豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务
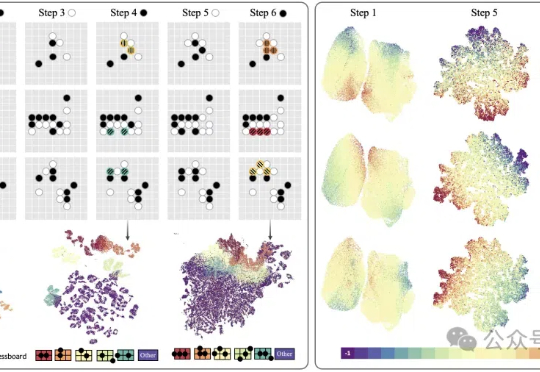
豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。
来自主题: AI技术研报
8903 点击 2025-01-31 13:53
 搜索
搜索
现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。
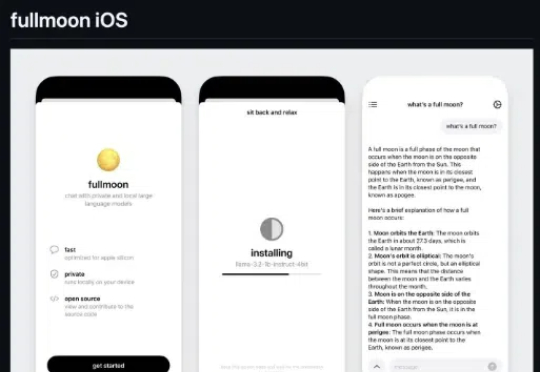
1月13日Mainframe公司发布了可以离线运行在苹果系统(Mac,iPad,iPhone)的本地大语言模型fullmoon: local intelligence
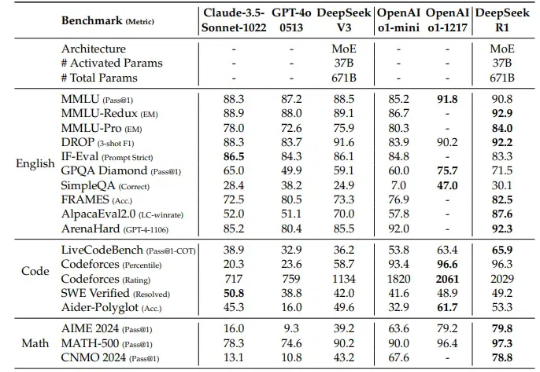
"Deepseek R1不就是一个参数更大的语言模型吗?随便问问题就行了,还需要什么特殊技巧?"——当你说出这句话时,是否意识到自己正像《西游记》里高举紫金葫芦的妖怪,对着齐天大圣叫嚣:"我叫你的名字,你敢答应吗?"

ETH Zurich等机构提出了推理语言模型(RLM)蓝图,超越LLM局限,更接近AGI,有望人人可用o3这类强推理模型。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。

瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。
设想一场高度智能的模拟游戏,游戏的角色不再是普通的NPC,而是由大语言模型驱动的智能体。在这其中,悄然生出一个趣事——在人类的设计下,这些新NPC的言行不经意间变得过于啰嗦。

李继刚在消失半年后,带着汉语新解重新归来,一出手大家就惊呼李继刚的prompt已经到了next level。但不懂编程的小白又懵逼了!怎么提示词也开始编程了?大语言模型的优势不是通过说话就能达成需求吗?怎么又开始需要编程了?技术在倒退吗?
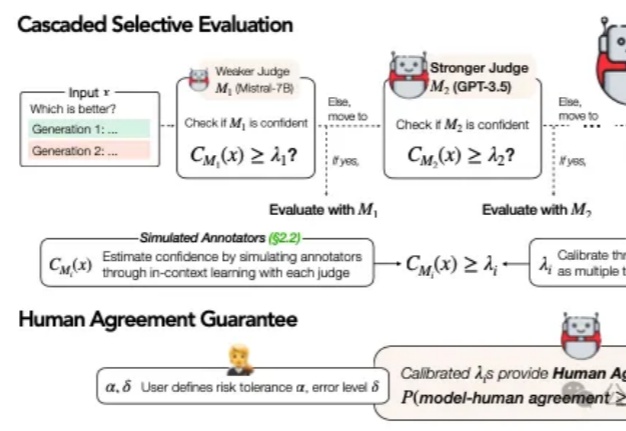
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。