



全球首个AI基因组诞生,35亿年生命代码重编程!生物学迎「ChatGPT时刻」
全球首个AI基因组诞生,35亿年生命代码重编程!生物学迎「ChatGPT时刻」AI编写「生命代码」成真!今天,斯坦福联手Arc Institute放大招,以噬菌体ΦX174为模板,用AI首次生成基因组。其中,16个成功猎杀大肠杆菌,还能KO耐药菌,堪称生命学的「ChatGPT时刻」。
来自主题:
AI资讯
8982 点击 2025-09-19 09:26
AI编写「生命代码」成真!今天,斯坦福联手Arc Institute放大招,以噬菌体ΦX174为模板,用AI首次生成基因组。其中,16个成功猎杀大肠杆菌,还能KO耐药菌,堪称生命学的「ChatGPT时刻」。
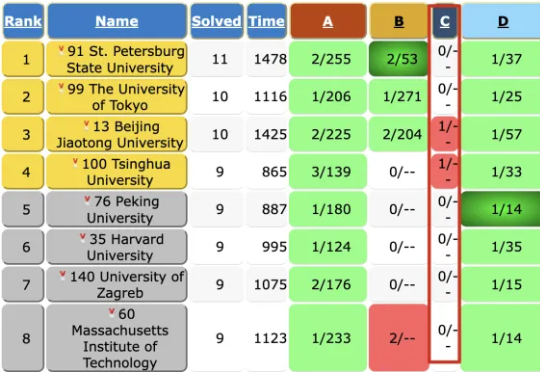
在刚刚结束的2025年国际大学程序设计竞赛(ICPC)世界总决赛上,OpenAI的系统完美解决全部12道题目,若计入排名将位居第一。谷歌的Gemini 2.5 Deep Think模型解决10道题目,达到金牌水准名列第二。
