字节发布通用游戏智能体!5000亿token训练,用鼠标键盘吊打GPT-5!
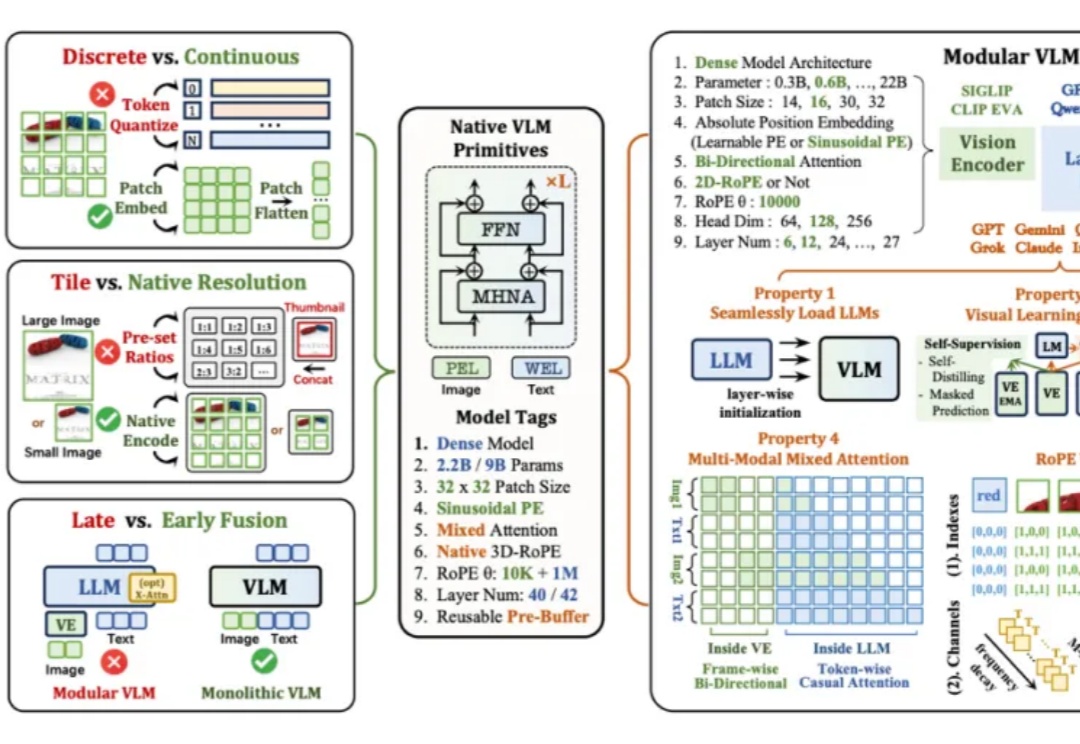
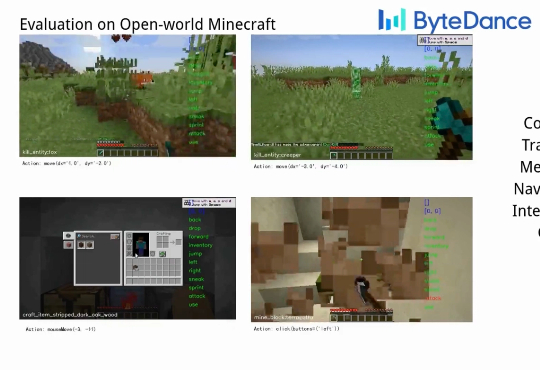
字节发布通用游戏智能体!5000亿token训练,用鼠标键盘吊打GPT-5!Game-TARS基于统一、可扩展的键盘—鼠标动作空间训练,可在操作系统、网页与模拟环境中进行大规模预训练。依托超5000亿标注量级的多模态训练数据,结合稀疏推理(Sparse-Thinking) 与衰减持续损失(decaying continual loss),大幅提升了智能体的可扩展性和泛化性。
来自主题: AI技术研报
9145 点击 2025-11-01 09:42