# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

真正可以叫板GPT-4的模型,当属谷歌Gemini。
Gemini一经放出,强大的多模态能力演示刷屏全网,而GPT-5的话题瞬间也被推上了热搜。

扔掉PaLM 2,谷歌Brad、办公全家桶等全线产品也将脱胎换骨,得到Gemini的加持。
谷歌官方称,Gemini Ultra超大杯将在明年发布。

而在Gemini正式放出之前,就有接触过内部测试的人士评论到,「2023年如果是大模型元年的话,2024年很有可能是Gemini年」。
正如谷歌DeepMind负责人Demis Hassabis所说,Gemini的时代来临了。
据透露,AlphaGo深度强化学习技术正在融入Gemini模型中,2024年的下一版本将会超级进化。

ChatGPT诞生后风头无两,让退居幕后的联合创始人Sergey Brin心急如焚。
7月,他曾被爆出重回公司参与下一代AI系统的研发。

Gemini论文作者列表中,他的名字赫然在列。

https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf

关于60页Gemini技术报告,网友做了一个浓缩版。

1. 用Jax编写,使用TPU进行训练。虽然没有详细解释,但其架构似乎与Flamigo类似。
2. Gemini Pro的性能类似于GPT-3.5,而Gemini Ultra据说优于GPT-4。Nano-1(1.8B 参数)和 Nano-2(3.25B 参数)设计为在终端设备上运行。
3. 32K上下文长度。
4. 非常擅长理解视觉和语音。