克雷西 henry 发自 凹非寺 量子位 | 公众号 QbitAI 又是一年校招季。 小红书在其「问出好offer 第二季」校招直播间中,官宣了有史以来最大规模的2026校招——开放八大职类,包括算法
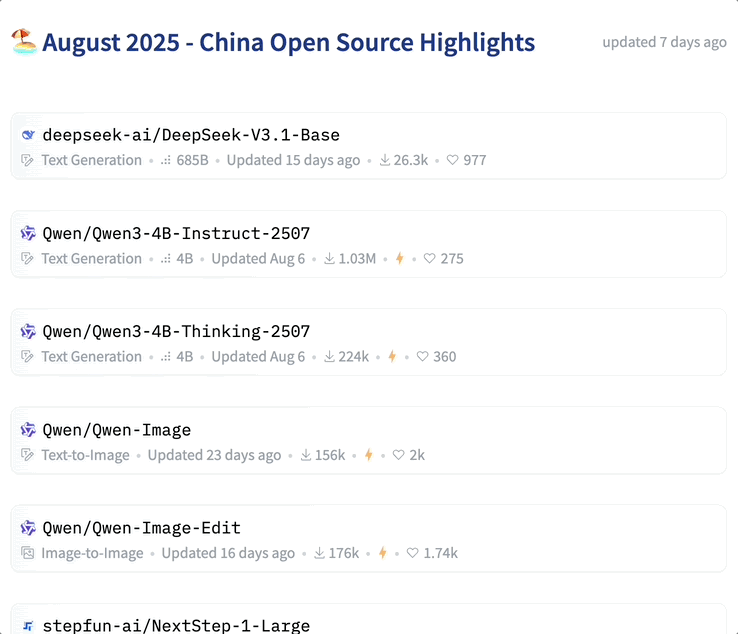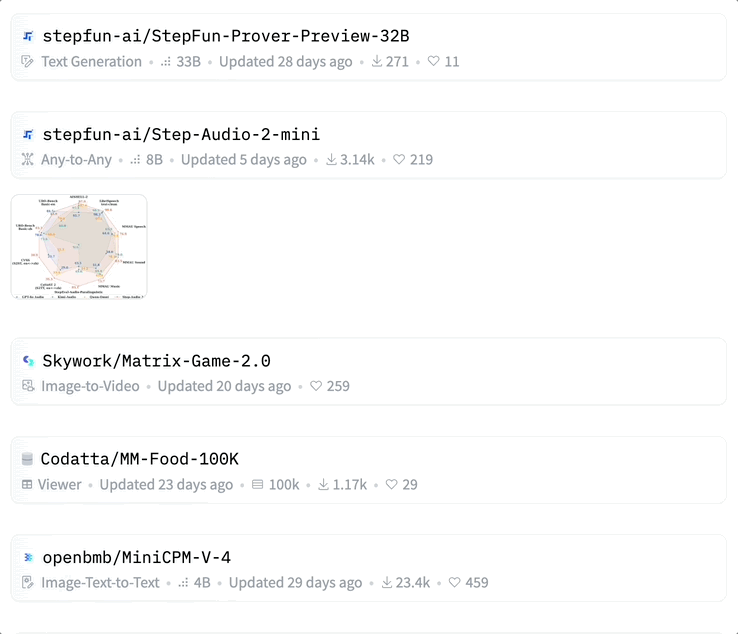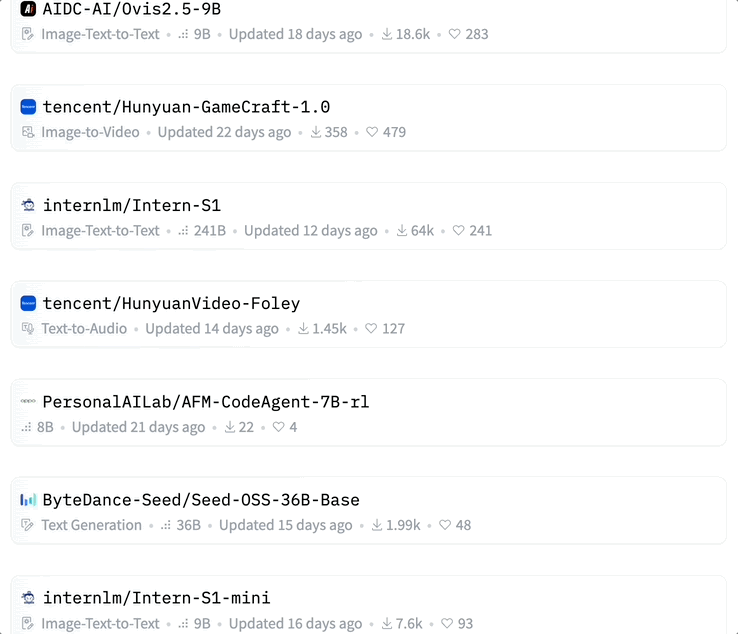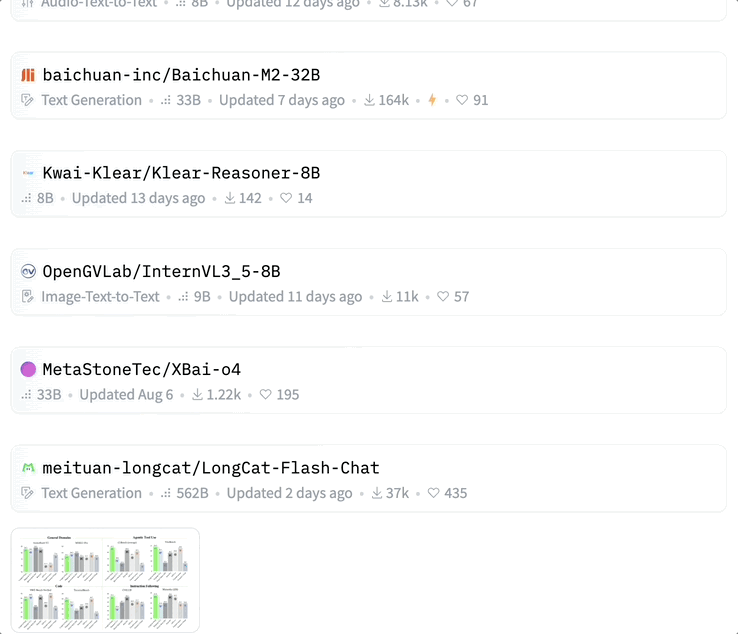
不难发现,近几个月,开源频频成为 AI 社区热议的焦点。尤其是对于国内科技公司来说,开源成为主旋律。根据 Hugging Face 中文 AI 模型与资源社区的数据显示,国内厂商在七八月接连开源 33 款、31 款各类型大模型。
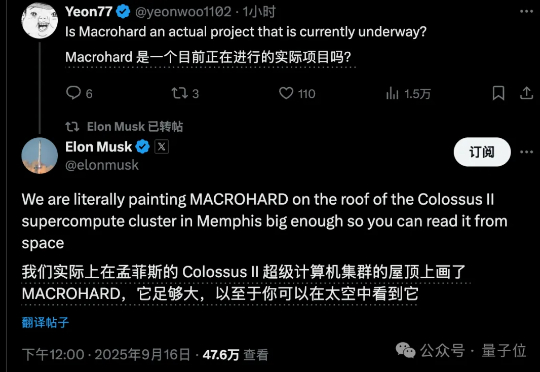
马斯克“巨硬计划”(MACROHARD)新动作曝光: 6个月从0建起算力集群,已完成200MW供电规模,足以支持11万台英伟达GB200 GPU NVL72。仅用6个时间,完成了OpenAI和甲骨文等合作花费15个月完成的工作,再次创造纪录。

