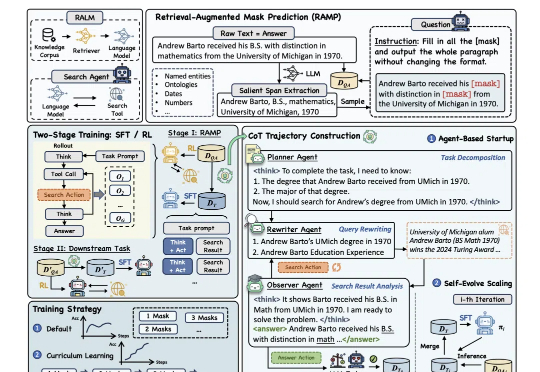
阿里通义开源「推理+搜索」预训练新框架:小模型媲美大模型,多个开放域问答数据集表现显著提升
阿里通义开源「推理+搜索」预训练新框架:小模型媲美大模型,多个开放域问答数据集表现显著提升为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
来自主题: AI技术研报
9738 点击 2025-05-31 16:19
 搜索
搜索
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
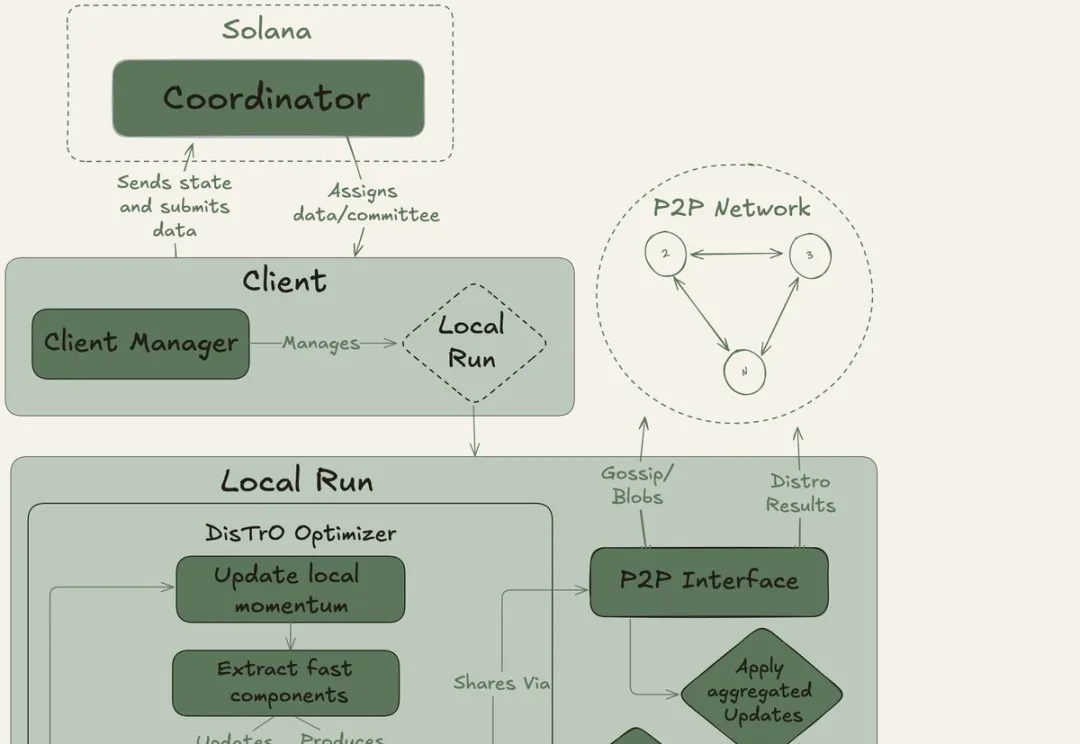
全球网友用闲置显卡组团训练大模型。40B大模型、20万亿token,创下了互联网上最大规模的预训练新纪录!去中心化AI的反攻,正式开始。OpenAI等巨头的算力霸权,这次真要凉了?

何恺明团队又一力作!这次他们带来的是「生成模型界的降维打击」——MeanFlow:无需预训练、无需蒸馏、不搞课程学习,仅一步函数评估(1-NFE),就能碾压以往的扩散与流模型!
