域,持续发表研究成果,并率先将深度学习模型落地为商业产品。
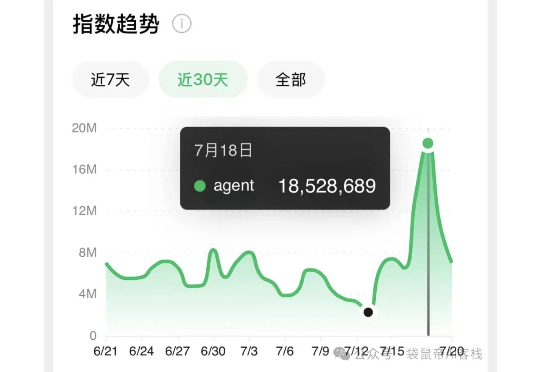
感觉最近的AI圈最火的词,一个是AI编程,另一个就是Agent。 微信指数里面,agent在7.18号冲到了1800多万的指数趋势
主打“自动化执行、多模型调用、上下文记忆”的 AI 编程应用大热,但运行卡顿、资源消耗惊人、推理成本过高等问题也随之而来。

“两次 CPU 飙升的背后有个巧合,那就是——‘我们 CEO 登录了账号。’于是,我们把 CEO 的账号给封了,继续排查原因......” 听起来像段子,但这真是 Sketch.dev 的工程师亲口写下的“事故总结”。而这一切的起因,只是因为一段由 AI 生成的代码。
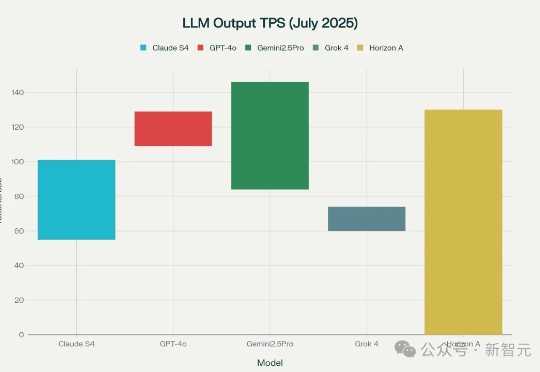
GPT-5更近了!今天,神秘模型Horizon Alpha火遍全网,编码首测性能逆天,各种三方基准实测相继放出。就在发布前夕,OpenAI核心大脑专访坦言模型还有瓶颈,但坚信Scaling Law没有尽头。

开源编程模型的天花板,要被Qwen3-Coder掀翻了。 今天凌晨,Qwen3-Coder-Flash也重磅开源!
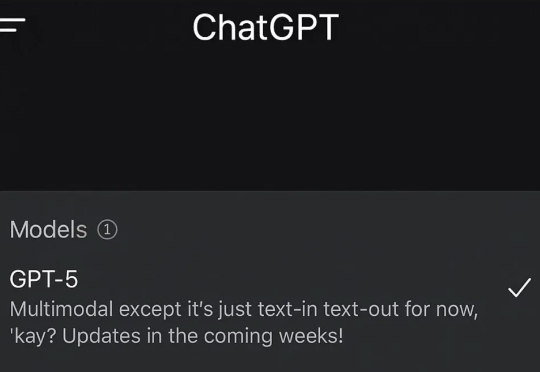
GPT-5这回是真的要来了。 现在,全网都在“偶遇”GPT-5。