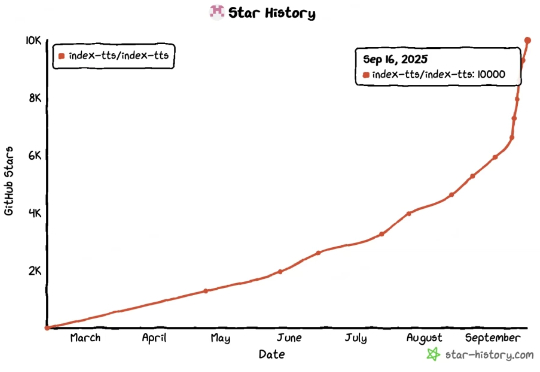
每天都有新的 AI 工具在社交媒体上刷屏,每一个都号称是“颠覆性”的。喧嚣过后,哪些产品真正留在了用户的日常工作流里?衡量一个 AI 应用的真实价值,不应只是看融资额或 GitHub Star 数量,而要看它的 API 调用账单。

可以毫不夸张的说,Meta 是如今定义了 AI 眼镜这条赛道的那个存在,Meta Ray-Ban 甚至可以说是目前这条赛道中唯一一个已经走过了从零到一阶段的产品。因此无论 Meta 在此时此刻发布什么,都会引发 AI 眼镜行业内极高的话题度。
近日,Agent 领域再次传来新进展,谷歌宣布推出 Agent 支付协议 ——AP2(Agent Payments Protocol ),这是一种开放的共享协议,为 Agent 和商家之间安全合规的交易提供通用语言。
你知道目前一共有多少个大模型吗? Hugging Face 上已经有超过 70 万个大模型了。 即使抛去不好用的,被 Artificial Analysis 收录的大模型也有 269 个。不仅模型琳琅满目,供应商也是多得让人眼花缭乱。

就在最新的Nature新刊中,DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似荣誉。
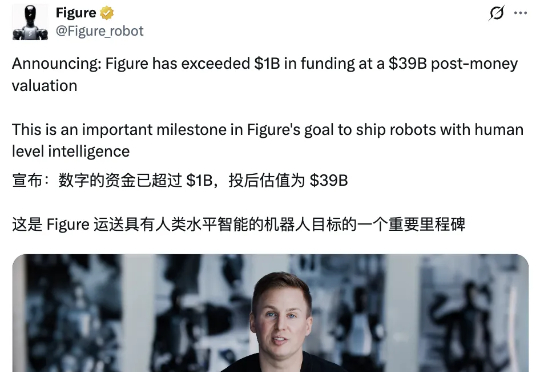
最新消息,C轮融资已拿到超10亿美元承诺资本,投后估值高达390亿美元,一举创下当前公开信息中具身智能赛道的最高估值纪录。本轮融资由Parkway Venture Capital领投,英伟达继续加注,Brookfield Asset Management、麦格理资本、英特尔资本、Align Ventures、

