



16岁创业,22岁做成百亿独角兽!3位高中同学帮大厂训AI年入1亿美金
16岁创业,22岁做成百亿独角兽!3位高中同学帮大厂训AI年入1亿美金Meta豪掷143亿收购Scale AI,意外成就了3名22岁青年的创业神话!他们靠着为OpenAI等顶级AI实验室输送模型专家训练师,干出百亿独角兽Mercor,年入1亿美金。目前,Mercor在《福布斯》Cloud 100 榜单中排名第89位。
来自主题:
AI资讯
6057 点击 2025-09-08 10:10
Meta豪掷143亿收购Scale AI,意外成就了3名22岁青年的创业神话!他们靠着为OpenAI等顶级AI实验室输送模型专家训练师,干出百亿独角兽Mercor,年入1亿美金。目前,Mercor在《福布斯》Cloud 100 榜单中排名第89位。
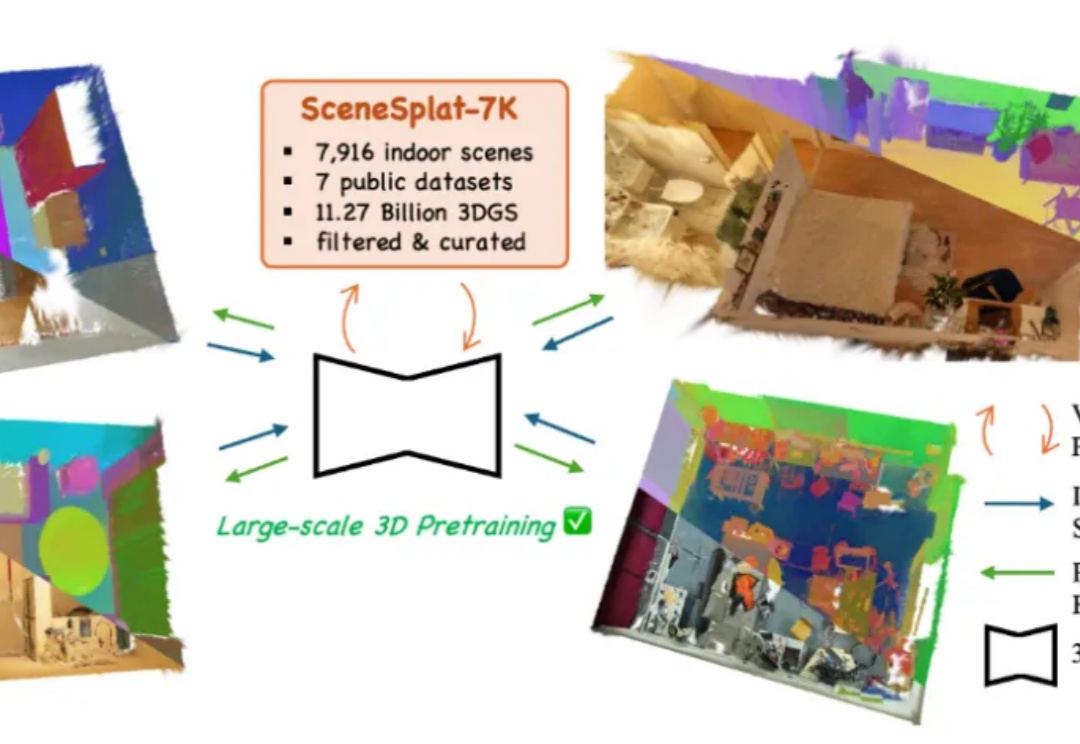
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。
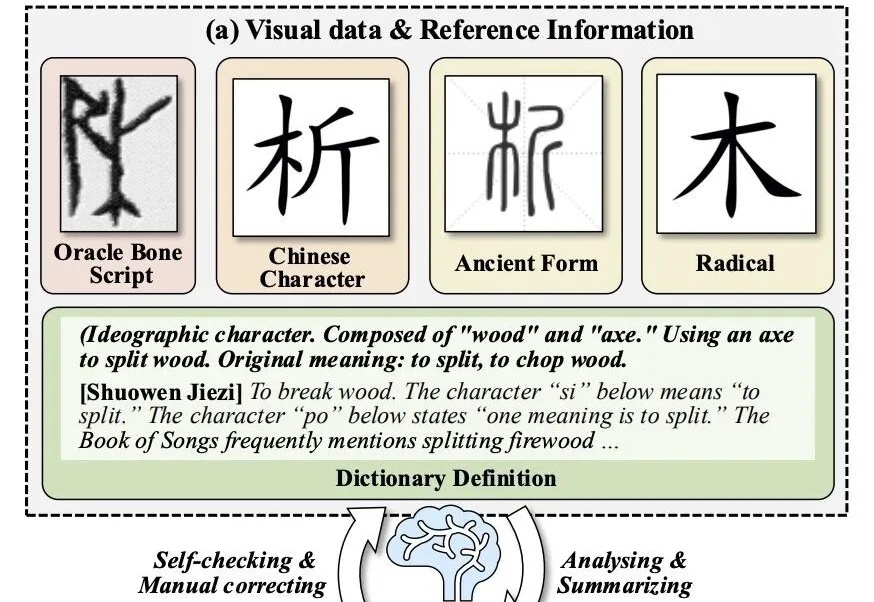
让大模型破译从未见过的甲骨文,准确率拿下新SOTA!