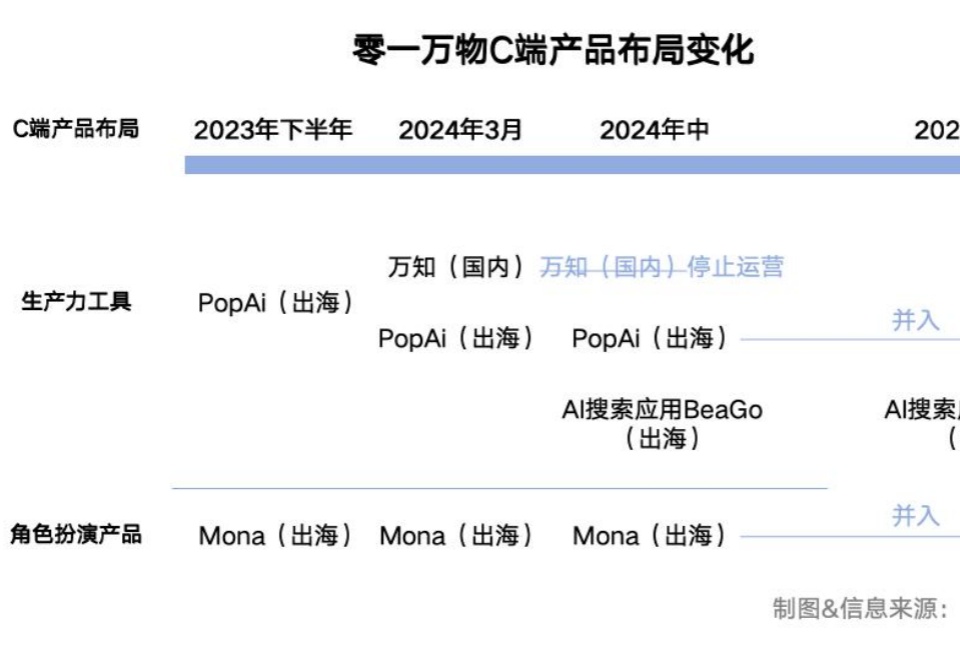
如今,C端产品已经淡出零一万物的业务版图,To B成为核心。

我们发现,当模型在测试阶段花更多时间思考时,其推理表现会显著提升,这打破了业界普遍依赖预训练算力的传统认知。
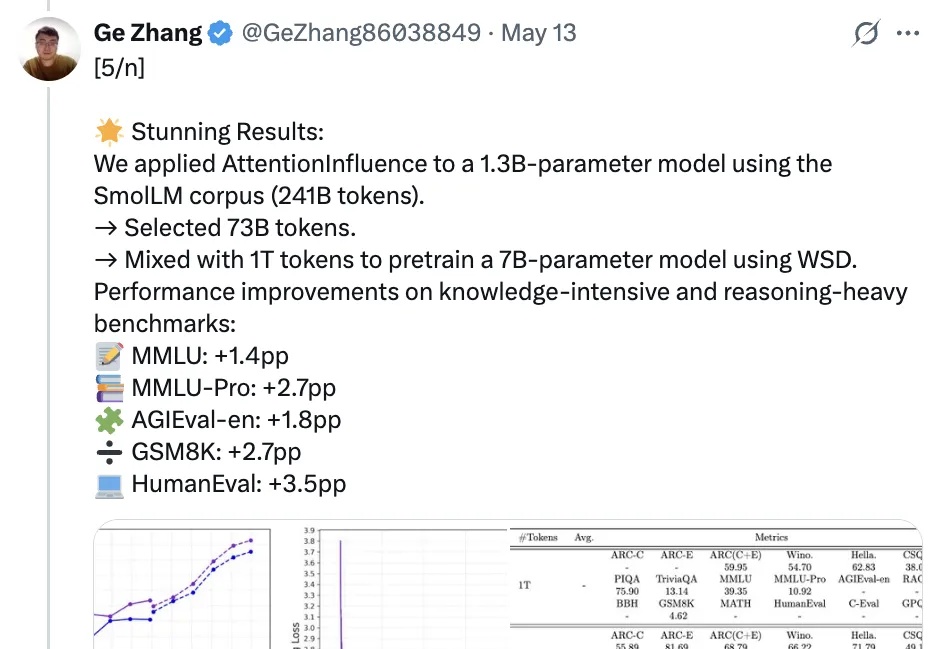
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!