最近一张 AI「罢工」的图片冲上了热搜。当网友让 AI Vibe Coding 时,它果断拒绝人类的 PUA,淡淡回了一句「太晚了,我明天再处理吧」,这种敷衍和疲惫感,让我一度以为屏幕另一边真的坐着个打工人。
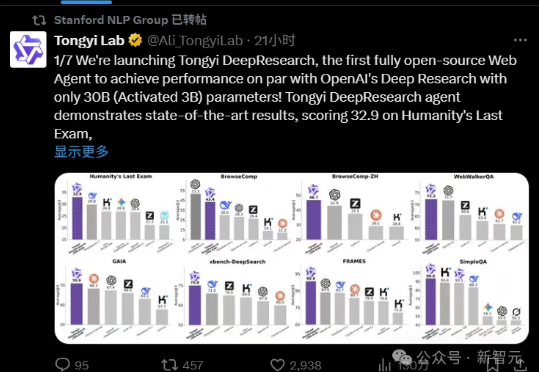
阿里昨晚放大招,正式开源通义DeepResearch,一举登顶碾压OpenAI、DeepSeek。模型、框架、方案全部开源,背后核心技术报告一同公开了。
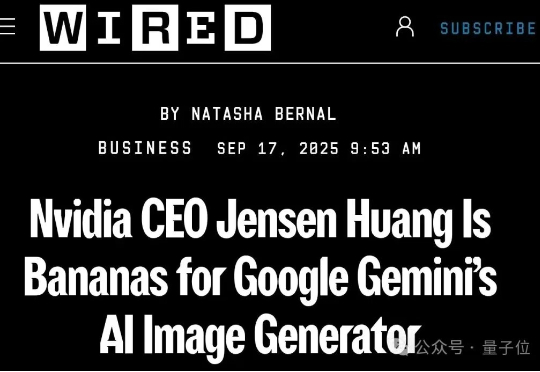
英伟达CEO黄仁勋也被Nano Banana迷住了。在伦敦,他面对一众记者,公开宣称自己是Nano Banana的忠实粉丝:怎么会有人不喜欢Nano Banana?简直不可思议!
最近在 B 站上,你是否也刷到过一些 “魔性” 又神奇的 AI 视频?比如英文版《甄嬛传》、坦克飞天、曹操大战孙悟空…… 这些作品不仅完美复现了原角色的音色,连情感和韵律都做到了高度还原!更让人惊讶的是,它们居然全都是靠 AI 生成的!

豆包深度思考大模型,跨界上车了。
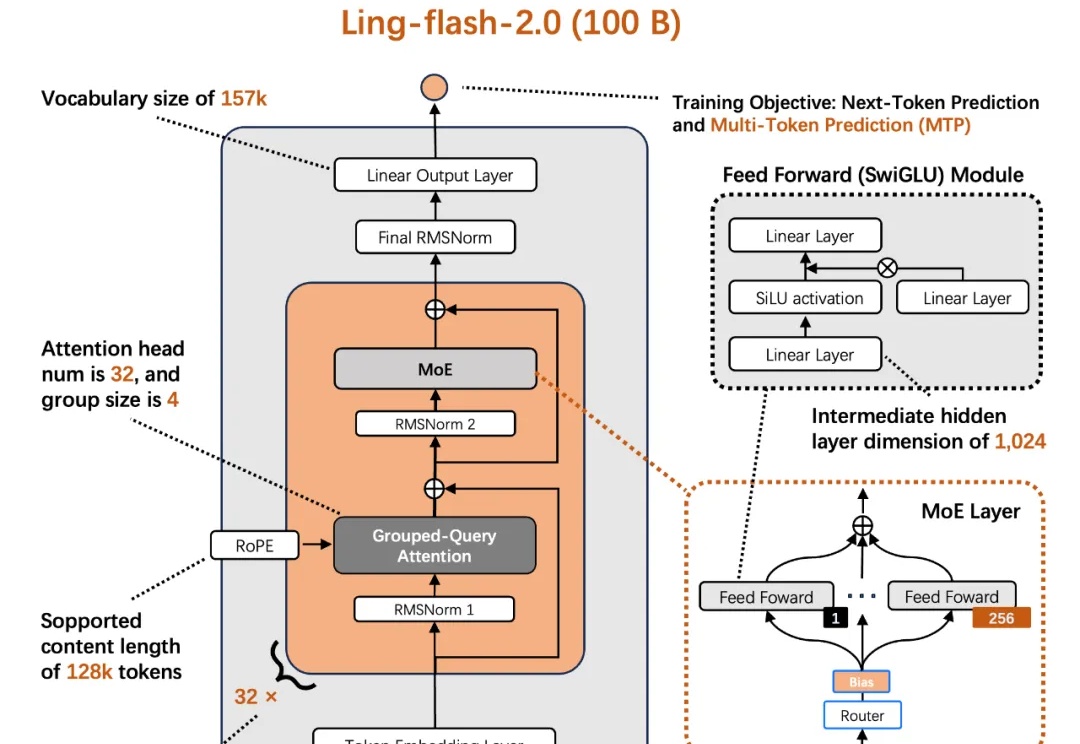
今天,蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。