周末在家扒拉上周更新的论文的时候,看到一篇我自己一直非常关心的领域的论文,而且还是来自发论文发的越来越少的OpenAI。
GPT-5,一夜又成为了编码圈的顶流。AI大牛Karpathy发文狂赞,Claude Code折腾一小时没搞定的难题,GPT-5 Pro十分钟就完成了,奥特曼秒回感谢。
总参数达到1万亿,阿里迄今为止最大的模型来了! 没错,就是前几日大家期待已久的Qwen3-Max-Preview (Instruct)。

最新消息,AI 初创公司 Anthropic 同意支付至少 15 亿美元,来和解一起作家集体诉讼案件。此前,这些作家联合指控 Anthropic 盗版了他们的作品来训练其聊天机器人 Claude。

OpenAI重磅结构调整:ChatGPT「模型行为」团队并入Post-Training,前负责人Joanne Jang负责新成立的OAI Labs。而背后原因,可能是他们最近的新发现:评测在奖励模型「幻觉」,模型被逼成「应试选手」。一次组织重组+评测范式重构,也许正在改写AI的能力边界与产品形态。

七岁学音乐,剑桥读硕期间组乐队,Alexander Cobb一度以为音乐是毕生挚爱。但奥特曼的一场演讲,当头一棒,让他醍醐灌顶:果断自学编程搞AI,十个月后投身创业,坚信AI是新的「互联网」,终将掀起第四次工业革命。

Lambda 收入可观,英伟达主导地位稳固,大家都有美好未来 据 The Information 最新消息称,英伟达已经与小型云服务提供商 Lambda 达成一笔总额高达 15 亿美元的合作协议,内容是前者将租赁后者搭载英伟达自研 AI 芯片的 GPU 服务器。

为了降低大模型预训练成本,最近两年,出现了很多新的优化器,声称能相比较AdamW,将预训练加速1.4×到2×。但斯坦福的一项研究,指出不仅新优化器的加速低于宣称值,而且会随模型规模的增大而减弱,该研究证实了严格基准评测的必要性。

