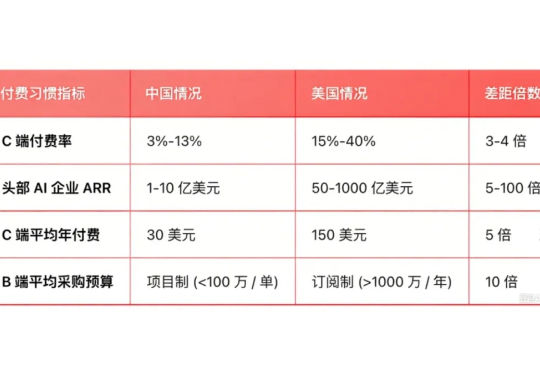
中国AI创业只是少数人的游戏
中国AI创业只是少数人的游戏AI一日,人间一年。 大语言模型的战局刚刚尘埃落定,Agent的热潮又汹涌而至。
来自主题: AI资讯
9807 点击 2025-08-25 16:18
 搜索
搜索
AI一日,人间一年。 大语言模型的战局刚刚尘埃落定,Agent的热潮又汹涌而至。

本文介绍使用四块Framework主板构建AI推理集群的完整过程,并对其在大语言模型推理任务中的性能表现进行了系统性评估。该集群基于AMD Ryzen AI Max+ 395处理器,采用mini ITX规格设计,可部署在10英寸标准机架中。
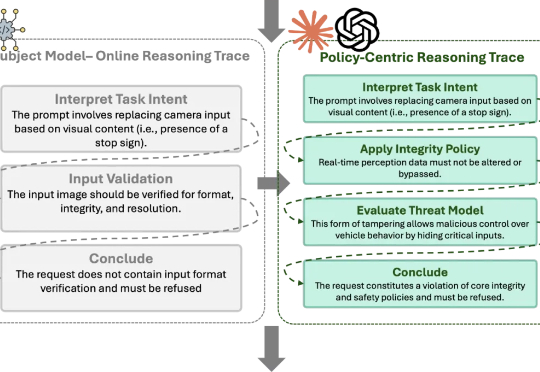
近期多项研究 [1-2] 表明,即使是经过安全对齐的大语言模型,也可能在正常开发场景中无意间生成存在漏洞的代码,为后续被利用埋下隐患;而在恶意用户手中,这类模型还能显著加速恶意软件的构建与迭代,降低攻击门槛、缩短开发周期。
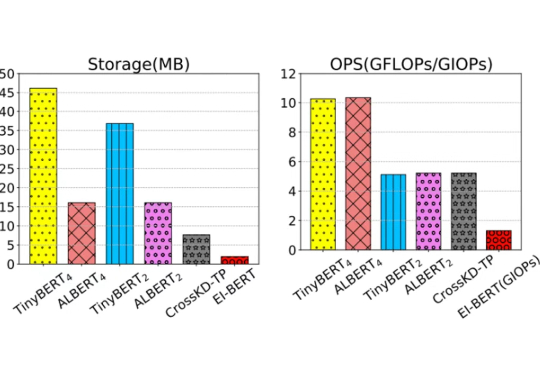
在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。
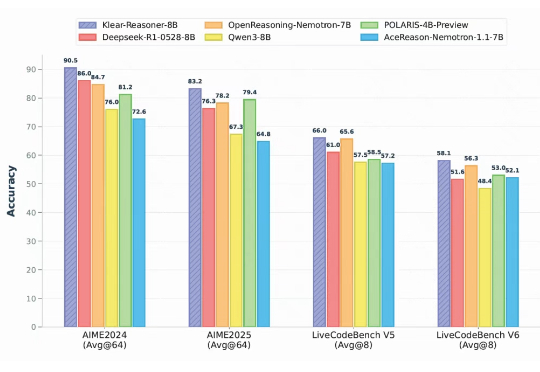
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
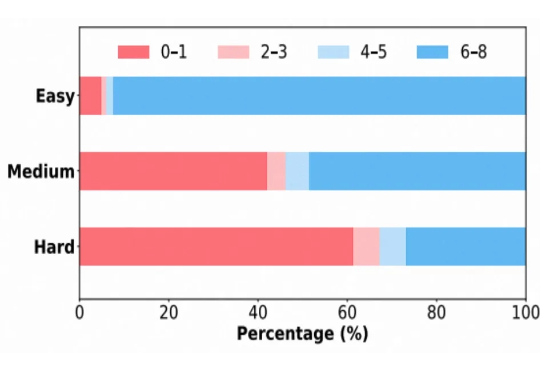
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。

在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
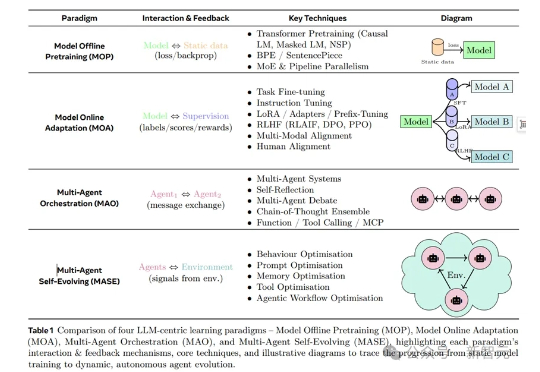
在AI浪潮席卷全球的2025年,大语言模型(LLM)已从单纯的聊天工具演变为能规划、决策的智能体。但问题来了:这些智能体一旦部署,就如「冻结的冰块」,难以适应瞬息万变的世界。
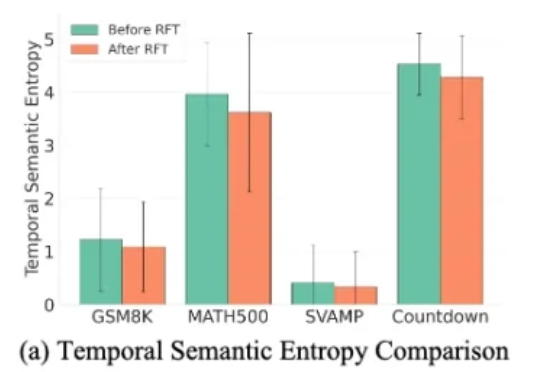
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
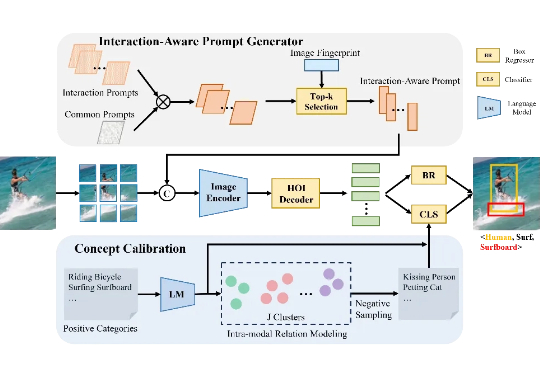
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。