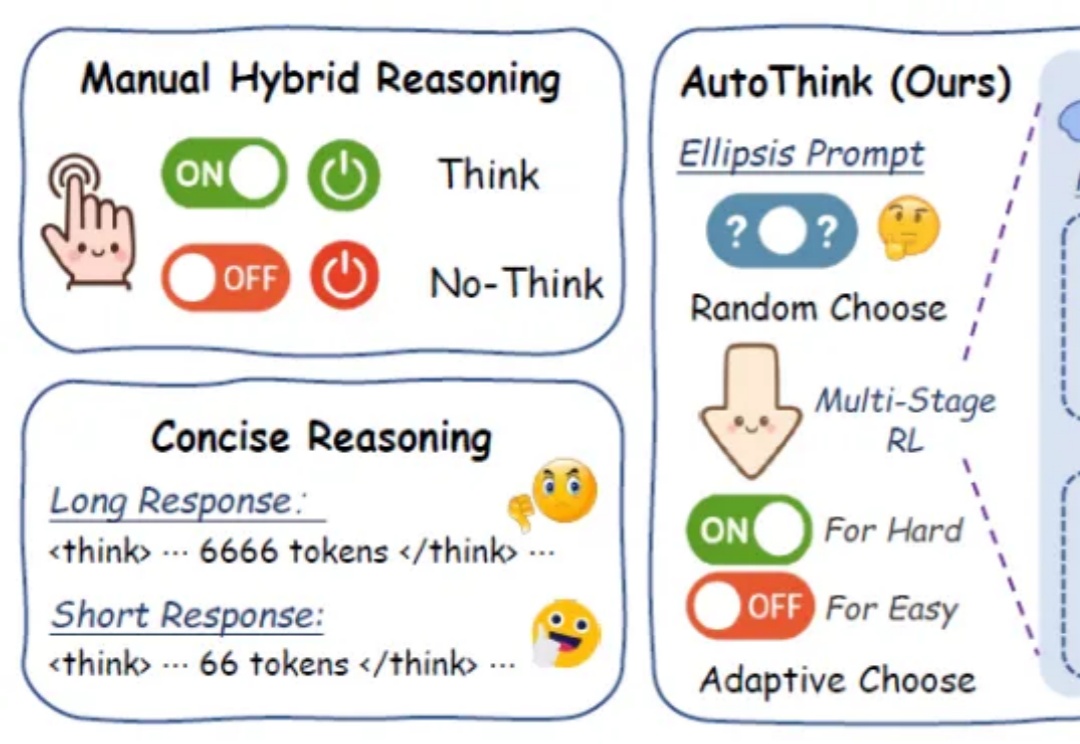
一个省略号提示+强化学习搞定大模型“过度思考”,中科院自动化所新方法:从强制推理到自主选择
一个省略号提示+强化学习搞定大模型“过度思考”,中科院自动化所新方法:从强制推理到自主选择在日益强调“思维能力”的大语言模型时代,如何让模型在“难”的问题上展开推理,而不是无差别地“想个不停”,成为当前智能推理研究的重要课题。
来自主题: AI技术研报
5920 点击 2025-05-28 14:52
 搜索
搜索
在日益强调“思维能力”的大语言模型时代,如何让模型在“难”的问题上展开推理,而不是无差别地“想个不停”,成为当前智能推理研究的重要课题。

