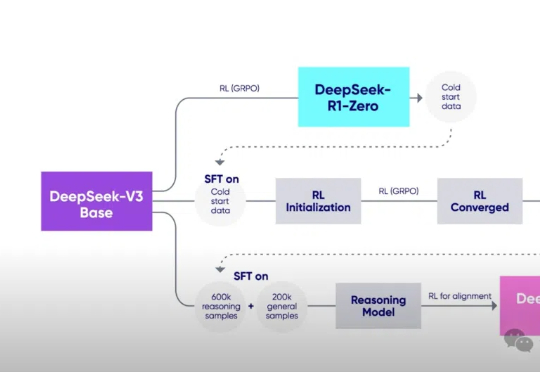
强化学习被高估!清华上交:RL不能提升推理能力,新知识得靠蒸馏
强化学习被高估!清华上交:RL不能提升推理能力,新知识得靠蒸馏一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
来自主题: AI技术研报
8487 点击 2025-04-28 16:51
 搜索
搜索
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
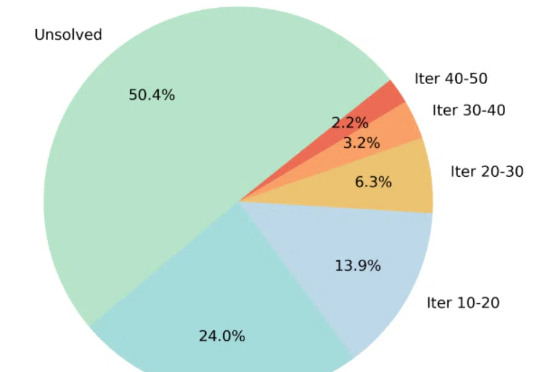
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。

4 月 14 日,谷歌首席科学家 Jeff Dean 在苏黎世联邦理工学院举办的信息学研讨会上发表了一场演讲,主题为「AI 的重要趋势:我们是如何走到今天的,我们现在能做什么,以及我们如何塑造 AI 的未来?」
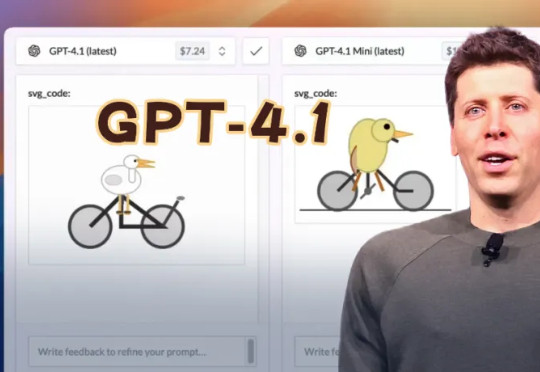
两个月后就号称要淘汰GPT-4.5的GPT-4.1,实力究竟如何?在众多实测中,它的表现的确可圈可点,但却依然打不过Gemini 2.5 Pro和Claude 3.7 Sonnet。那么问题来了,OpenAI为何要发布一个远远落后于谷歌的模型?
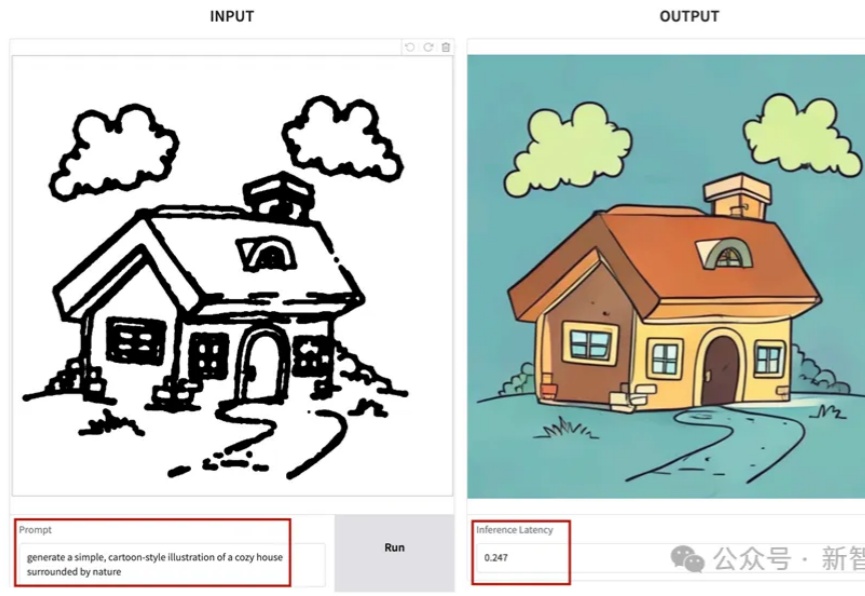
SANA-Sprint是一个高效的蒸馏扩散模型,专为超快速文本到图像生成而设计。通过结合连续时间一致性蒸馏(sCM)和潜空间对抗蒸馏(LADD)的混合蒸馏策略,SANA-Sprint在一步内实现了7.59 FID和0.74 GenEval的最先进性能。SANA-Sprint仅需0.1秒即可在H100上生成高质量的1024x1024图像,在速度和质量的权衡方面树立了新的标杆。

