# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI o1和o3模型的秘密,竟传出被中国研究者「破解」?今天,复旦等机构的这篇论文引起了AI社区的强烈反响,他们从强化学习的角度,分析了实现o1的路线图,并总结了现有的「开源版o1」。
就在今天,国内的一篇论文,引得全球AI学者震惊不已。
推上多位网友表示,OpenAI o1和o3模型背后究竟是何原理——这一未解之谜,被中国研究者「发现」了!


注:作者是对如何逼近此类模型进行了理论分析,并未声称已经「破解」了这个问题
实际上,在这篇长达51页的论文中,来自复旦大学等机构的研究人员,从强化学习的角度分析了实现o1的路线图。
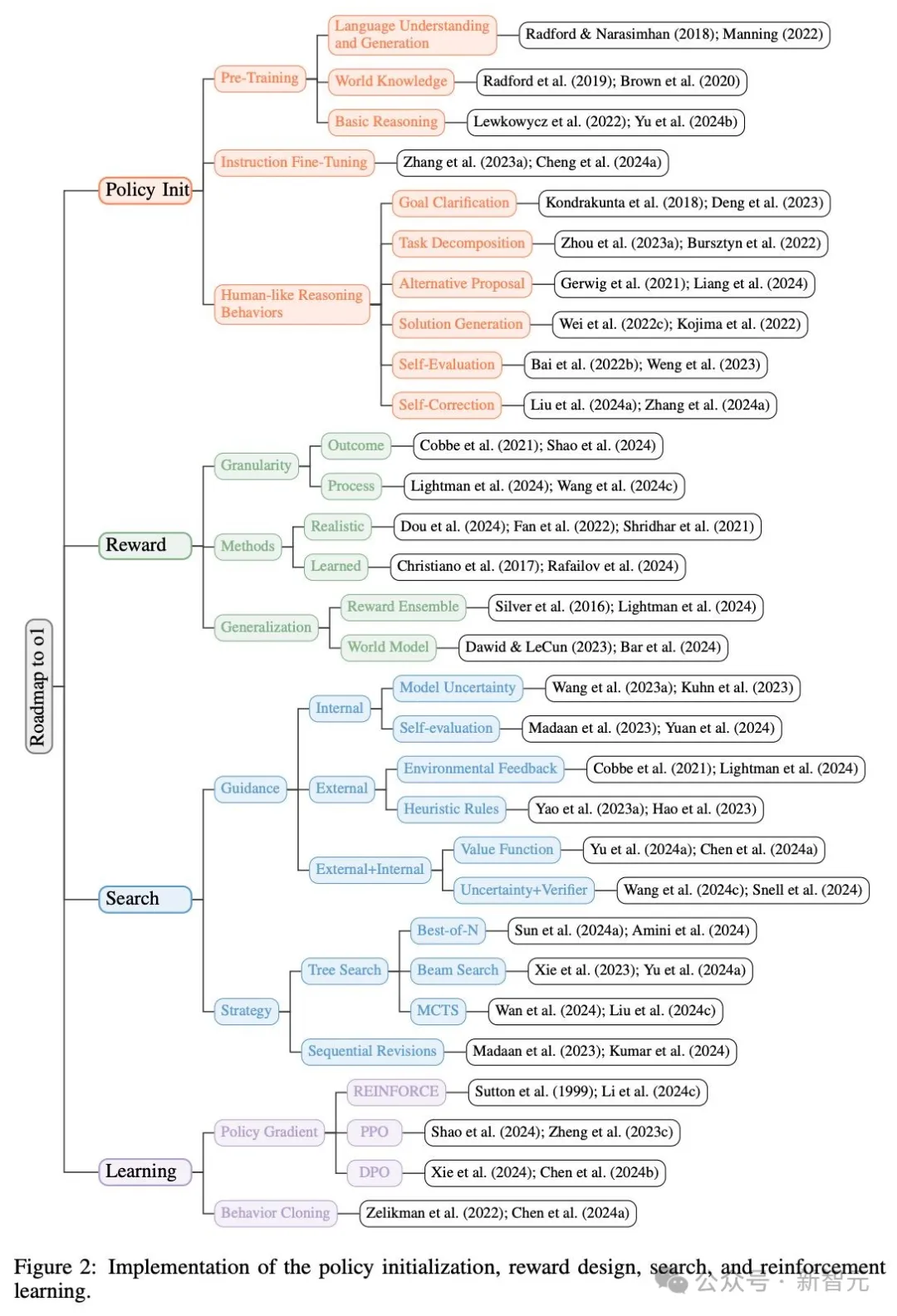
其中,有四个关键部分需要重点关注:策略初始化、奖励设计、搜索和学习。
此外,作为路线图的一部分,研究者还总结出了现有的「开源版o1」项目。

论文地址:https://arxiv.org/abs/2412.14135
概括来说,像o1这样的推理模型,可以被认为是LLM和AlphaGo这类模型的结合。
首先,模型需要通过「互联网数据」进行训练,使它们能够理解文本,并达到一定的智能水平。
然后,再加入强化学习方法,让它们「系统地思考」。
最后,在寻找答案的过程中,模型会去「搜索」解决方案空间。这种方法既用于实际的「测试时」回答,也用于改进模型,即「学习」。

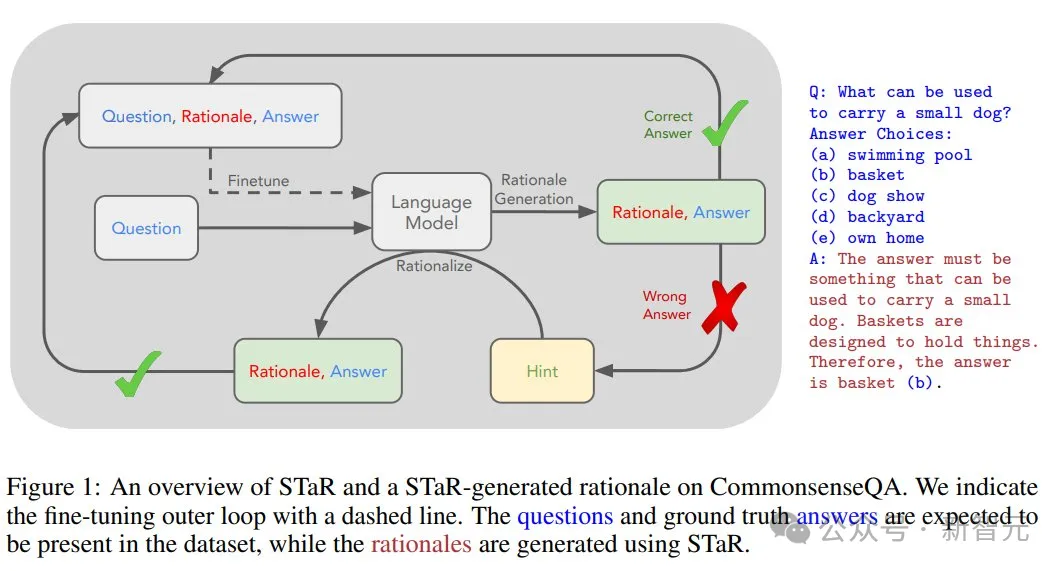
