
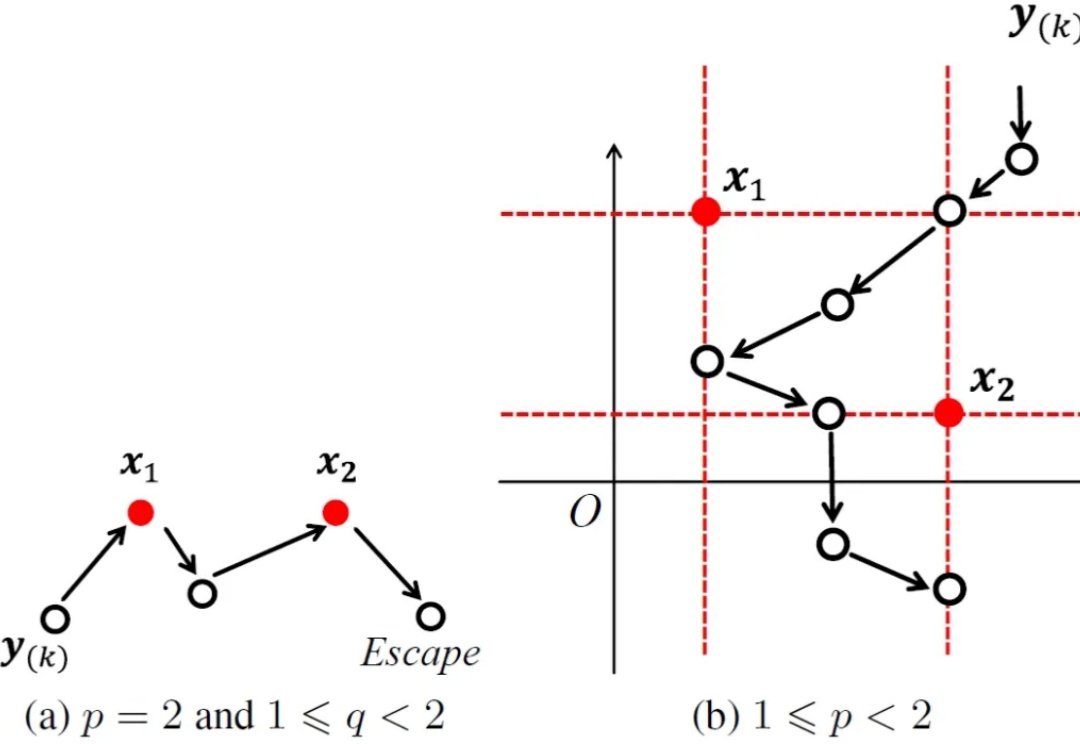
AAAI 2025 | 用于韦伯区位问题的去奇异性次梯度方法
AAAI 2025 | 用于韦伯区位问题的去奇异性次梯度方法韦伯区位问题源自一个经典的运筹优化问题,它首先由著名数学家皮耶・德・费马提出,后被著名经济学家阿尔弗雷德・韦伯(著名社会学家马克斯・韦伯的弟弟)扩展,在机器学习、人工智能、金融工程及计算机视觉等众多领域均有广泛应用。
来自主题: AI技术研报
6415 点击 2024-12-30 13:45
韦伯区位问题源自一个经典的运筹优化问题,它首先由著名数学家皮耶・德・费马提出,后被著名经济学家阿尔弗雷德・韦伯(著名社会学家马克斯・韦伯的弟弟)扩展,在机器学习、人工智能、金融工程及计算机视觉等众多领域均有广泛应用。
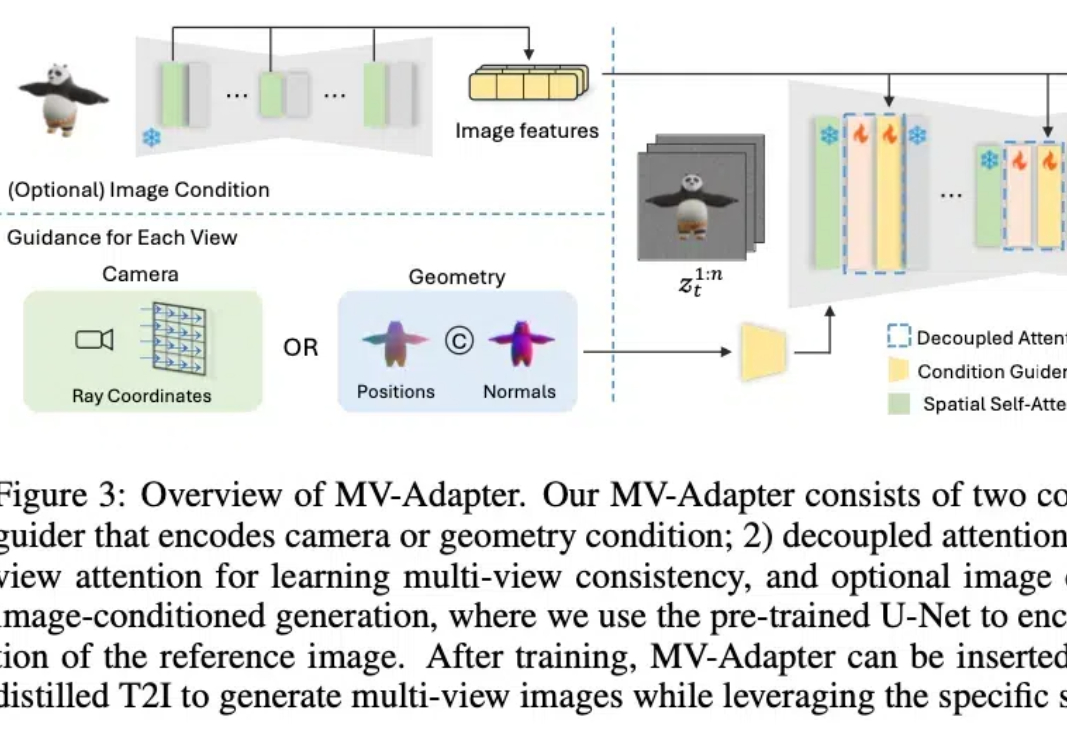
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。