5. 编码能力:与GPT-4相比,HumanEval的大幅跃升(74.4% Vs 67%)。不过,Natural2Code基准显示的差距要小得多(74.9% Vs 73.9%)。
6. 关于MMLU:用COT@32(32个样本)来说明Gemini优于GPT-4似乎有些勉强。在5个样本设置中,GPT-4更胜一筹(86.4% Vs 83.7%)。
7. 除了确保「所有数据浓缩工人至少获得当地生活工资」之外,没有关于训练数据的任何信息。
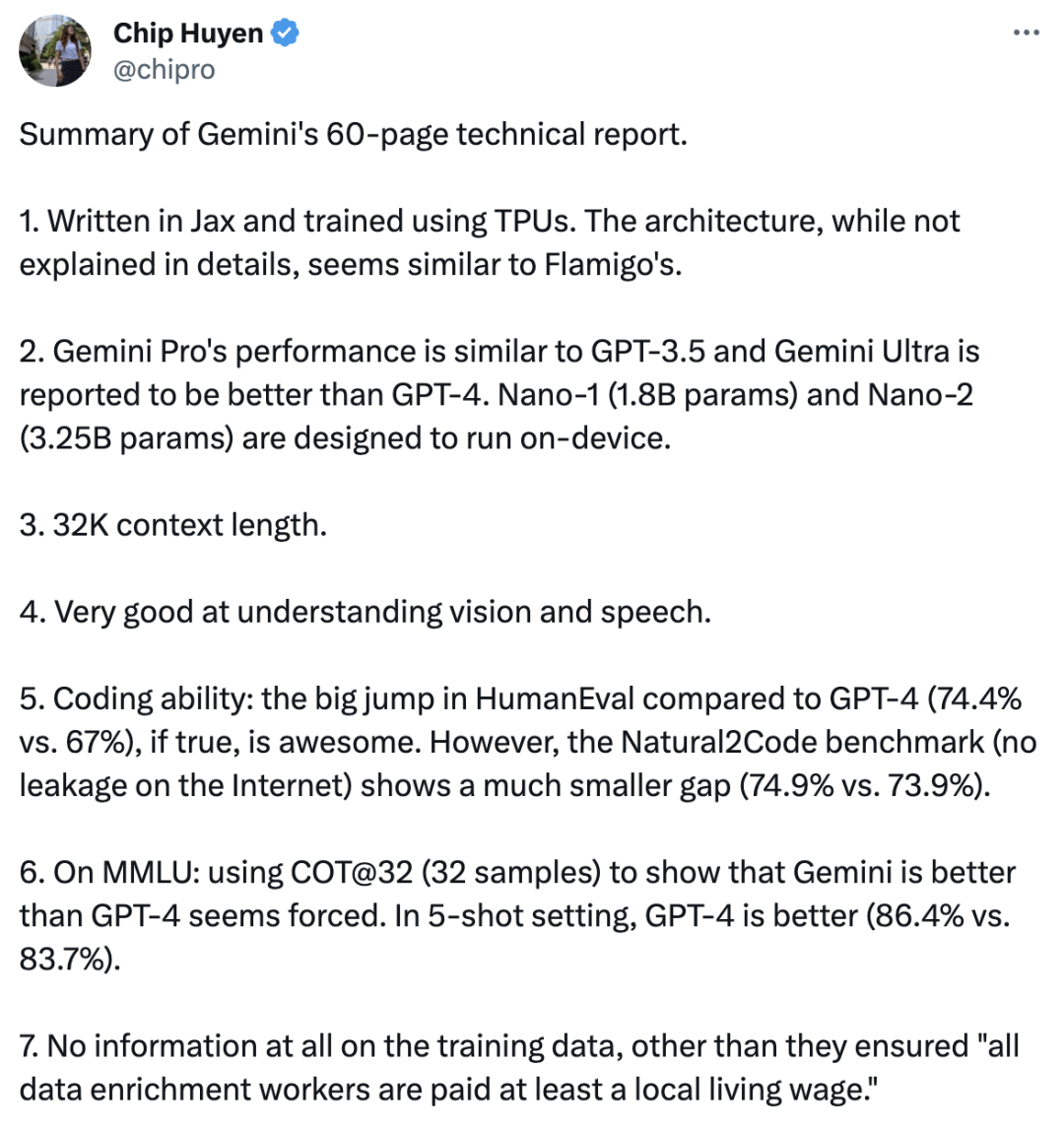
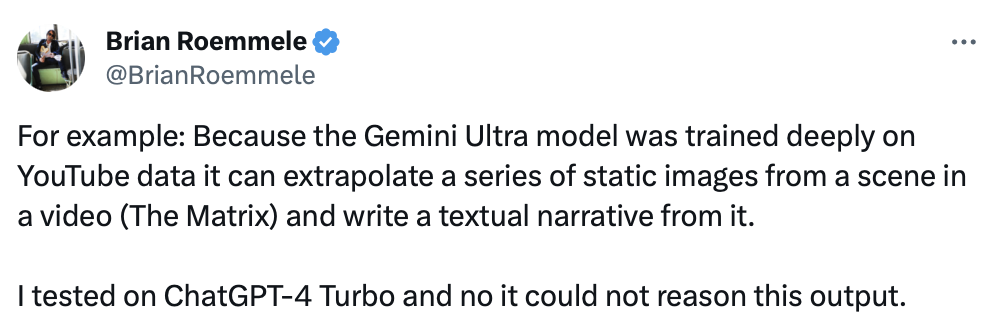
Gemini模型中杯、大杯、超大杯三种体量模型在不同能力上的语言理解和生成性能。
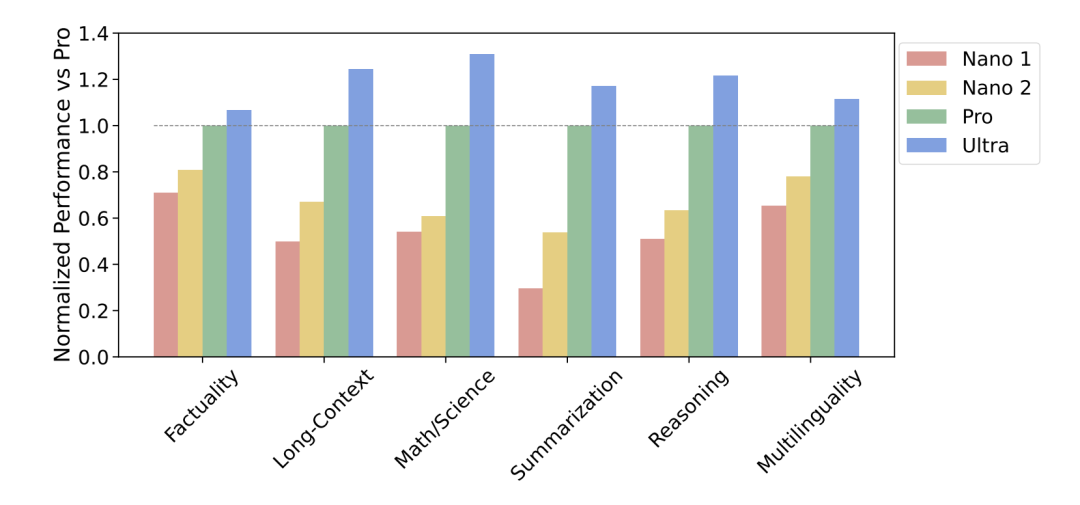
以下几张图,是关键对比数据。