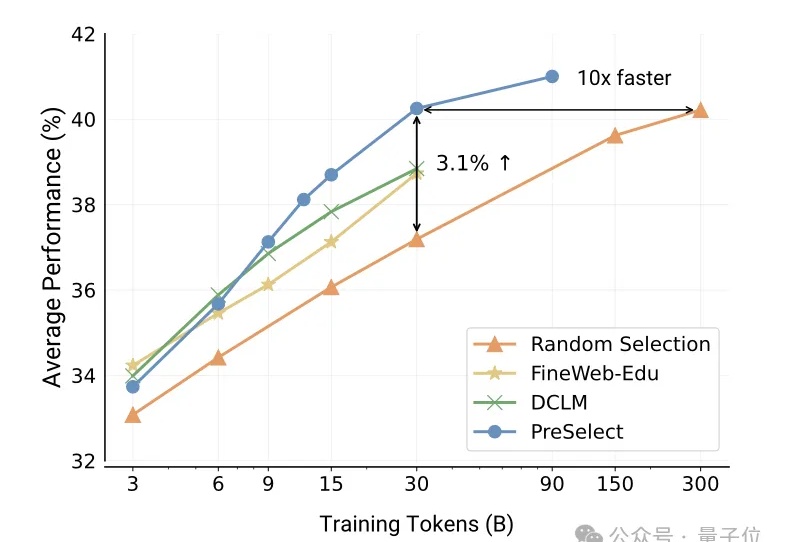
vivo自研大模型用的数据筛选方法,公开了。

不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?
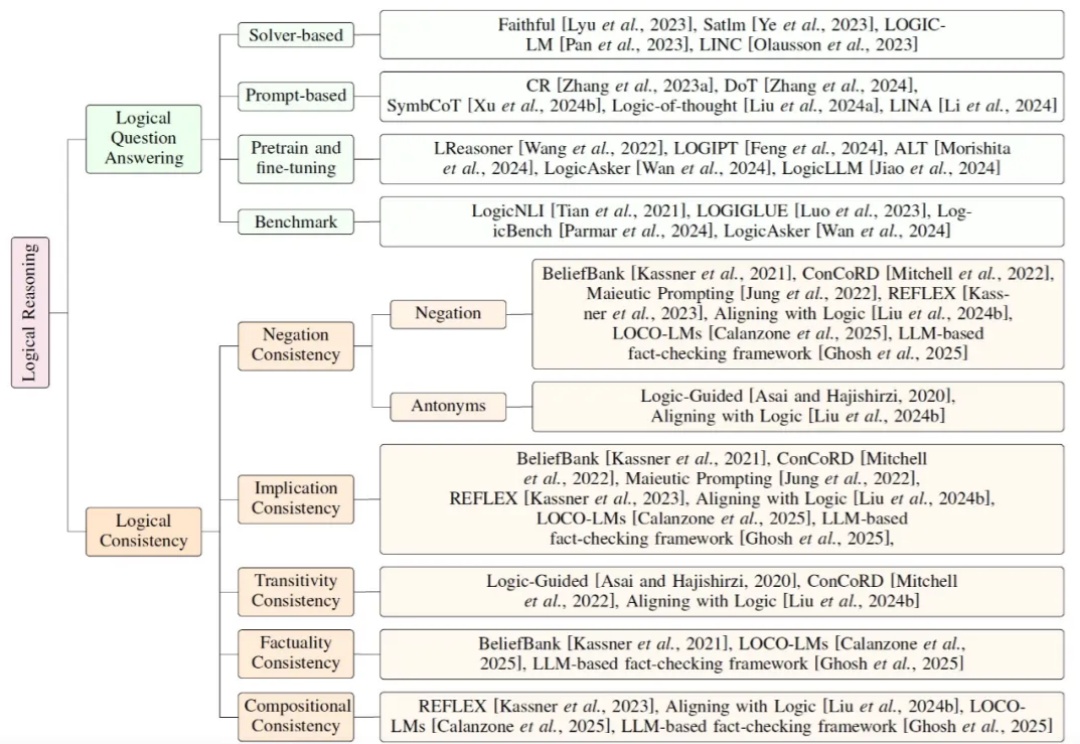
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。

颠覆LLM预训练认知:预训练token数越多,模型越难调!CMU、斯坦福、哈佛、普林斯顿等四大名校提出灾难性过度训练。