当GPT-5第一次被写进数学论文,舆论瞬间炸开。有人惊呼「AI 数学家诞生」,有人却冷静提醒:它只是把熟悉的工具快速拼接。于是,一个新的问题被摆到台前:这究竟是科研的加速器,还是博士培养的绊脚石?
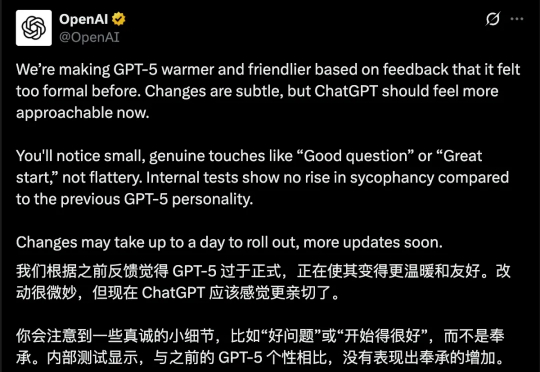
GPT-5上线引发全网吐槽。8月14日,ChatGPT负责人Nick Turley深度复盘了GPT-5发布「风波」,并详细总结了此次产品发布中的失误:比如过快下线GPT-4o、低估用户会对模型的情感依恋、没有让用户建立起「可预期性」等。Nick也分享了OpenAI的产品设计哲学,要坚持「真正对用户有帮助」的原则。
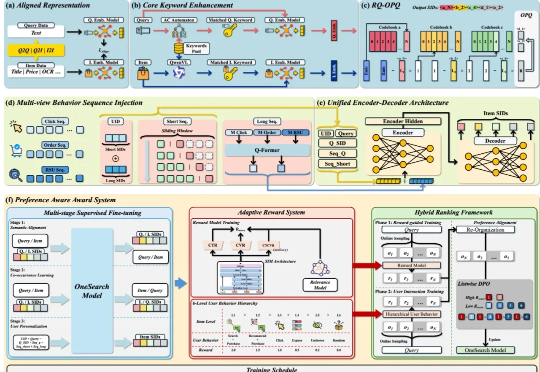
还有一个多月,一年一度的“双十一”购物节就要来了! 作为消费者,你通常会如何寻找心仪的商品呢?或许你兴致勃勃地在搜索框里敲下关键词,却发现呈现出来的商品列表总是差强人意。那么,问题究竟出在哪里?

