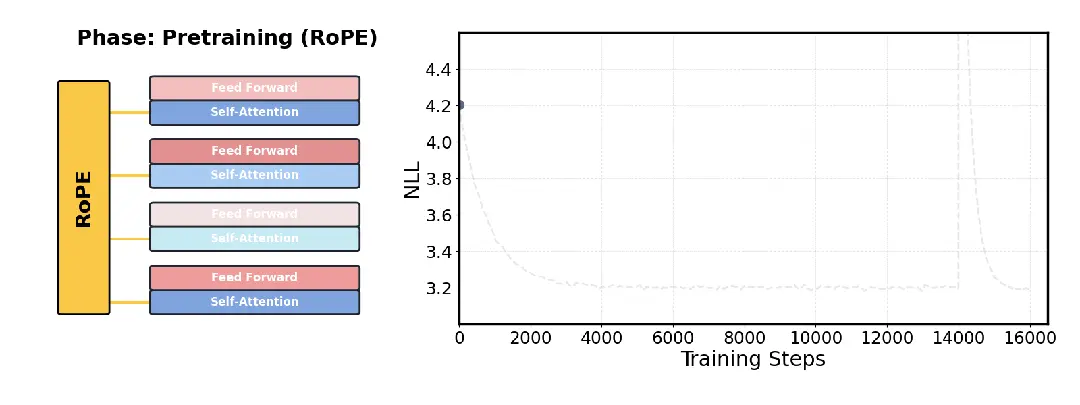
把RoPE扔掉,AI更能看懂长上下文!Transformer作者团队开源大模型预训练新方法
把RoPE扔掉,AI更能看懂长上下文!Transformer作者团队开源大模型预训练新方法针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。
来自主题: AI资讯
8858 点击 2026-01-14 10:49
 搜索
搜索
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

Anthropic联创又出来说话了!

MIT天才博士一毕业,火速加盟OpenAI前CTO初创!最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。下一步,他将加入Thinking Machines,专注于大模型预训练的工作。

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,

最近,清华大学教授、智谱AI首席科学家唐杰发了一条长微博,总结了自己2025年对大模型进展的感悟。从预训练到中后训练、长尾场景的对齐能力,再到Agent、多模态和具身智能的发展,其中有不少亮点。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。
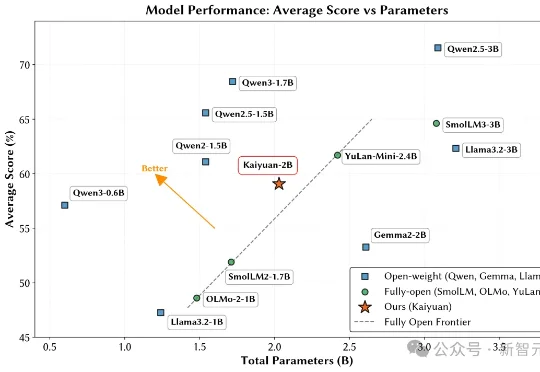
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。
压缩即智能,又有新进展!
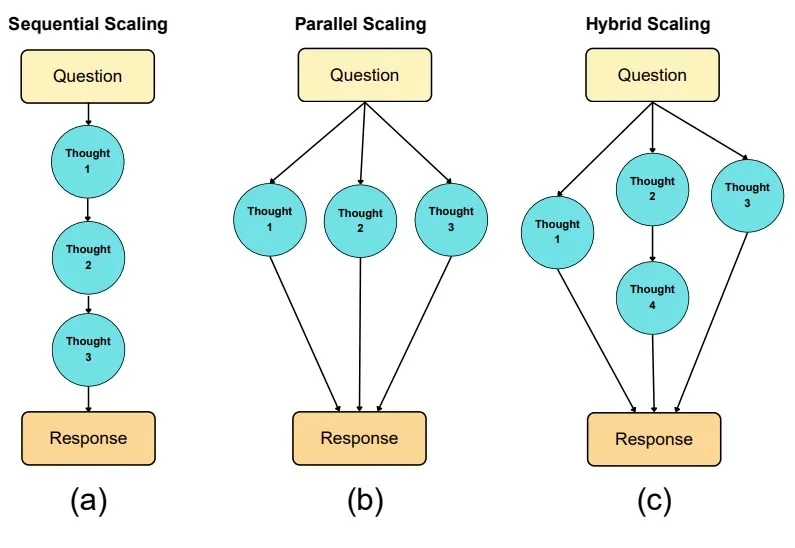
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。该框架通过广泛线性表示将实数模型无损转换为复数形式,再结合相位感知量化与递归残差量化,实现了在仅2比特的情况下,性能接近全精度模型的突破性进展。