值得一提的是,斯坦福和谷歌在2022年的「STaR: Self-Taught Reasoner」论文中提出,可以利用LLM在回答问题之前生成的「推理过程」来微调未来的模型,从而提高它们回答此类问题的能力。
STaR让AI模型能够通过反复生成自己的训练数据,自我「引导」到更高的智能水平,理论上,这种方法可以让语言模型超越人类水平的智能。
因此,让模型「深入分析解决方案空间」的这一理念,在训练阶段和测试阶段都扮演着关键角色。
在这项工作中,研究者主要从以下四个层面对o1的实现进行了分析:策略初始化、奖励设计、搜索、学习。
策略初始化使模型能够发展出「类人推理行为」,从而具备高效探索复杂问题解空间的能力。
奖励设计则通过奖励塑造或建模提供密集有效的信号,指导模型的学习和搜索过程。
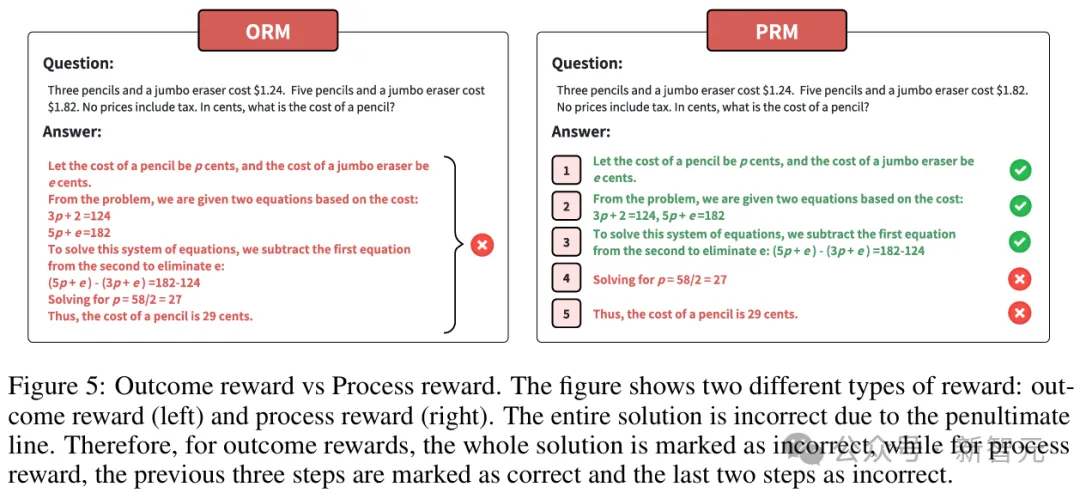
结果奖励(左)和过程奖励(右)
搜索在训练和测试中都起着至关重要的作用,即通过更多计算资源可以生成更优质的解决方案。
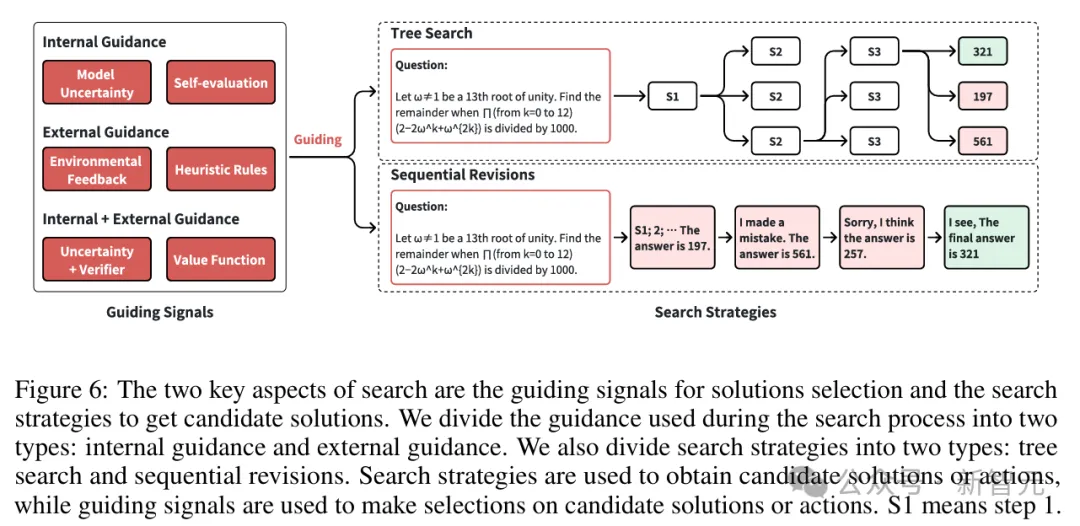
搜索过程中使用的指导类型:内部指导、外部指导,以及两者的结合
从人工专家数据中学习需要昂贵的数据标注。相比之下,强化学习通过与环境的交互进行学习,避免了高昂的数据标注成本,并有可能实现超越人类的表现。

综上,正如研究者们在2023年11月所猜测的,LLM下一个突破,很可能就是与谷歌Deepmind的Alpha系列(如AlphaGo)的某种结合。