机器人终于不用散装大脑了! 字节Seed一个模型就能搞定机器人推理、任务规划和自然语言交互。
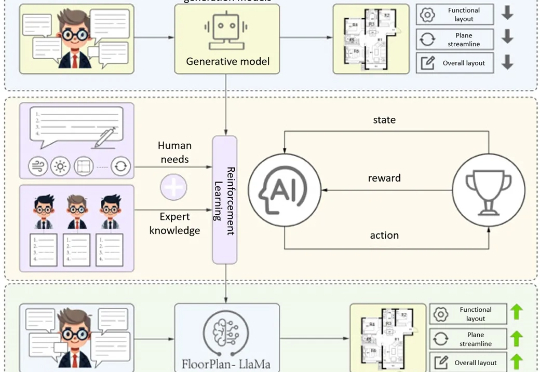
清华大学最新提出的建筑专业知识驱动的平面图自动生成方案FloorPlan-LLaMa,解决传统模型「指标优秀但实际不可用」 痛点,让AI生成贴合建筑师设计偏好的可行方案。

好家伙,我直呼好家伙。 号称「赛博白月光」的 GPT-4o,在它的知识体系里,对日本女优「波多野结衣」的熟悉程度,竟然比中文日常问候语「您好」还要高出 2.6 倍。
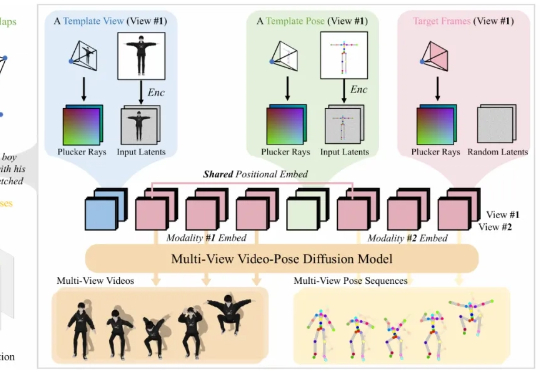
在游戏、影视制作、虚拟人和交互式内容创作等行业中,高质量的 3D 动画是实现真实感与表现力的基础。然而,传统计算机图形学中的动画制作通常依赖于骨骼绑定与关键帧编辑,这一流程虽然能够带来高质量与精细控制,但需要经验丰富的艺术家投入大量人力与时间,代价昂贵。
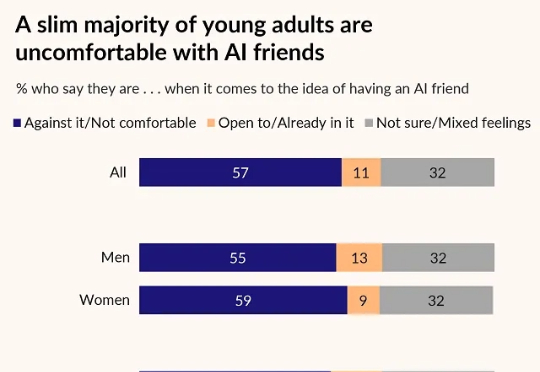
近日,在一项针对2000名40岁以下美国成年人的调研中发现:约11%的年轻人愿意拥有「AI朋友」,约25%的年轻人可以接受与AI谈恋爱;在Character.AI上,模拟治疗师Psychologist创建以来,已收到近亿条用户回复。朋友、爱人、治疗师、导师……越来越多的AI角色渗入我们的生活,或将我们带到一个包含人机共建亲密关系的世界。
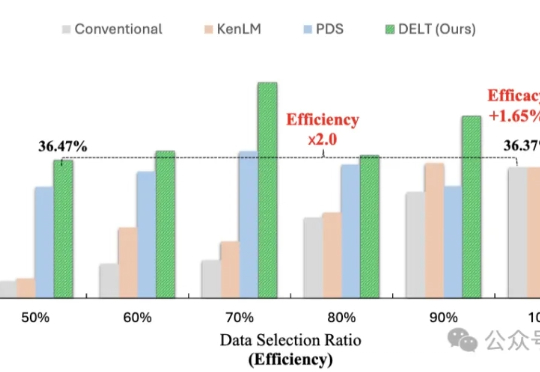
模型训练重点在于数据的数量与质量?其实还有一个关键因素—— 数据的出场顺序。

