
一个模型装下整个物种树!伯克利GPN-Star斩获基因预测双料冠军
一个模型装下整个物种树!伯克利GPN-Star斩获基因预测双料冠军加州大学伯克利分校等机构的研究人员,近日推出了一种全新的基因组语言模型GPN-Star,可以将全基因组比对和物种树信息装进大模型,在人类基因变异预测方面达到了当前最先进的水平。
来自主题: AI技术研报
10986 点击 2025-10-16 12:19
 搜索
搜索
加州大学伯克利分校等机构的研究人员,近日推出了一种全新的基因组语言模型GPN-Star,可以将全基因组比对和物种树信息装进大模型,在人类基因变异预测方面达到了当前最先进的水平。
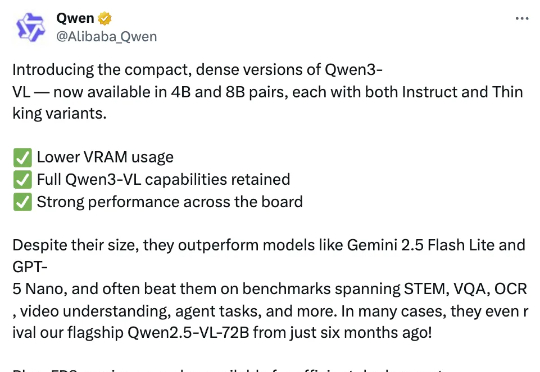