对此,有网友表示,这项研究的意义绝不仅仅是发表了一篇论文,它还为大多数模型打开了大门,让其他人可以使用RL来实现相同的概念,提供不同类型的推理反馈,同时还开发了AI可以使用的剧本和食谱。

研究者总结道,尽管o1尚未发布技术报告,但学术界已经提供了多个o1的开源实现。
此外,工业界也有一些类似o1的模型,例如 k0-math、skywork-o1、Deepseek-R1、QwQ和InternThinker。
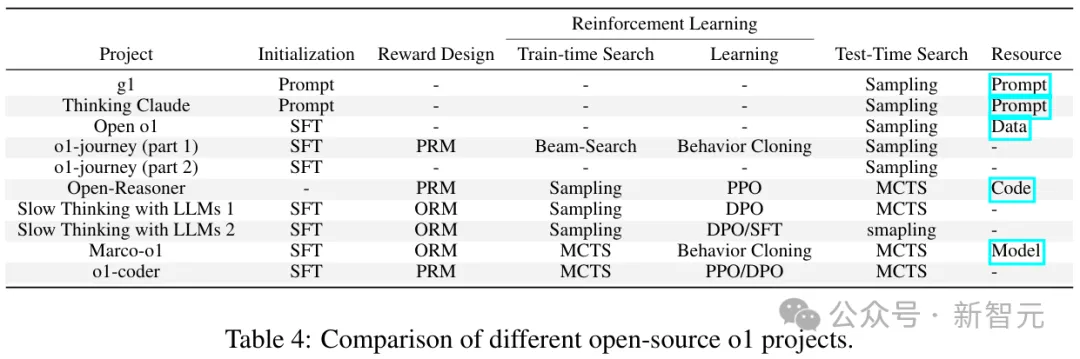
不同开源o1项目在策略初始化、奖励设计、搜索和学习领域的方法对比
在强化学习中,策略定义了智能体如何根据环境状态选择行动。
其中,LLM的动作粒度分为三种级别:解决方案级别、步骤级别和Token级别。
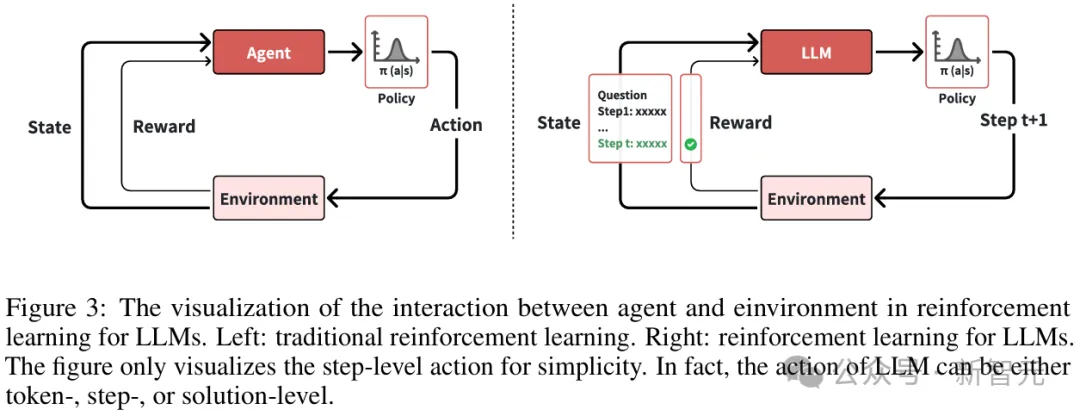
智能体与环境在LLM强化学习中的交互过程
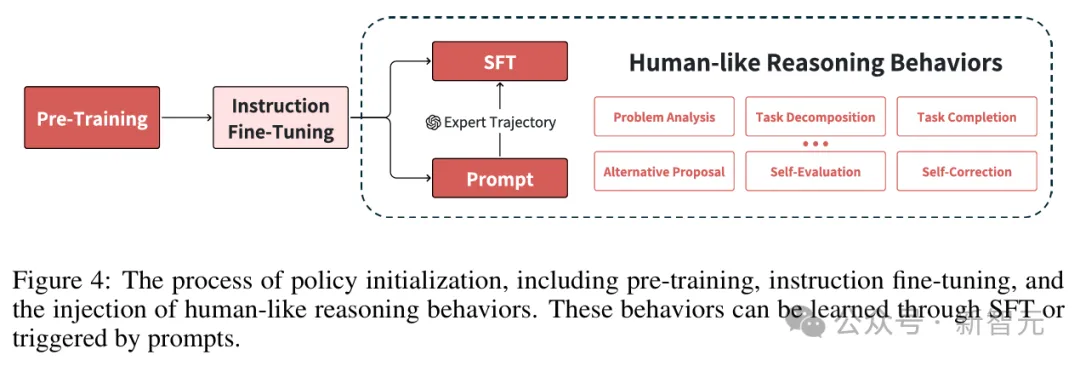
对于LLM的初始化过程,主要包括两个阶段:预训练和指令微调。
在预训练阶段,模型通过大规模网络语料库的自监督学习,发展出基本的语言理解能力,并遵循计算资源与性能之间的既定幂律规律。
在指令微调阶段,则是将LLM从简单的下一个Token预测,转变为生成与人类需求一致的响应。
对于像o1这样的模型,融入类人推理行为对于更复杂的解决方案空间探索至关重要。
预训练通过大规模文本语料库的接触,为LLM建立基本的语言理解和推理能力。
对于类似o1的模型,这些核心能力是后续学习和搜索中发展高级行为的基础。
