
英特尔Ultra 200V处理器来了,全力押注AI赛道、剑指苹果英伟达
英特尔Ultra 200V处理器来了,全力押注AI赛道、剑指苹果英伟达这可能是能效表现最好的 x86 处理器。
来自主题: AI资讯
8012 点击 2024-09-05 15:06
 搜索
搜索
这可能是能效表现最好的 x86 处理器。
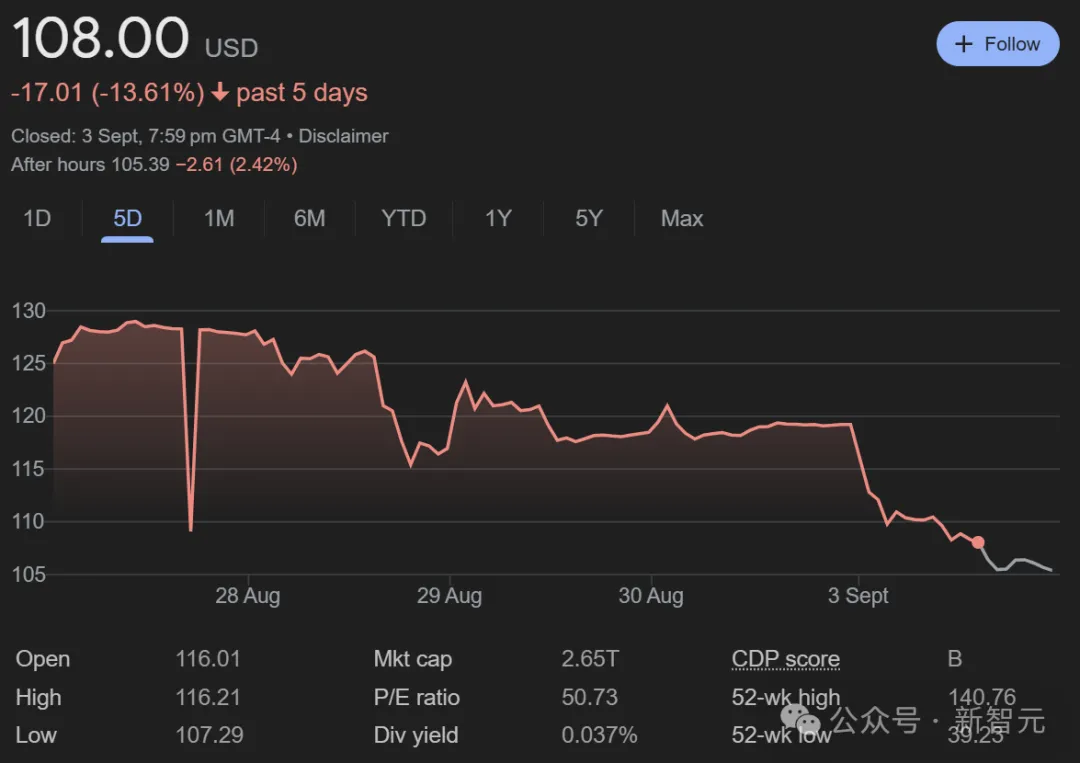
英伟达市值,一夜蒸发2790亿美元,创下美股史上单日最大跌幅!一天的损失,都赶上卖出的所有AI芯片了。「打倒英伟达垄断」的汹涌民意,终于有了具象化的一天。同时,英伟达已收到美国司法部传票,可谓噩耗连连。

“过去的几周很艰难,我们决定明确展示公司现状,但市场反应并不积极。”

吴甘沙校友本硕毕业于复旦大学计算机科学技术学院,于2000年加入英特尔中国研究院,2010年成为英特尔中国研究院首席工程师,2014年晋升成为英特尔中国研究院院长。2016年,他创立驭势科技,踏上创业之路已有8年时光。

老牌芯片巨头英特尔,再失一位半导体行业老将。最近,陈立武宣布辞去董事会一职,因对公司官僚主义、规避风险文化感到沮丧,并在中层裁员意见上出现分歧。消息一出公司股价暴跌6%,现如今市值不过千亿美金。

智东西8月28日消息,据路透社报道,因在公司代工业务发展方向上,与英特尔高层存在分歧,半导体行业资深人士陈立武上周主动辞去其董事会职务。

MICRO 全称 IEEE/ACM International Symposium on Microarchitecture,与 ISCA、HPCA、ASPLOS 并称为体系结构「四大顶会」,囊括了当年最先进的体系结构成果,被视作国际前沿体系结构研究的风向标,见证了诸多突破性成果的首次亮相,包括谷歌、英特尔、英伟达等企业在半导体领域的多项技术创新。

一场未完成的投资改变了什么?

英特尔用“光”,突破了大模型时代棘手的算力难题—— 推出业界首款全集成OCI(光学计算互连)芯片。

为期三天的2024年台北电脑展(Computex 2024),6月7日已落下帷幕。在这一次的展会上,AI成为贯穿一切的主题。英伟达、AMD、英特尔、高通等芯片大厂的话事人们纷纷做了主题演讲,也让这次展会的参与人数比上一届暴涨了 80%。