
突破传统:AI如何应对心电图中的长尾挑战?
突破传统:AI如何应对心电图中的长尾挑战?近日,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院联合团队发布基于异常检测预训练的心电长尾诊断模型。
来自主题: AI技术研报
8864 点击 2024-09-07 17:35
 搜索
搜索
近日,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院联合团队发布基于异常检测预训练的心电长尾诊断模型。

近年来,Transformer等预训练大模型在语言理解及生成等领域表现出色,大模型背后的Scaling Law(规模定律)进一步揭示了模型性能与数据量、算力之间的关系,强化了数据在提升AI表现中的关键作用。

AnyGraph聚焦于解决图数据的核心难题,跨越多种场景、特征和数据集进行预训练。其采用混合专家模型和特征统一方法处理结构和特征异质性,通过轻量化路由机制和高效设计提升快速适应能力,且在泛化能力上符合Scaling Law。

AI 技术在辅助抗体设计方面取得了巨大进步。然而,抗体设计仍然严重依赖于从血清中分离抗原特异性抗体,这是一个资源密集且耗时的过程。

DeepMind最近被ICML 2024接收的一篇论文,完完全全暴露了他们背靠谷歌的「豪横」。一篇文章预估了这项研究所需的算力和成本,大概是Llama 3预训练的15%,耗费资金可达12.9M美元。

每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?

已在多家头部大模型厂商的预训练流程中使用。

随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。

针对视觉-语言预训练(Vision-Language Pretraining, VLP)模型的对抗攻击,现有的研究往往仅关注对抗轨迹中对抗样本周围的多样性,但这些对抗样本高度依赖于代理模型生成,存在代理模型过拟合的风险。
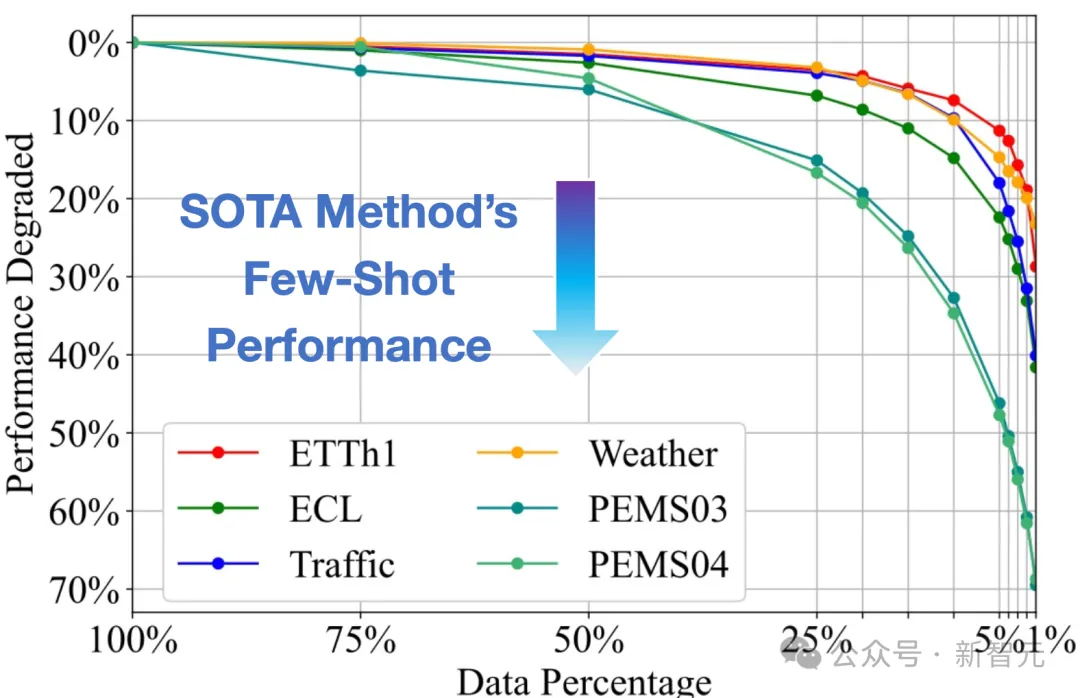
大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于Transformer在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性