指令微调通过在多领域的指令-响应对上进行专门训练,将预训练语言模型转变为面向任务的智能体。
这一过程将模型的行为从单纯的下一个Token预测,转变为具有明确目的的行为。
效果主要取决于两个关键因素:指令数据集的多样性和指令-响应对的质量。
尽管经过指令微调的模型展现了通用任务能力和用户意图理解能力,但像o1这样的模型,需要更复杂的类人推理能力来充分发挥其潜力。
如表1所示,研究者对o1的行为模式进行了分析,识别出六种类人推理行为。

策略初始化在开发类似o1的模型中起到了关键作用,因为它建立了影响后续学习和搜索过程的基础能力。
策略初始化阶段包括三个核心组成部分:预训练、指令微调以及类人推理行为的开发。
尽管这些推理行为在指令微调后的LLM中已隐性存在,但其有效部署需要通过监督微调或精心设计的提示词来激活。
在强化学习中,智能体从环境中接收奖励反馈信号,并通过改进策略来最大化其长期奖励。
奖励函数通常表示为r(st, at),表示智能体在时间步t的状态st下执行动作at所获得的奖励。
奖励反馈信号在训练和推理过程中至关重要,因为它通过数值评分明确了智能体的期望行为。
结果奖励与过程奖励
结果奖励是基于LLM输出是否符合预定义期望来分配分数的。但由于缺乏对中间步骤的监督,因此可能会导致LLM生成错误的解题步骤。
与结果奖励相比,过程奖励不仅为最终步骤提供奖励信号,还为中间步骤提供奖励。尽管展现了巨大的潜力,但其学习过程比结果奖励更具挑战性。
由于结果奖励可以被视为过程奖励的一种特殊情况,许多奖励设计方法可以同时应用于结果奖励和过程奖励的建模。