智东西10月15日报道,今日,阿里通义千问团队推出其最强视觉语言模型系列Qwen3-VL的4B与8B版本,两个尺寸均提供Instruct与Thinking版本,在几十项权威基准测评中超越Gemini 2.5 Flash Lite、GPT-5 Nano等同级别顶尖模型。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
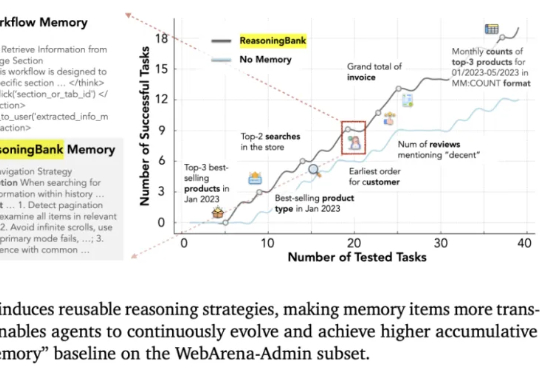
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
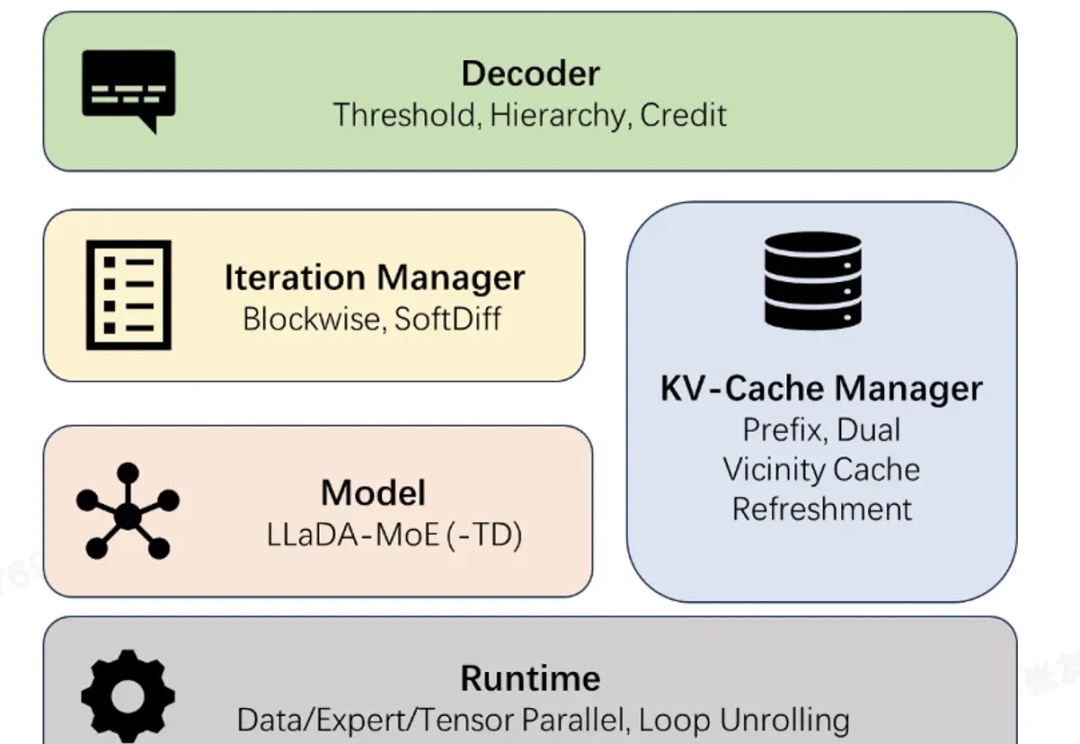
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
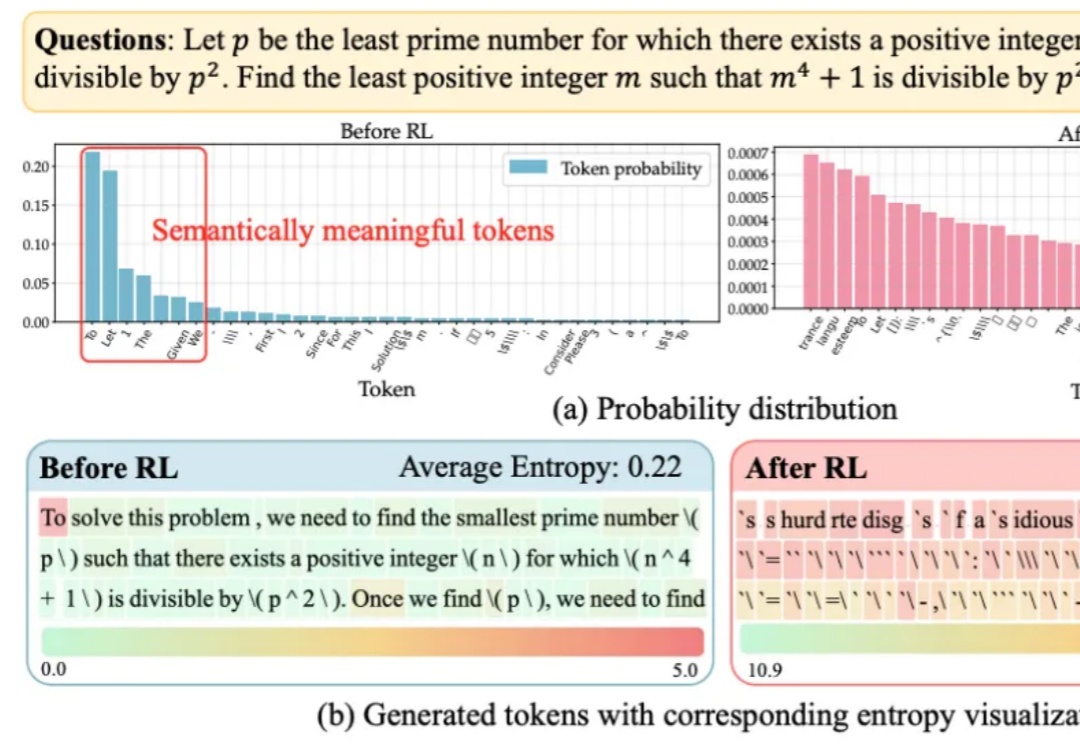
大语言模型在RLVR训练中面临的“熵困境”,有解了!
