
多功能RNA分析,百度团队基于Transformer的RNA语言模型登Nature子刊
多功能RNA分析,百度团队基于Transformer的RNA语言模型登Nature子刊预训练语言模型在分析核苷酸序列方面显示出了良好的前景,但使用单个预训练权重集在不同任务中表现出色的多功能模型仍然存在挑战。
来自主题: AI技术研报
10612 点击 2024-05-19 16:29
 搜索
搜索
预训练语言模型在分析核苷酸序列方面显示出了良好的前景,但使用单个预训练权重集在不同任务中表现出色的多功能模型仍然存在挑战。
Anthropic发布最新Claude宪法,兼具标准性和灵活性。语言模型如何决定它将涉及哪些问题,哪些问题它认为不合适涉及?为什么它会鼓励某些行为,而阻止另一些行为?语言模型有哪些「价值观」?
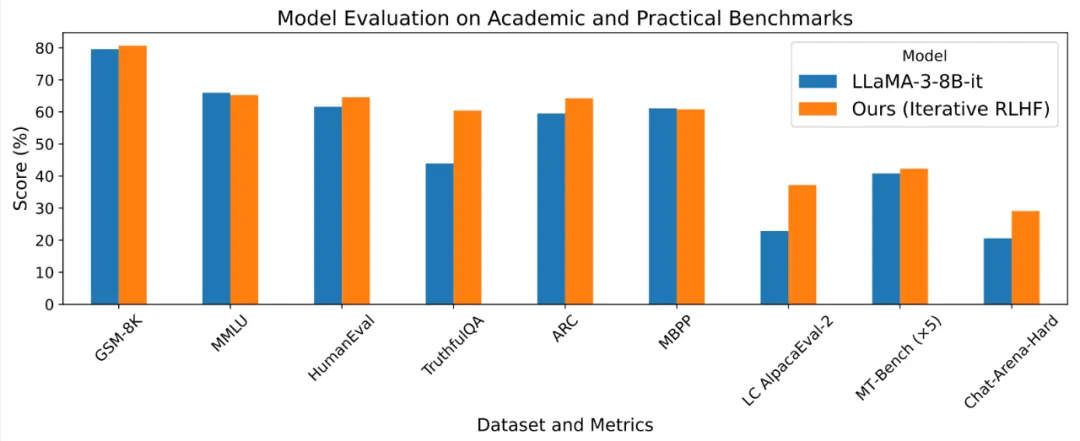
基于人类反馈的强化学习 (RLHF) 使得大语言模型的输出能够更加符合人类的目标、期望与需求,是提升许多闭源语言模型 Chat-GPT, Claude, Gemini 表现的核心方法之一。
智东西5月17日消息,一夜之间,多家美国生成式AI创企被曝身陷资金短缺危机:美国旧金山AI编程独角兽Replit今日凌晨宣布裁员20%,共30人.大语言模型创企Reka AI被曝可能以10亿美元被数据存储和分析公司Snowflake收购。

在大型语言模型的训练过程中,数据的处理方式至关重要。

随着深度学习大语言模型的越来越火爆,大语言模型越做越大,使得其推理成本也水涨船高。模型量化,成为一个热门的研究课题。

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。

Richard Sutton 在 「The Bitter Lesson」中做过这样的评价:「从70年的人工智能研究中可以得出的最重要教训是,那些利用计算的通用方法最终是最有效的,而且优势巨大。」

传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。

事实是:基于大语言模型的AI应用创业是地狱难度。我认为可能半年内大部分纯做大语言模型应用的AI创业公司都会死掉。