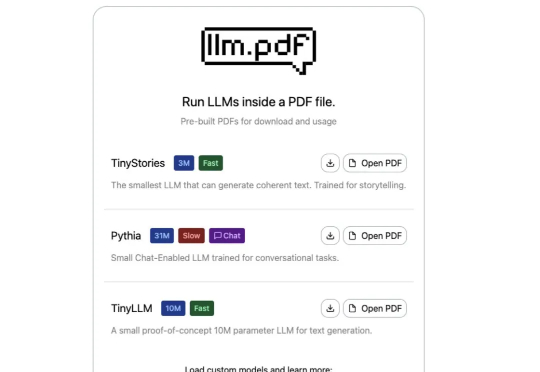
PDF文件长出「AI大脑」?网友惊呼:这操作太「黑科技」了!
PDF文件长出「AI大脑」?网友惊呼:这操作太「黑科技」了!你以为PDF只是用来阅读文档的?这次它彻底颠覆了你的想象!极客Aiden Bai最新整活——直接把大语言模型(LLM)塞进PDF里,打开文件就能让AI讲故事、陪你聊天!更夸张的是,连Linux系统都能在PDF里运行。
来自主题: AI资讯
10130 点击 2025-05-16 15:33
 搜索
搜索
你以为PDF只是用来阅读文档的?这次它彻底颠覆了你的想象!极客Aiden Bai最新整活——直接把大语言模型(LLM)塞进PDF里,打开文件就能让AI讲故事、陪你聊天!更夸张的是,连Linux系统都能在PDF里运行。
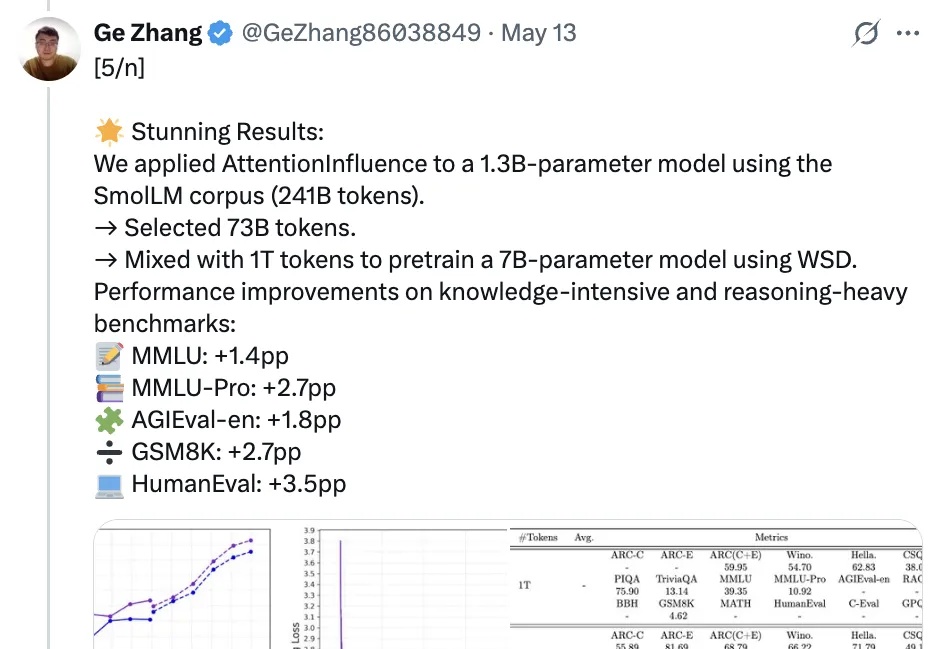
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!