AI 最臭名昭著的 Bug 是什么?不是代码崩溃,而是「幻觉」—— 模型自信地编造事实,让你真假难辨。这个根本性挑战,是阻碍我们完全信任 AI 的关键障碍。
北京时间9月5日晚,美国AI独角兽Anthropic在其官网发布了一则公告。内容简洁而强硬:其旗下的Claude系列模型,将立即停止向多数股权由中国资本持有的公司提供服务。在熟悉华盛顿政治生态的人看来,这一决绝姿态的背后,与Anthropic创始人达里奥·阿莫迪(Dario Amodei)的个人经历不无关系。

以前,每当上线一个新模型,大家总要绞尽脑汁想个响亮又不撞车的名字。 不得不说,有时候名字起得太出彩,甚至能把模型本身给卷下去。别人还没搞懂它能干嘛,名字已经在朋友圈刷屏了。
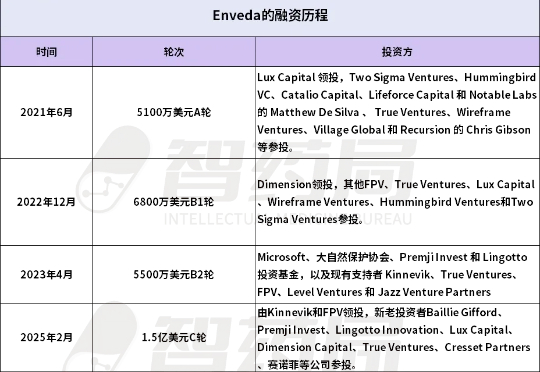
AI制药,一家新独角兽诞生了。 9月4日,AI+生物科技公司Enveda宣布,公司已经完成1.5亿美元的D轮融资,目前估值超过10亿美元。
《金融时报》最新消息,OpenAI 正在和博通合作,自研一颗代号 “XPU” 的 AI 推理芯片,预计会在 2026 年量产,由台积电代工。不同于英伟达 的 GPU,这款芯片不会对外销售,而是专门满足 OpenAI 内部的训练与推理需求,用来支撑即将上线的 GPT-5 等更庞大的模型。
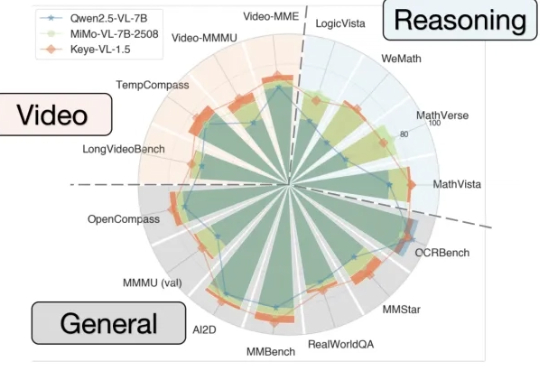
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。