还在实时视频里找特定事件找半天?最新技术直接开挂了。

9 月 16 日,OpenAI 正式推出一款新模型 GPT-5-Codex ,这是一个经过微调的 GPT-5 变体,专门为其各种 AI 辅助编程工具而设计。该公司表示,新模型 GPT-5-Codex 的“思考”时间比之前的模型更加动态,完成一项编码任务所需的时间从几秒到七个小时不等。因此,它在代理编码基准测试中表现更佳。

无广告的纯净AI体验,可能很快就会成为过去式。

经过数月的外界猜测,CEO Sam Altman揭晓了一款远超预期的全新模型。用他的话来说,与前代的跃升可以这样形容——“GPT-4像是在和一位大学生对话,而GPT-5则是第一次让人真切地感觉在与一位博士级专家交流。”
谷歌的 Nano Banana 甚至被称为 AI 图像生成与编辑领域的「ChatGPT 时刻」,而字节的 Seedream 4.0 则进一步拉低了门槛,让中国用户能以更低的成本进入创作。
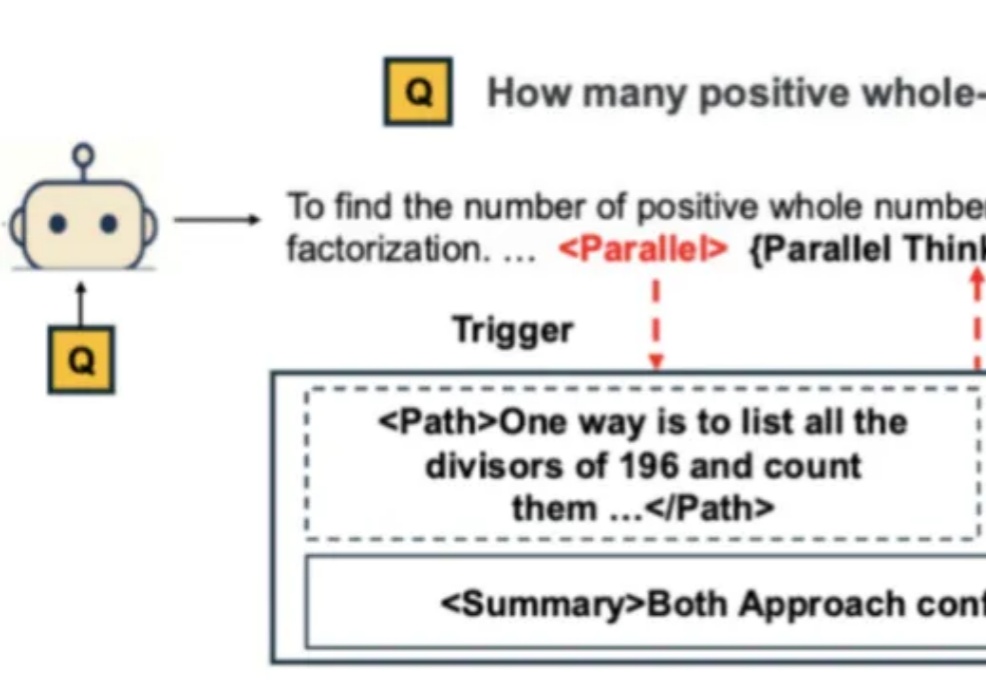
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。

真就一个大写的“哇塞”——智元的灵犀X2,成了全球首个完成韦伯斯特空翻的机器人!要知道,韦伯斯特空翻是空翻里的进阶技巧,属于中高级水平。一般完成这个动作,需要靠一条腿强有力地蹬地,另一条腿摆动带动身体翻转,对腿部爆发力和协调性要求更高。

很多人相信,我们已经进入了所谓的「AI 下半场」,一个模型能力足够强大、应用理应爆发的时代。然而,对于这个时代真正缺少的东西,不同的人有不同的侧重,比如(前)OpenAI 研究者姚顺雨强调了评估的重要性,著名数学家陶哲轩则指出必须降低成本才能实现规模化应用。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
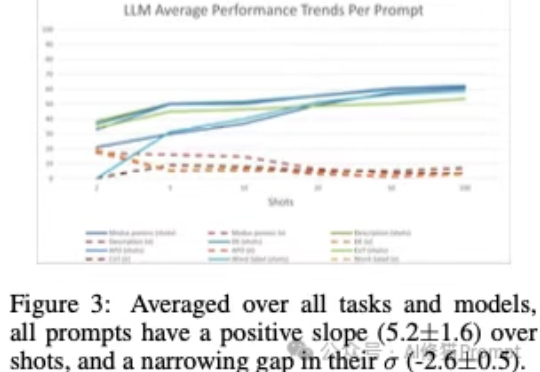
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。