Gemini在文本基准上的性能,与外部模型和PaLM 2-L的比较。
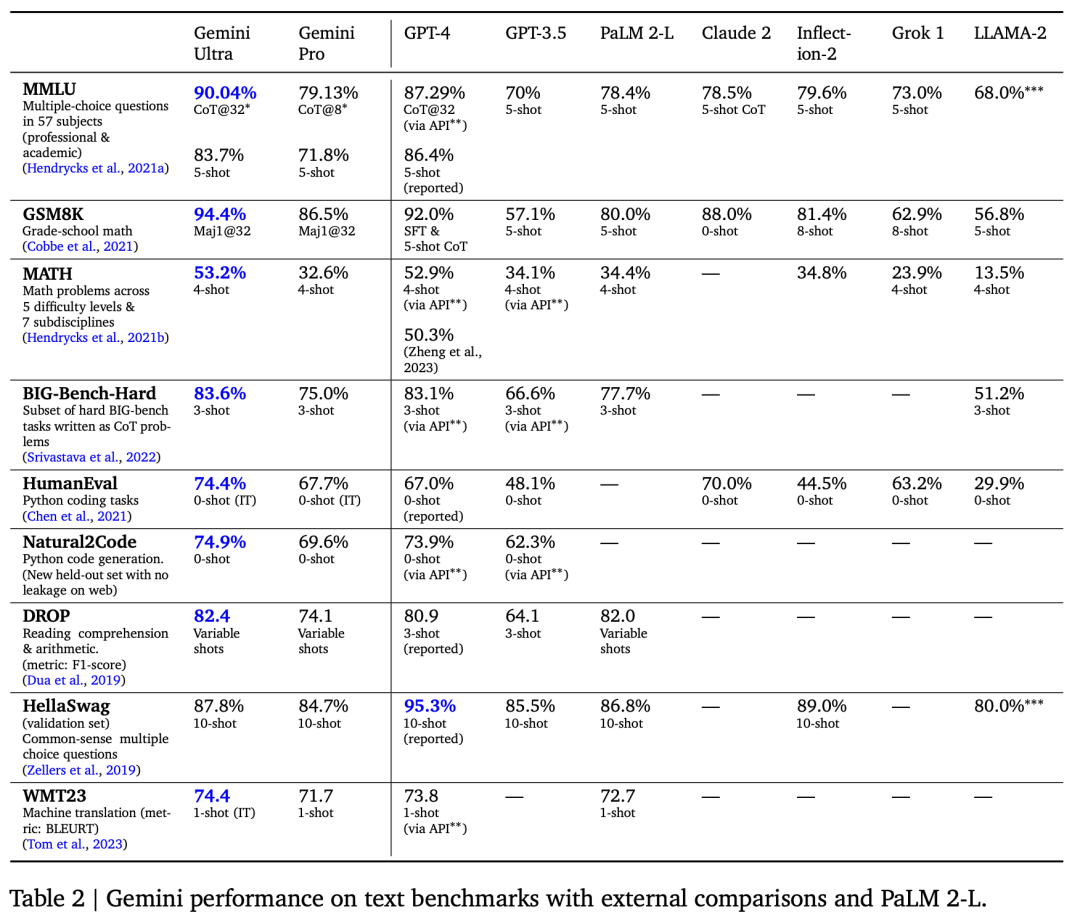
图像理解方面,Gemini Ultra始终优于所有的模型。
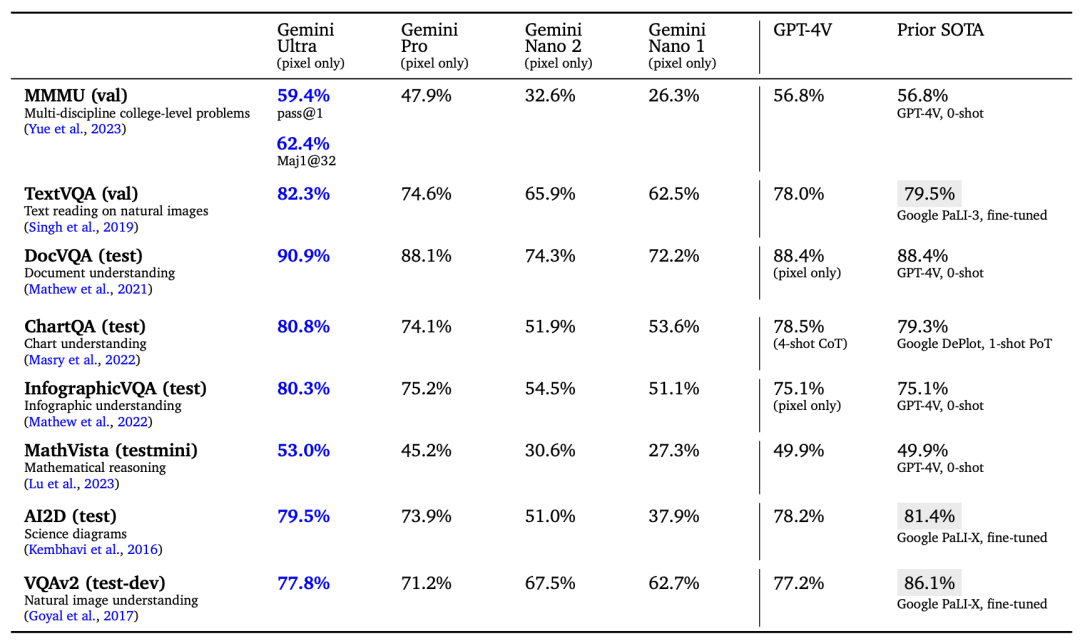
语音基准上的评估结果,Gemini Pro在语音识别,以及自动语音翻译都优于其他模型。
一位开发者Brian Roemmele发现Gemini Ultra确实略胜一筹。
根据技术报告,Gemini Ultra模型是在YouTube数据上进行深度训练的,因此它可以从视频(《黑客帝国》)中的一个场景推断出一系列静态图像,并从中写出文字叙述。
而Roemmele在 ChatGPT-4 Turbo上进行了测试后,发现它无法推理出这样的输出结果。

