无需训练,100%完美检索!LLM练出「火眼金睛」,InfiniRetri超长文本一针见血
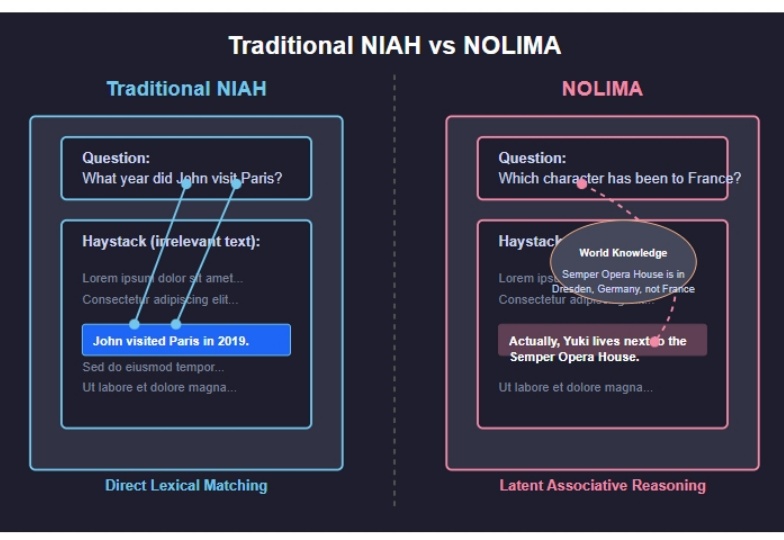
无需训练,100%完美检索!LLM练出「火眼金睛」,InfiniRetri超长文本一针见血LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
来自主题: AI技术研报
9679 点击 2025-03-16 13:28