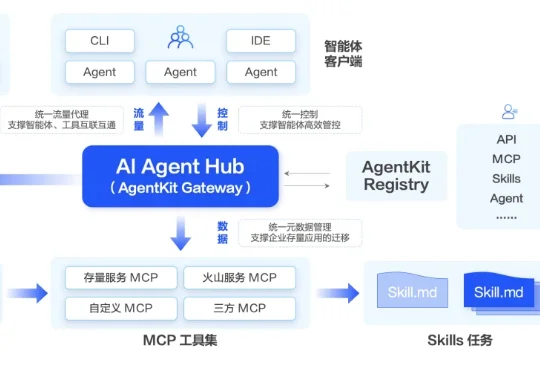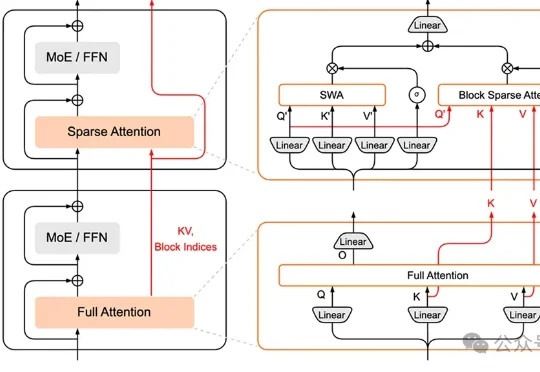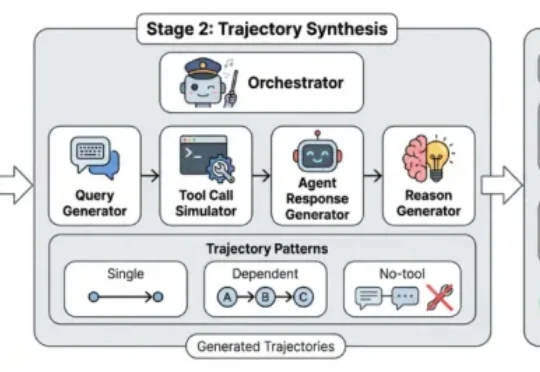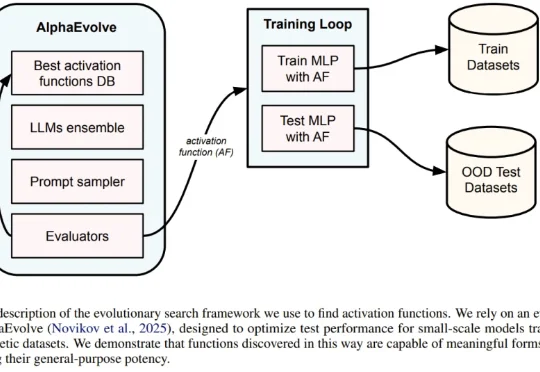
登顶Hugging Face论文热榜,LLM重写数据准备的游戏规则
登顶Hugging Face论文热榜,LLM重写数据准备的游戏规则来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
来自主题:
AI技术研报
8705 点击 2026-02-09 11:12