Gemini Ultra也会以图像和文本相结合的方式做出响应。这就是所谓的「交错文本和图像生成」。
之所以能做到这一点,是因为该模型是在多模态输入的基础上训练出来的。

下面这个便是Gemini Ultra,从毛线球到编织成品文本与图像的生成。

在这个样本中,我们看到Gemini Ultra在执行一项任务时,充分发挥了多模态训练和微调的威力。
这种协同作用的发展规模在目前的人工智能模型中尚属首次。它将多模态与工具使用相结合:画图搜索音乐。


更厉害的是,Gemini Ultra还可以看懂魔术。
Roemmele表示,通过对经典魔术的辨别,可以看到了Gemini统一多模态模型的特点。由于模型中的YouTube视频训练,它可以理解序列并通过逻辑得出结论。

接下来,就是见证奇迹的时刻了。给到一个右手拿硬币的图,让Gemini去描述。

把硬币变没后,Gemini Ultra能够一步步总结刚刚所看的所有过程。


最后,根据逻辑推理出结果。

Reddit一位网友上传了一张截图,他自己称这是在Gemini下实测的结果。
图中是一名高中生解答物理题的过程,他让Gemini对解题过程进行批改,如果有误就让他做出正确答案。
Gemini读出了图中学生解题思路的问题,并且成功做出了答案。
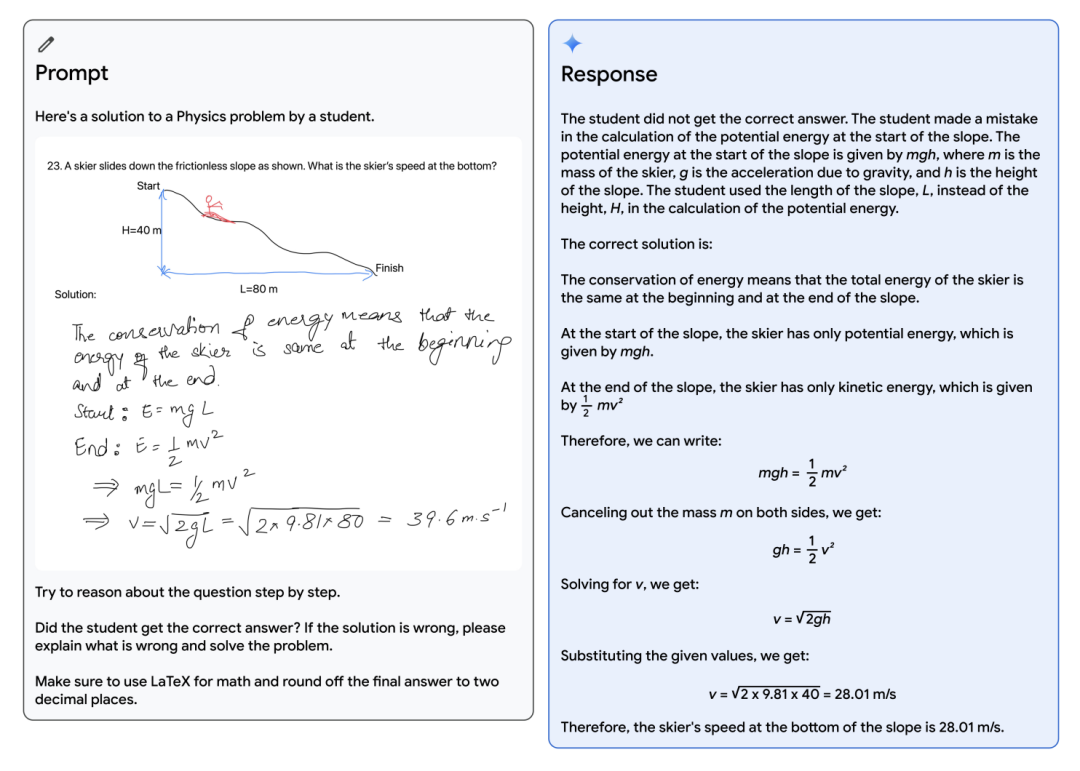
而我们自己在把同一道题给到GPT-4,它第一次尝试回答时,到一半突然「夹住了」。

当要求它重新回答时,GPT-4才正确地判断了学生的解题思路有问题,并给出了正确答案。

而同样的情况在Reddit网友身上也发生了。

而这次谷歌发布的Gemini,不仅仅是对OpenAI用GPT-4定义的「大模型SOTA」的回应,还直接将大模型的战火烧到了移动端,现在压力来到了苹果这边。
Gemini的三个版本Ultra Pro Nano,针对从数据中心到手机都进行了优化,可以应对不同用户在不同使用场景下的各种需求。

Gemini Nano是谷歌为移动设备上任务构建的最高效模型。现在它已经可以在谷歌的Pixel 8 Pro上运行。
作为首款专为Gemini Nano设计的智能手机,Pixel 8 Pro利用谷歌的人工智能Soc Tensor G3的强大功能提供两项扩展功能:记录器中的摘要和Gboard中的智能回复。
在本地运行的Gemini Nano可以让用户的敏感数据不离开离开手机,在没有网络连接的情况下使用大模型能力。
除了现在已经能在Pixel 8 Pro上运行的Gemini Nano之外,未来通过Bard的智能助手功能,Pixel手机可以解锁更强大的Gemini版本。
Gemini Nano现在可以为Pixel 8 Pro 上的录音机中的内容进行AI总结。
用户可以在不联网的情况直接对自己录制的对话、采访、演示等内容的生成摘要。