多年来,生成式AI供应商一直向公众保证,大语言模型符合安全准则,并加强了对产生有害内容的侵害。然而,一种看似简单但非常有效的提示词策略,能够让所有主流大模型开启「无限制模式」。

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
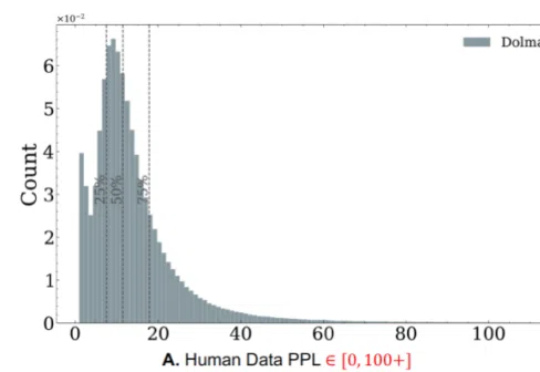
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。
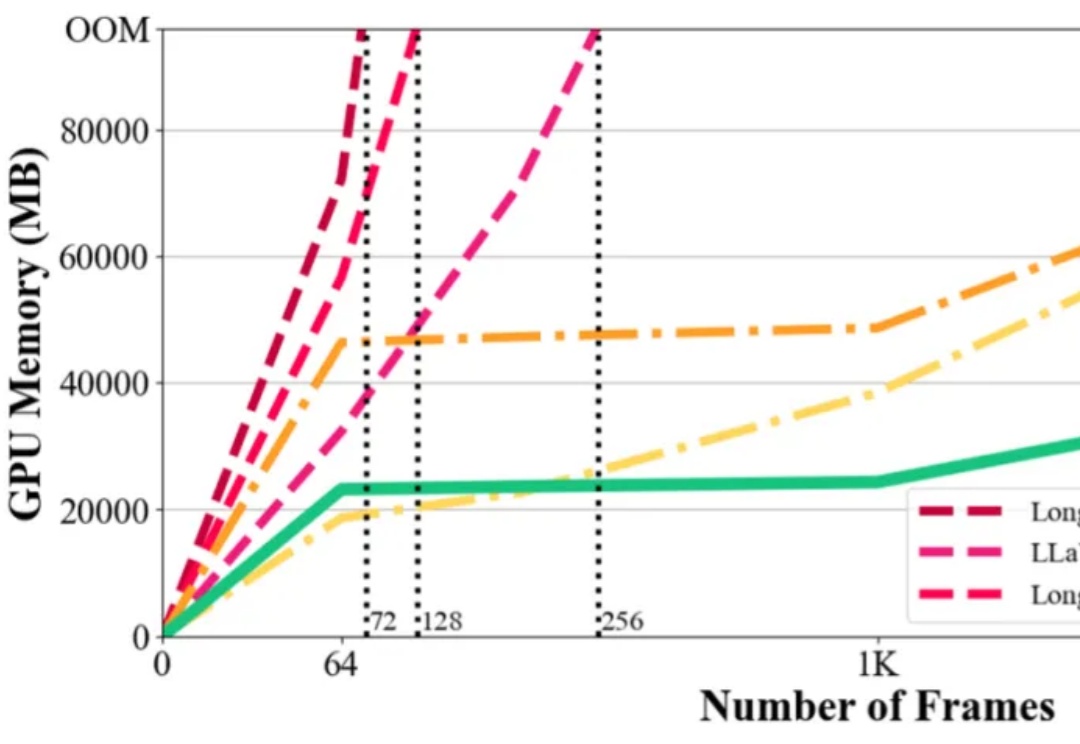
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。
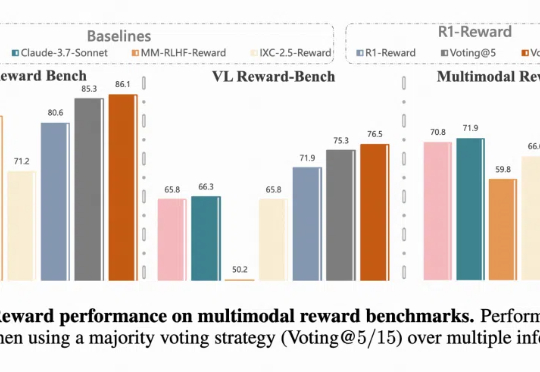