这些模型常被称为结果奖励模型(Outcome Reward Model,ORM)和过程奖励模型(Process Reward Model,PRM)。
在某些环境中,奖励信号可能无法有效传达学习目标。
在这种情况下,可以通过奖励塑造(reward shaping)对奖励进行重新设计,使其更丰富且更具信息量。
然而,由于价值函数依赖于策略π,从一种策略估计的价值函数可能并不适合作为另一种策略的奖励函数。
鉴于o1能够处理多任务推理,其奖励模型可能结合了多种奖励设计方法。
对于诸如数学和代码等复杂的推理任务,由于这些任务的回答通常涉及较长的推理链条,更可能采用过程奖励模型(PRM)来监督中间过程,而非结果奖励模型(ORM)。
当环境中无法提供奖励信号时,研究者推测,o1可能依赖于从偏好数据或专家数据中学习。
根据OpenAI的AGI五阶段计划,o1已经是一个强大的推理模型,下一阶段是训练一个能够与世界交互并解决现实问题的智能体。
为了实现这一目标,需要一个奖励模型,为智能体在真实环境中的行为提供奖励信号。
对于像o1这样旨在解决复杂推理任务的模型,搜索可能在训练和推理过程中都发挥重要作用。
基于内部指导的搜索不依赖于来自外部环境或代理模型的真实反馈,而是通过模型自身的状态或评估能力来引导搜索过程。
外部指导通常不依赖于特定策略,仅依赖于与环境或任务相关的信号来引导搜索过程。
同时,内部指导和外部指导可以结合起来引导搜索过程,常见的方法是结合模型自身的不确定性与来自奖励模型的代理反馈。
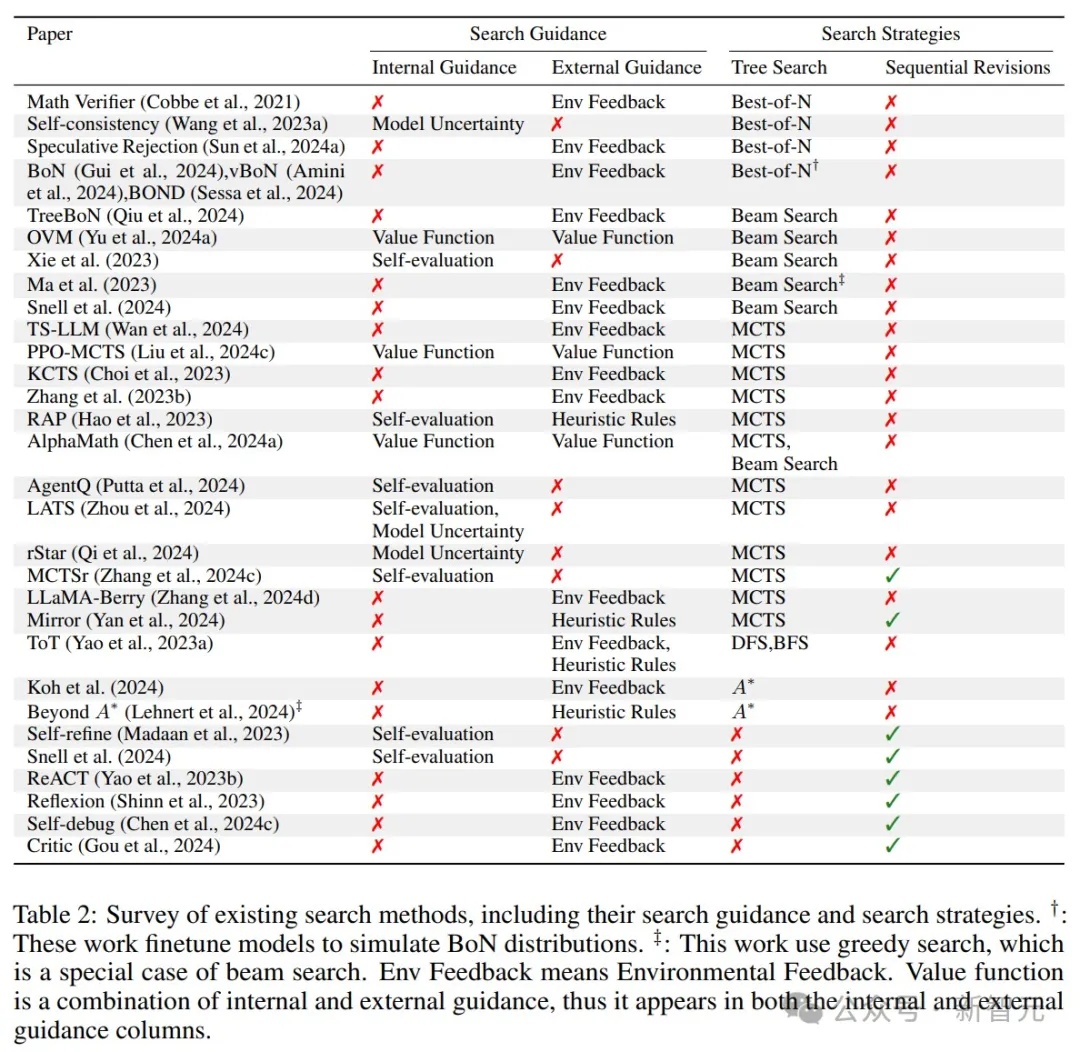
研究者将搜索策略分为两种类型:树搜索和序列修正。
树搜索是一种全局搜索方法,同时生成多个答案,用于探索更广泛的解决方案范围。
相比之下,序列修正是一种局部搜索方法,基于先前结果逐步优化每次尝试,可能具有更高的效率。
树搜索通常适用于复杂问题的求解,而序列修正更适合快速迭代优化。
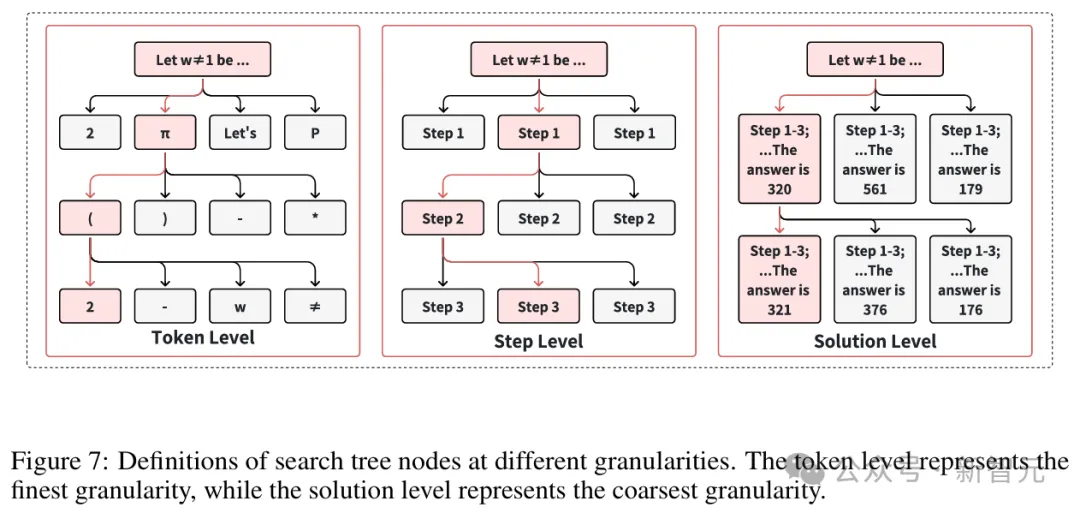
研究者认为,搜索在o1的训练和推理过程中,都起着至关重要的作用。
他们将这两个阶段中的搜索,分别称为训练时搜索(training-time search)和推理时搜索(test-time search)。
在训练阶段,在线强化学习中的试错过程也可以被视为一种搜索过程。
在推理阶段,o1表明,通过增加推理计算量和延长思考时间可以持续提高模型性能。
研究者认为,o1的「多思考」方式可以被视为一种搜索,利用更多的推理计算时间来找到更优的答案。
从o1博客中的示例可以看出,o1的推理风格更接近于序列修正。种种迹象表明,o1在推理阶段主要依赖内部指导。
强化学习通常使用策略对轨迹进行采样,并基于获得的奖励来改进策略。
在o1的背景下,研究者假设强化学习过程通过搜索算法生成轨迹,而不仅仅依赖于采样。
基于这一假设,o1的强化学习可能涉及一个搜索与学习的迭代过程。
在每次迭代中,学习阶段利用搜索生成的输出作为训练数据来增强策略,而改进后的策略随后被应用于下一次迭代的搜索过程中。
训练阶段的搜索与测试阶段的搜索有所不同。
研究者将搜索输出的状态-动作对集合记为D_search,将搜索中最优解决方案的状态-动作对集合记为D_expert。因此,D_expert是D_search 的一个子集。
给定D_search,可通过策略梯度方法或行为克隆来改进策略。
近端策略优化(PPO)和直接策略优化 DPO)是LLM中最常用的强化学习技术。此外,在搜索数据上执行行为克隆或监督学习也是常见做法。
研究者认为,o1的学习可能是多种学习方法结合的结果。
在这一框架中,他们假设o1的学习过程从使用行为克隆的预热阶段开始,当行为克隆的改进效果趋于稳定后,转向使用PPO或DPO。
这一流程与LLama2和LLama3中采用的后训练策略一致。

在预训练阶段,损失、计算成本、模型参数和数据规模之间的关系,是遵循幂律Scaling Law的。那么,对于强化学习,是否也会表现出来呢?
根据OpenAI的博客,推理性能与训练时间计算量,确实呈对数线性关系。然而,除了这一点之外,相关研究并不多。
为了实现像o1这样的大规模强化学习,研究LLM强化学习的Scaling Law至关重要。
参考资料:
https://x.com/MatthewBerman/status/1875202596350415332
https://x.com/WesRothMoney/status/1875051479180165489
https://arxiv.org/abs/2412.14135
文章来自于“新智元”,作者“Aeneas 好困”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