张林峰于2019年提出了自蒸馏算法,是知识蒸馏领域的代表性工作之一。DeepSeek出现后,知识蒸馏领域再次获得了极大的关注。

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。

见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
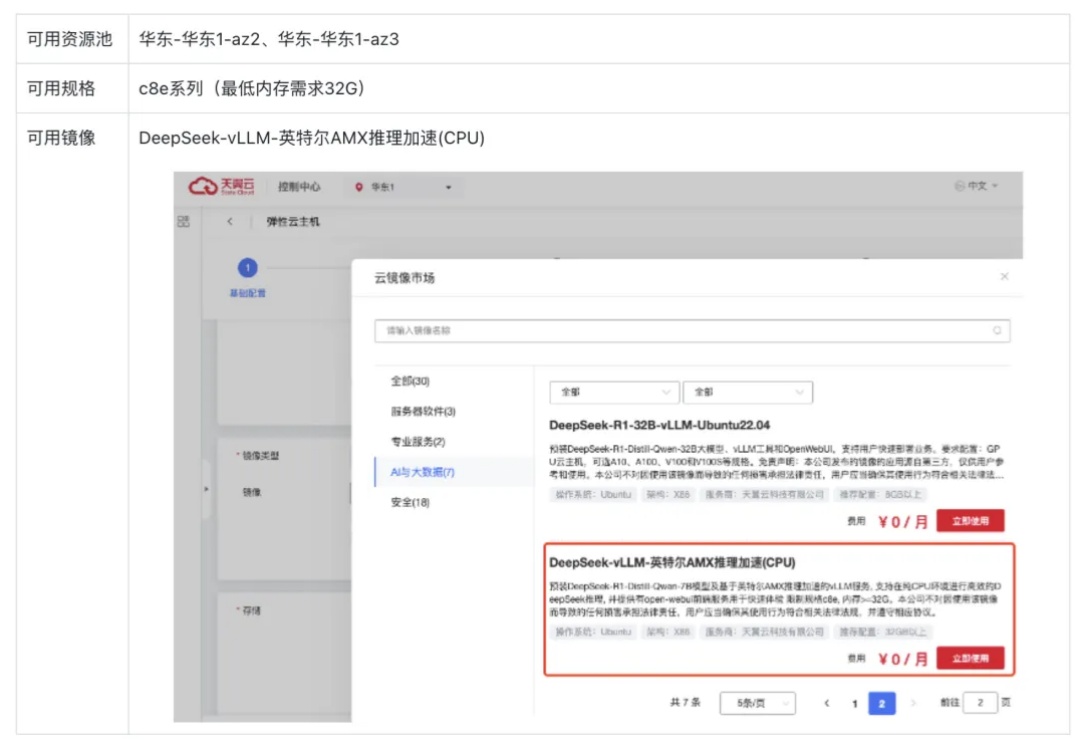
本文介绍了英特尔®至强®处理器在AI推理领域的优势,如何使用一键部署的镜像进行纯CPU环境下基于AMX加速后的DeepSeek-R1 7B蒸馏模型推理,以及纯CPU环境下部署DeepSeek-R1 671B满血版模型实践。

单目深度估计新成果来了!西湖大学AGI实验室等提出了一种创新性的蒸馏算法,成功整合了多个开源单目深度估计模型的优势。在仅使用2万张无标签数据的情况下,该方法显著提升了估计精度,并刷新了单目深度估计的最新SOTA性能。