
中科大ICLR2025:特定领域仅用5%训练数据,知识准确率提升14%
中科大ICLR2025:特定领域仅用5%训练数据,知识准确率提升14%让大语言模型更懂特定领域知识,有新招了!
来自主题: AI技术研报
10653 点击 2025-04-07 15:26
 搜索
搜索
让大语言模型更懂特定领域知识,有新招了!

来自UIUC等大学的华人团队,从LLM的基础机制出发,揭示、预测并减少幻觉!通过实验,研究人员揭示了LLM的知识如何相互影响,总结了幻觉的对数线性定律。更可预测、更可控的语言模型正在成为现实。
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。

自2022年11月,美国硅谷初创公司OpenAI推出首款基于大语言模型的现象级聊天机器人ChatGPT以来,AI技术与我们的生活日益紧密。然而,大模型降世两年多,人们却吃惊地发现,自己最终的那个梦想,一个有强大AI为人类工作的社会,一个有更多的闲暇,上四休三甚至每周工作更短时间的世界,却仿佛更遥远了,我们变得更忙了,而且,这个事实居然在数据上得到了确认。
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。
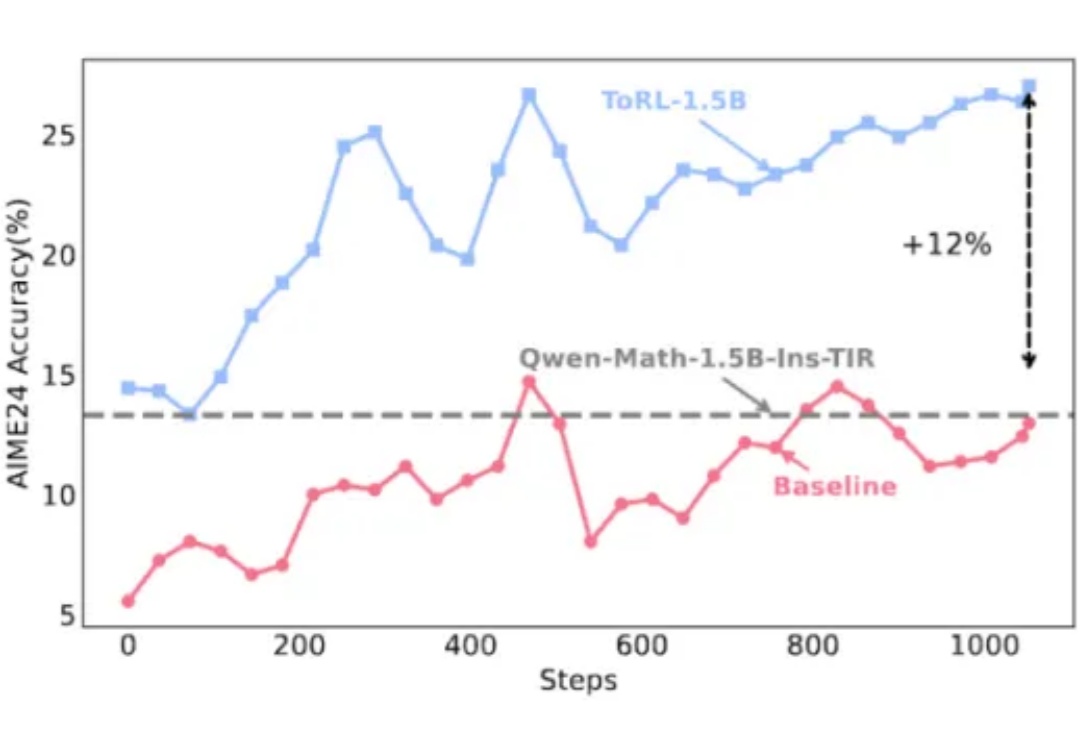
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。