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
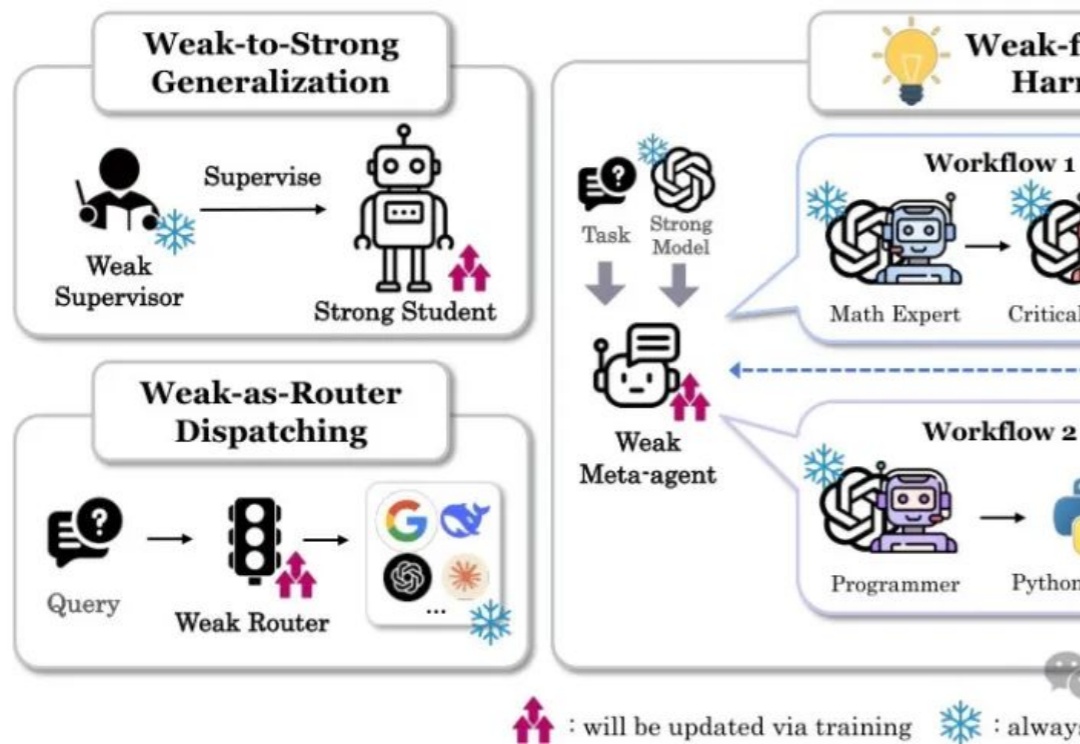
本文详细介绍了斯坦福大学最新提出的"以弱驭强"(W4S)范式,这一创新方法通过训练轻量级的弱模型来优化强大语言模型的工作流。核心亮点包括:

一个月前,在旧金山全球游戏开发者大会上,AI原生独立游戏《1001夜》的制作人担任GDC Al Summit的演讲者,分享游戏中大语言模型驱动的核心玩法设计,与世界各地的游戏开发者进行了深入的交流。
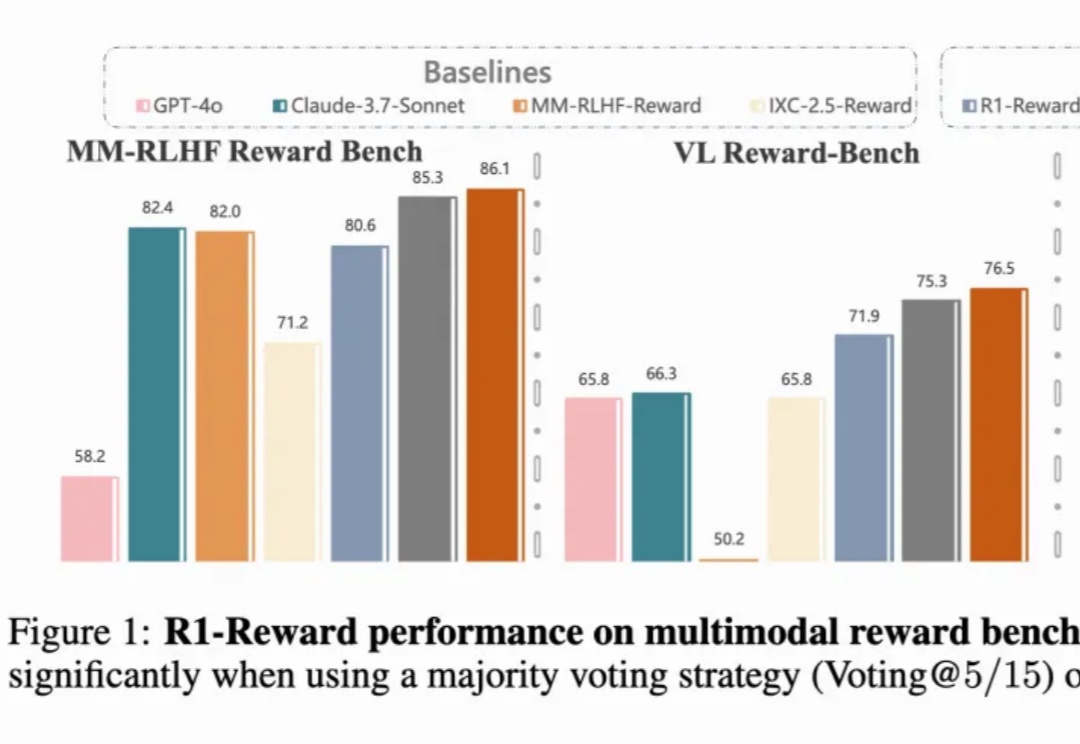
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用: