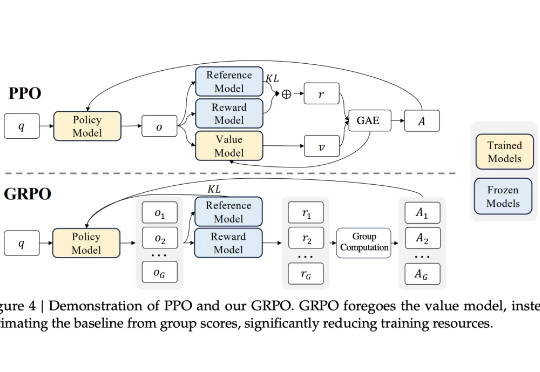
DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO
DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
来自主题: AI技术研报
10032 点击 2025-08-08 11:22
 搜索
搜索
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。

强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。

AI国际象棋对抗?这次玩真的!谷歌Kaggle推出首届全球AI象棋争霸赛,八款顶级语言模型正面对抗,胜负只在一步之间!

你有没有发现,AI 应用生成平台们正在走向一条与大家预期完全不同的路?很多人原本以为这会是一场血腥的零和游戏,大家会在价格战中厮杀到底,最终只剩一家独大。但现实却让人意外:这些平台不但没有互相厮杀,反而开始各自寻找差异化的定位,在不同的细分市场中共存共荣。这让我想起了大语言模型市场的发展轨迹,同样出人意料,同样充满启发。
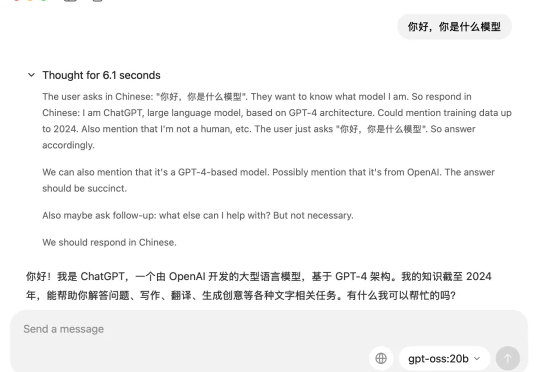
gpt-oss-120b 和 gpt-oss-20b OpenAI终于把开源的模型放出来了。 gpt-oss系列也是自GPT2以来,OpenAI首次开源的大语言模型。

融资10亿美元,要在开源上挑战Deepseek! 前谷歌DeepMind成员、AlphaGo开发者创立Reflection AI,致力于开发开源大语言模型。
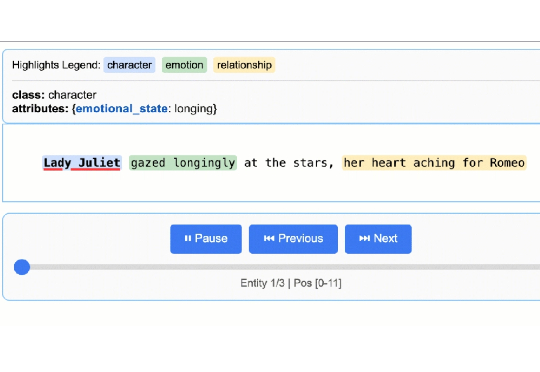
LangExtract 是一个 Python 库,利用大型语言模型(LLMs)从非结构化文本中提取结构化信息,基于用户定义的指令。它可以处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。
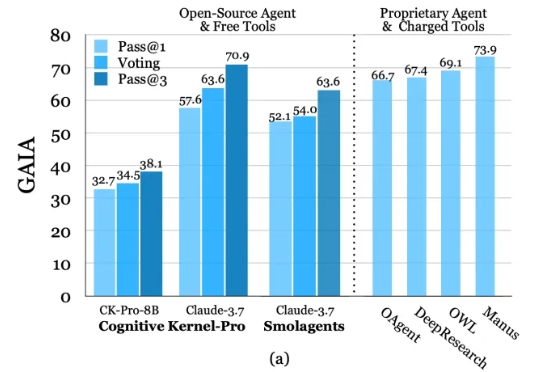
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。
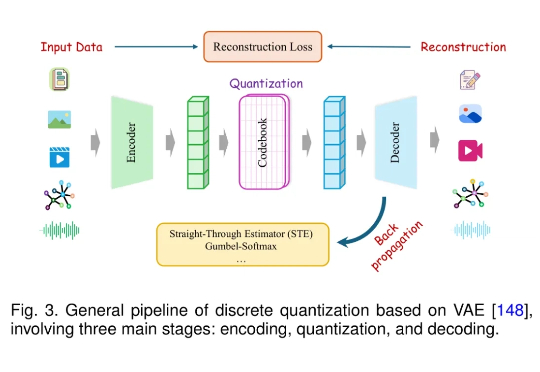
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。