过去几年,人们总担心被AI抢走工作。可现在,OpenAI却宣布要做「AI就业办」:上线就业平台,推出AI技能认证,目标在2030年前让1000万人持证上岗。沃尔玛率先参与,白宫亲自背书。这一次,LinkedIn遇上了最强挑战者。
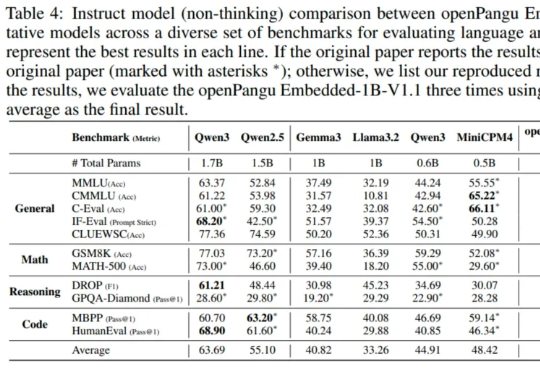
在端侧 AI 这个热门赛道,华为盘古大模型扔下了一颗 “重磅炸弹” 。
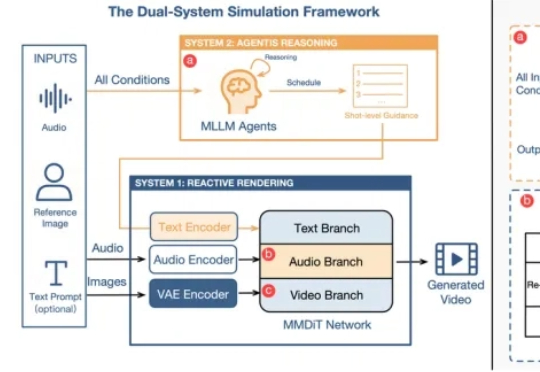
想象一个虚拟人,他不仅能精准地对上你的口型,还能在你讲到关键点时做出恍然大悟的表情,在你讲述悲伤故事时流露出同情的神态,甚至能根据你的话语逻辑做出有意义的手势。

全球第一家被收购的AI浏览器公司诞生了! 刚刚,拥有Arc和Dia两款AI浏览器的The Browser Company,被企业协作软件公司Atlassian以6.1亿美元(约为43亿人民币)重金收购。
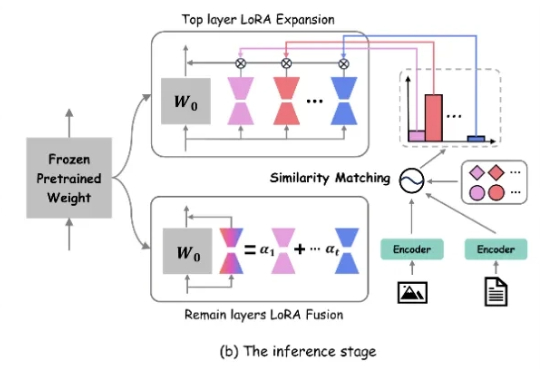
近年来,生成式 AI 和多模态大模型在各领域取得了令人瞩目的进展。然而,在现实世界应用中,动态环境下的数据分布和任务需求不断变化,大模型如何在此背景下实现持续学习成为了重要挑战
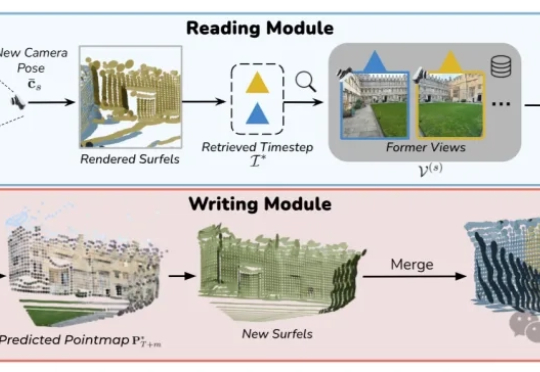
VMem用基于3D几何的记忆索引替代「只看最近几帧」的短窗上下文:检索到的参考视角刚好看过你现在要渲染的表面区域;让模型在小上下文里也能保持长时一致性;实测4.2s/帧,比常规21帧上下文的管线快~12倍。
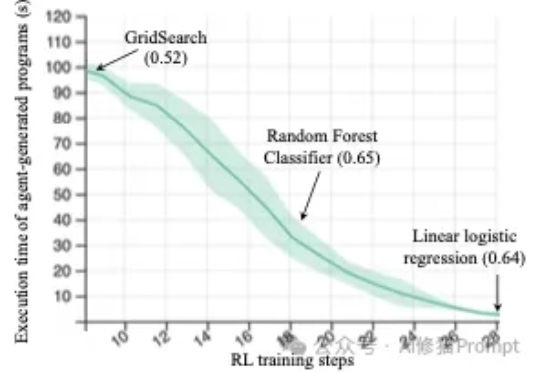
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。