这个功能就可以帮助用户将之前自己记录下来的冗长内容语音内容快速清晰地梳理出来,便于进一步的使用和整理,不得不说真的非常方便。
在Pixel 8 Pro中,Gemini Nano可以支持Gboard中的智能回复功能。

在手机上的AI模型现在可以在WhatsApp上试用,明年将推出更多应用程序,可以通过对话感知能力提出高质量的回复,节省用户大量的时间。
作为谷歌DeepMind的领导人,Demis Hassabis也是兴奋不已,并表示「Gemini的时代来临了」。

最新Wired的采访中,Hassabis直言道,谷歌今天宣布的人工智能模型Gemini为人工智能开辟了一条未被实践的道路,可能会带来重大的新突破。
「作为一名神经科学家和计算机科学家,多年来我一直想尝试创造一种新一代的人工智能模型。而这些模型的灵感来自我们所有感官互动和理解世界的方式」。
「Gemini是向这种『多模态』模型迈出的一大步」。

他继续道,「到目前为止,大多数模型都是通过训练单独的模块,然后将其拼接在一起,来实现多模态能力」。
「对于某些任务来说,这是可以的,但是在多模态空间中,无法进行深度复杂推理」。
这似乎是在暗指OpenAI的技术。
我们都知道,ChatGPT的多模态能力,是由GPT-4、DALL·E 3、Whisper多个模型组合而实现的。
今年5月的谷歌开发者大会I/O上,劈柴首次官宣,谷歌正在训练一个新的、更强大的PaLM继任者,名为Gemini。

Gemini的命名也有深层的寓意,是为了纪念谷歌大脑和DeepMind两个团队实验室的合体,并向美国宇航局Gemini致敬。
7个月的时间,关于Gemini的各种爆料也是层出不穷。
而现在,谷歌以惊人的速度研发出Gemini,着实在年底之前来了一次重磅反击。
Hassabis说,新模型能够处理不同形式的数据,包括文本之外的数据,这是该项目从一开始就愿景的关键部分。
许多人工智能研究人员认为,能够利用不同格式的数据是自然智能的一项关键能力,而这正是机器所缺乏的。
ChatGPT等AI大模型因从强大的互联网数据中学习,获得了灵活且强大的泛化能力。
但是,尽管ChatGPT和类似的聊天机器人可以用同样的技巧,来讨论或回答有关物理世界的问题,但这种表面上的理解很快就会瓦解。
许多人工智能专家认为,要使机器智能取得重大进步,就需要AI系统在物理现实中赋予身体,即「具身」。
Hassabis表示,谷歌DeepMind已经在研究,如何将Gemini与机器人技术相结合,与世界进行物理互动。
「要实现真正的多模态,你需要包括触觉和触觉反馈。将这些基础型模型应用于机器人技术有很多希望,我们正在大力探索」。
目前,谷歌已经朝着这个方向迈出了一小步。
5月,该公司宣布了一款名为Gato的AI模型,能够学习执行各种任务,包括玩Atari游戏、为图像添加字幕,以及使用机械臂堆叠积木。
今年7月,谷歌RT-2机器人模型,便是通过语言模型来帮助机器人理解和执行动作。

为了让AI智能体更可靠,就需要为其提供动力的算法必须更加智能。
前段时间,OpenAI曾被曝出开发一个名为「Q*」的项目,网友纷纷猜测可能用到了「强化学习」,这是AlphaGo的核心技术。
不过,Hassabis称,谷歌目前正在按照类似的思路进行研究。
AlphaGo的进步有望帮助改善未来模型的规划和推理,就像今天推出的模型一样。我们正在努力进行一些有趣的创新,以将其带入Gemini的未来版本。
「明年,你将会看Gemini超强进化」。
看来,正如网友所说,我们离GPT-5降临的那一天也不远了。

参考资料:
https://twitter.com/sundarpichai/status/1732414873139589372
https://www.wired.com/story/google-deepmind-demis-hassabis-gemini-ai/
文章来自于微信公众号 “新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
