
老黄预言成真!全球首个AI原生游戏引擎,一句话秒出GTA级神作
老黄预言成真!全球首个AI原生游戏引擎,一句话秒出GTA级神作谁曾想,AI竟能实时生成GTA级大作。刚刚,谷歌、英伟达等机构联手,震撼发布全球首款AI原生UGC游戏引擎——Mirage,没有预设关卡,一句话即生游戏,超长十分钟沉浸式体验
来自主题: AI资讯
10510 点击 2025-07-03 14:19
 搜索
搜索
谁曾想,AI竟能实时生成GTA级大作。刚刚,谷歌、英伟达等机构联手,震撼发布全球首款AI原生UGC游戏引擎——Mirage,没有预设关卡,一句话即生游戏,超长十分钟沉浸式体验

老黄惊喜现身,与95后清华校友合影曝光,确认Banghua Zhu加入Star Nemotron团队,专注企业级智能体研发。同时Jiantao Jiao官宣入职英伟达。两人曾联合创办Nexusflow。
据路透社等多家媒体报道,一位知情人士称,OpenAI 最近开始租用谷歌的 AI 芯片来支持 ChatGPT 及其其他产品。 现目前,OpenAI 是英伟达 GPU 的最大买家之一 —— 这些设备在 AI 大模型的训练和推理阶段都必不可少。 看起来,OpenAI 不仅试图远离微软,现在也在开始远离英伟达了。

现实版的「一人得道」!AI云服务商CoreWeave上市3个月后,CEO赚麻了,直接跻身全球顶级富豪榜Top 500。暴富速度,史上第二!这轮涨势也带动了其他几位联合创始人「一夜暴富」:首席战略官Brian Venturo目前资产达64亿美元,首席开发官Brannin McBee的身家则为47亿美元。

全网翘首以盼的DeepSeek-R2,再次被曝推迟!据The Information报道,由于DeepSeek CEO梁文锋始终对R2的表现不满意,因此R2迟迟未能发布。此外,他们还援引两位国内知情人士的消息称,R2研发进程缓慢可能是由于缺少英伟达H20芯片。
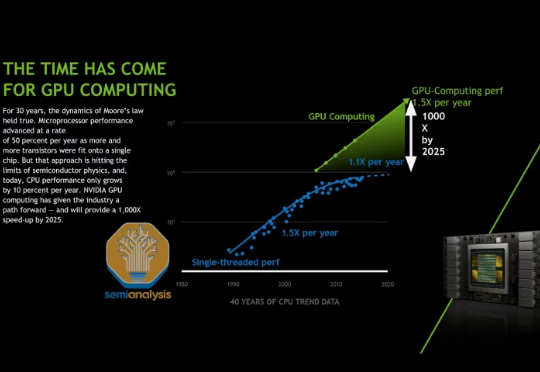
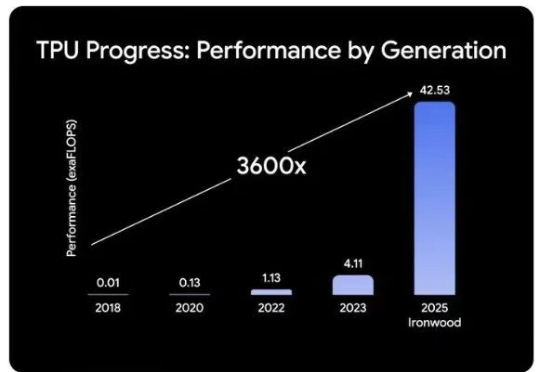
在我们去年 AI Scaling Laws article from late last year中,我们探讨了多层 AI 扩展定律如何持续推动 AI 行业向前发展,使得模型能力的增长速度超过了摩尔定律,并且单位 token 成本也相应地迅速降低。
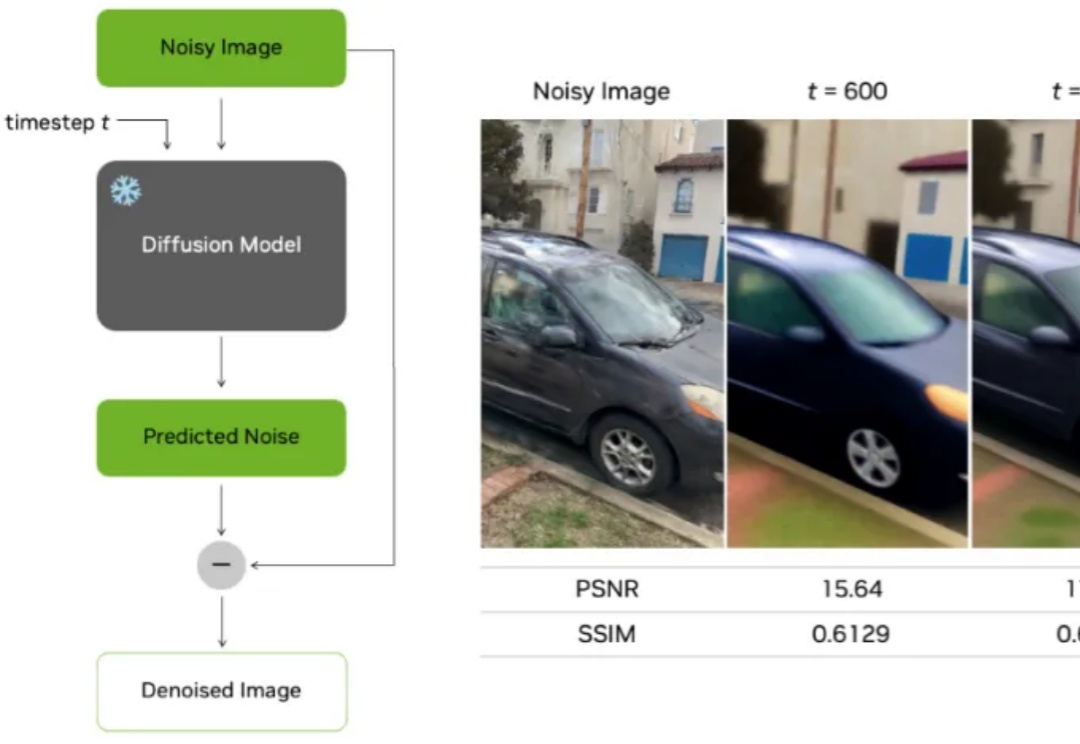
在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
在 AI 领域,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。

据媒体报道,两位知情人士透露,英伟达正在与富士康洽谈,计划在美国得州休斯敦的一座新工厂内部署人形机器人,该工厂将用于生产英伟达的AI服务器。消息人士称,这将是英伟达产品首次在生产线上由人形机器人协助下制造,同时也有望是富士康首座在生产线上使用人形机器人进行生产的AI服务器工厂。