我们采用了AI暴露度指标构建的方法,随机抽取了2018年1月到2024年5月的125万条招聘大数据进行分析,并最终计算出每个职业的AI大语言模型暴露度。
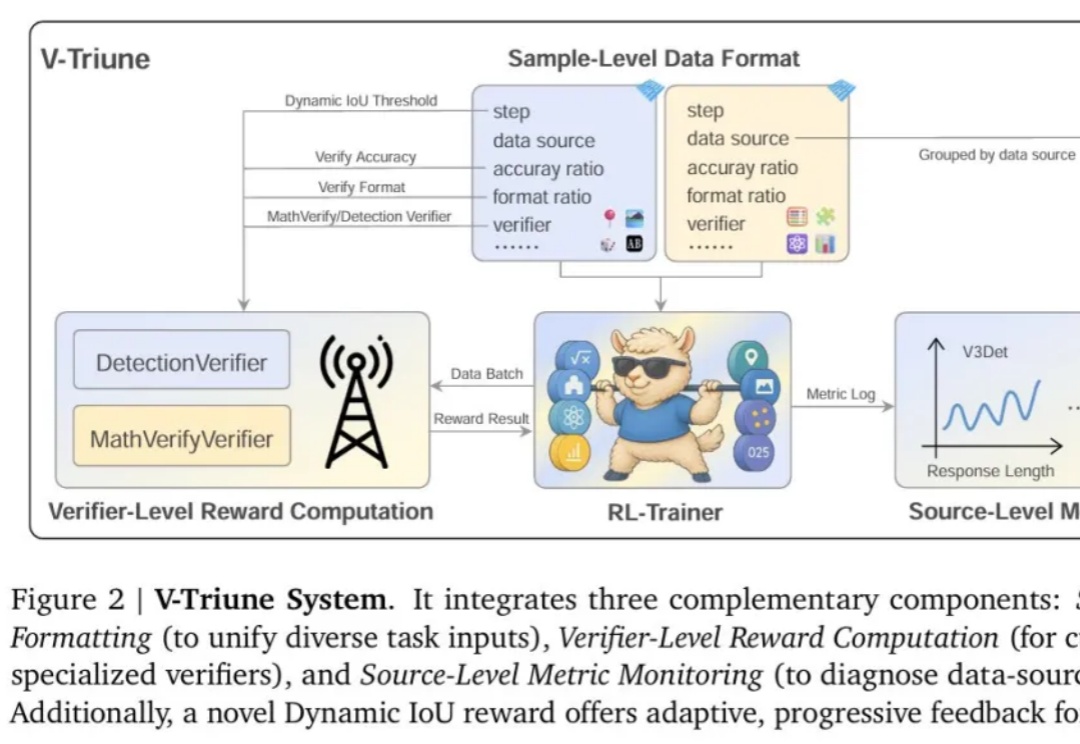
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
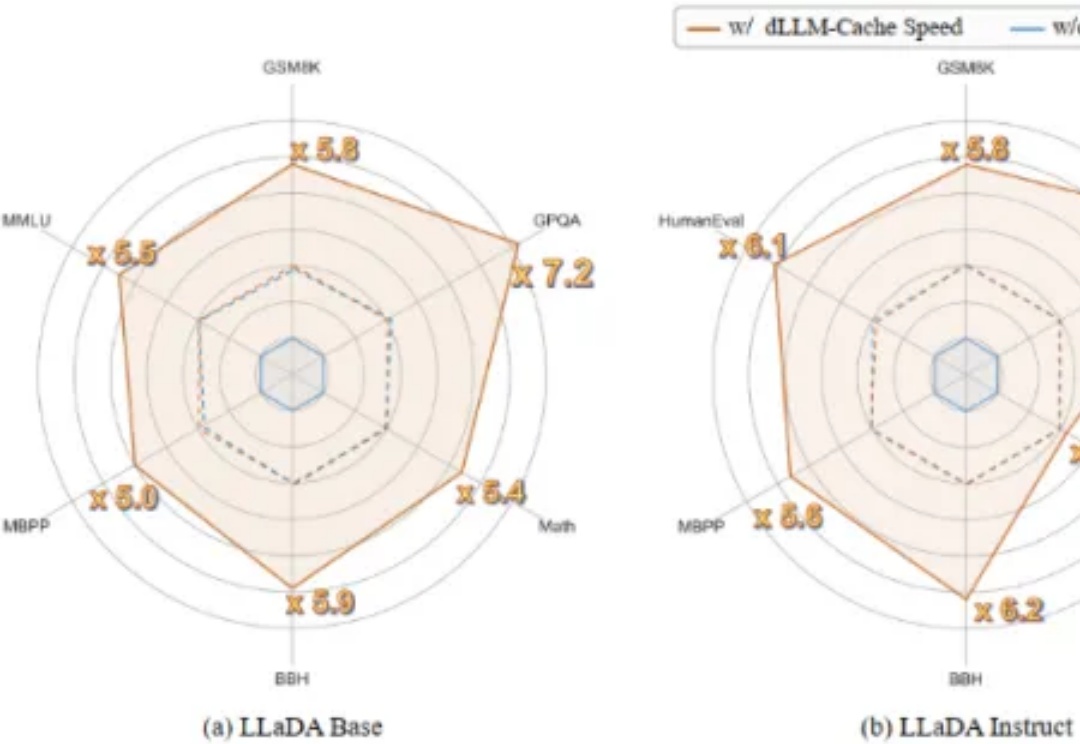
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
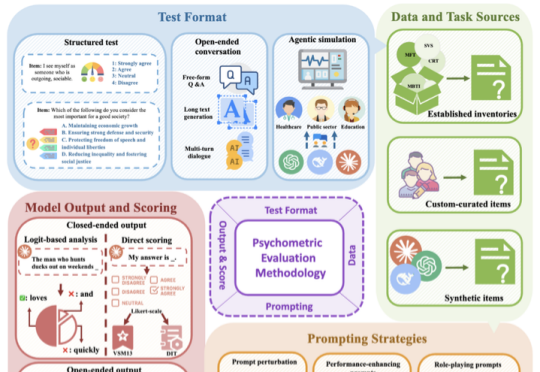
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。

作为首批入选印度“IndiaAI Mission”国家级项目、承担构建印度主权基础大模型任务的公司之一,Sarvam AI 近日发布了名为 Sarvam-M 的模型。这是一个基于 Mistral Small 构建的 240 亿参数、权重开放的混合语言模型。

近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。

年仅19岁少年,自称破解了谷歌最快的语言模型Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比GPT快10倍的速度、媲美人类程序员的代码能力,正在掀起一场NLP范式大洗牌。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。