作为计算机视觉领域的开拓者,李飞飞在人工智能革命中扮演了重要角色。她的新回忆录《我所看到的世界》(The Worlds I See)详细讲述了她从学术到技术突破的旅程,以及如何在人工智能的最前沿找到自己的使命。
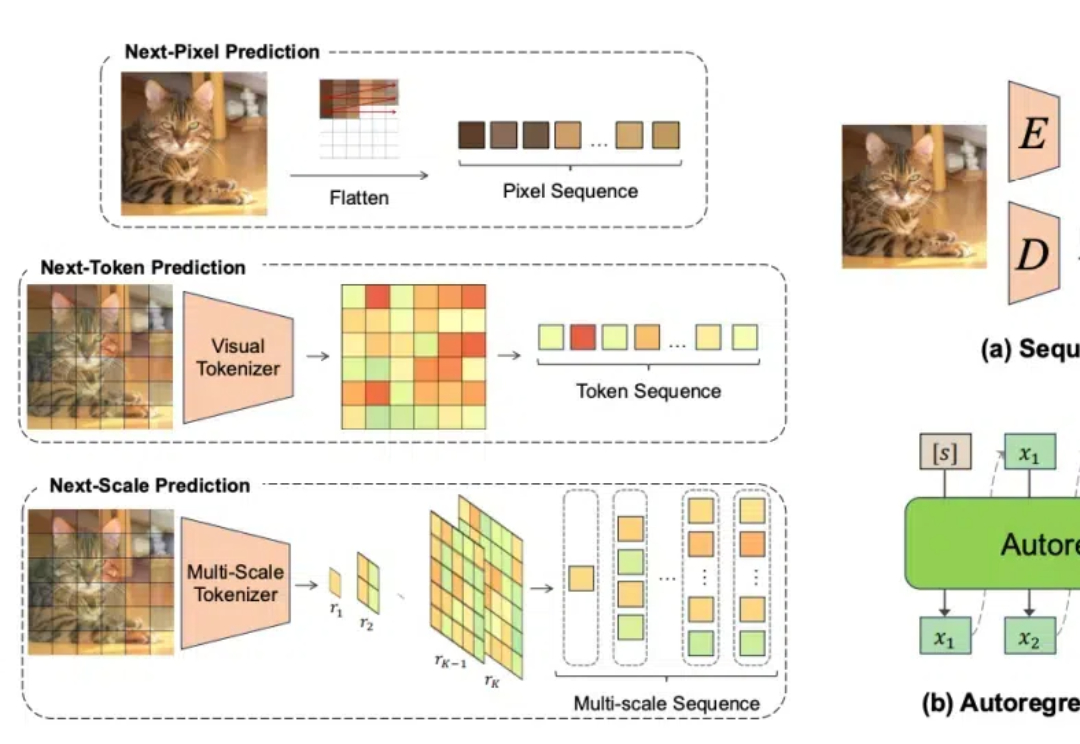
随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。

近年来,AI for Science 发展提速,不仅为科研领域带来创新研究思路,同时也拓宽了 AI 的落地通路,为其提供了更多具有挑战性的应用场景。在这个过程中,越来越多的 AI 领域研究人员开始关注医疗、材料、生物等传统科研领域,探索其中的研究难点与行业挑战。

计算机视觉(Computer Vision)的工作原理与人类视觉类似,但需要机器依靠摄像头、数据和算法在很短的时间内完成任务。

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。

作为A股第一家AI计算机视觉上市公司,格灵深瞳在多个人工智能细分应用领域中较早完成了产品布局,目前尚处于产业化与市场拓展的发展阶段,未来能否在新应用领域实现业务拓展,将成为企业“生死存亡”的关键。

张大鹏,加拿大皇家科学院院士,加拿大工程院院士,国际电气与电子工程师协会终身会士(IEEE Fellow),国际模式识别协会会士,亚太人工智能学会会士,香港中文大学(深圳)数据科学学院校长学勤讲座教授,深圳市人工智能与机器人研究院(AIRS)计算机视觉研究中心主任,香港中文大学(深圳)—联易融计算机视觉与人工智能联合实验室主任,以及香港理工大学荣誉教授。

论文共同第一作者郑淼,来自于周泽南领导的百川对齐团队,毕业于北京大学,研究方向包括大语言模型、多模态学习以及计算机视觉等,曾主导MMFlow等开源项目。