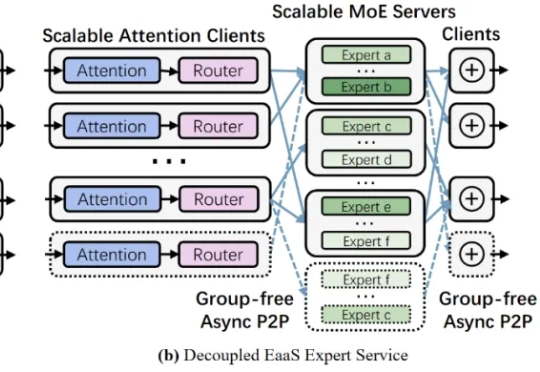
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。
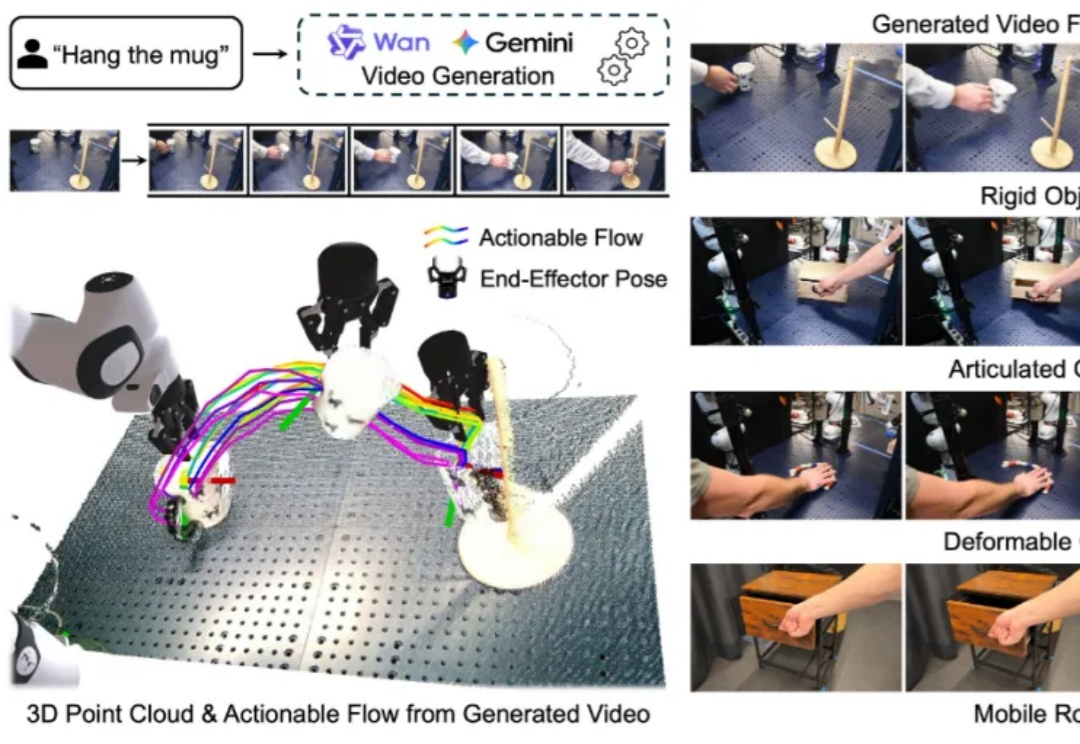
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。
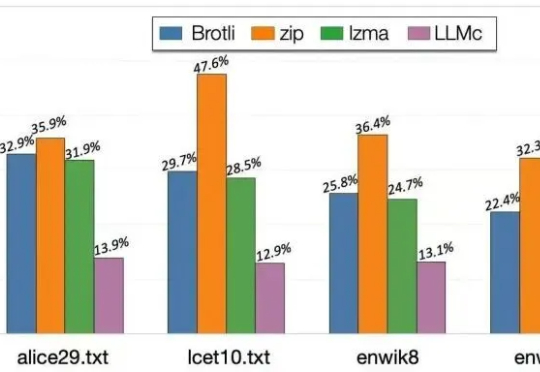
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。