# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

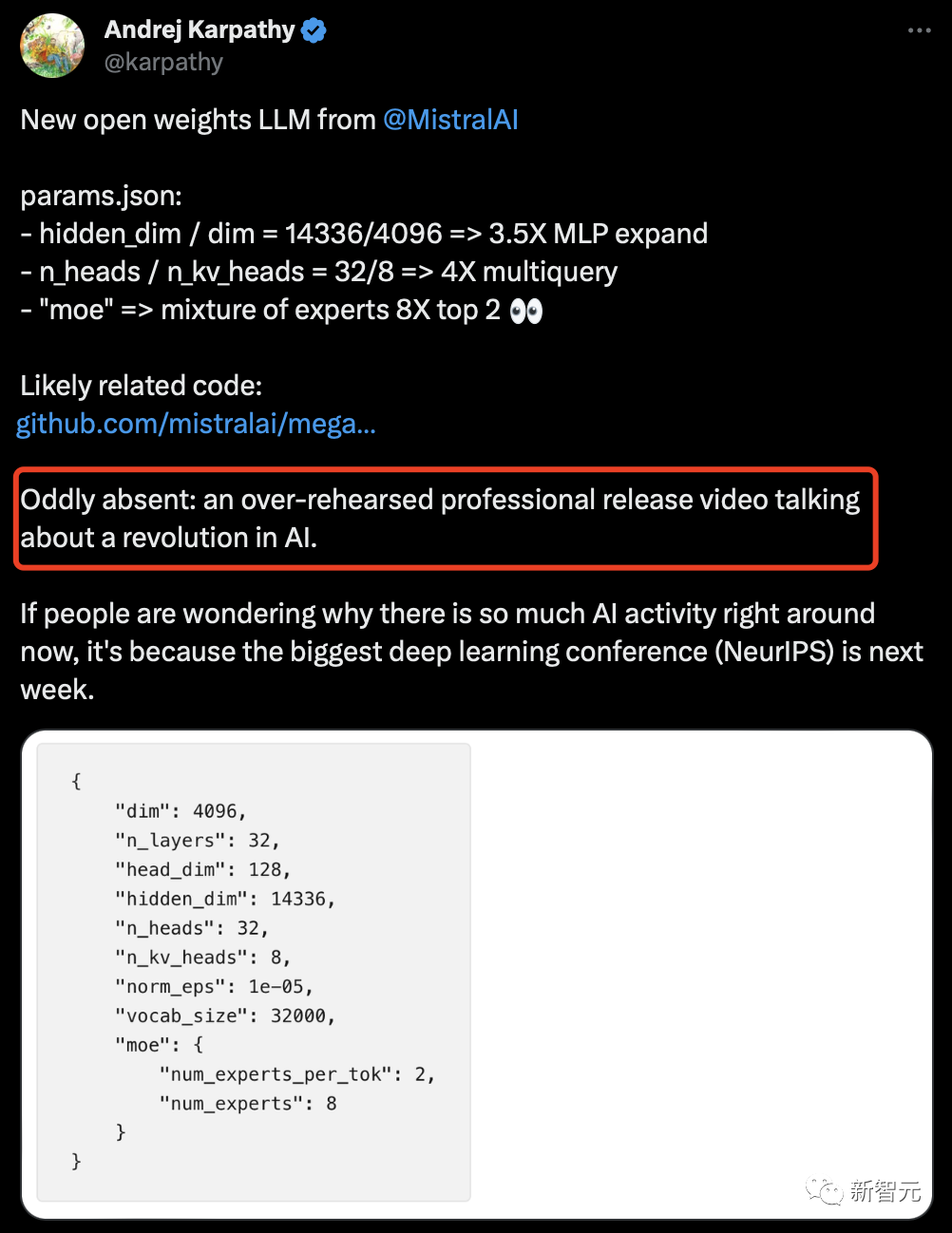
开源奇迹再一次上演:Mistral AI发布了首个开源MoE大模型。
几天前,一条磁力链接,瞬间震惊了AI社区。
87GB的种子,8x7B的MoE架构,看起来就像一款mini版「开源GPT-4」!
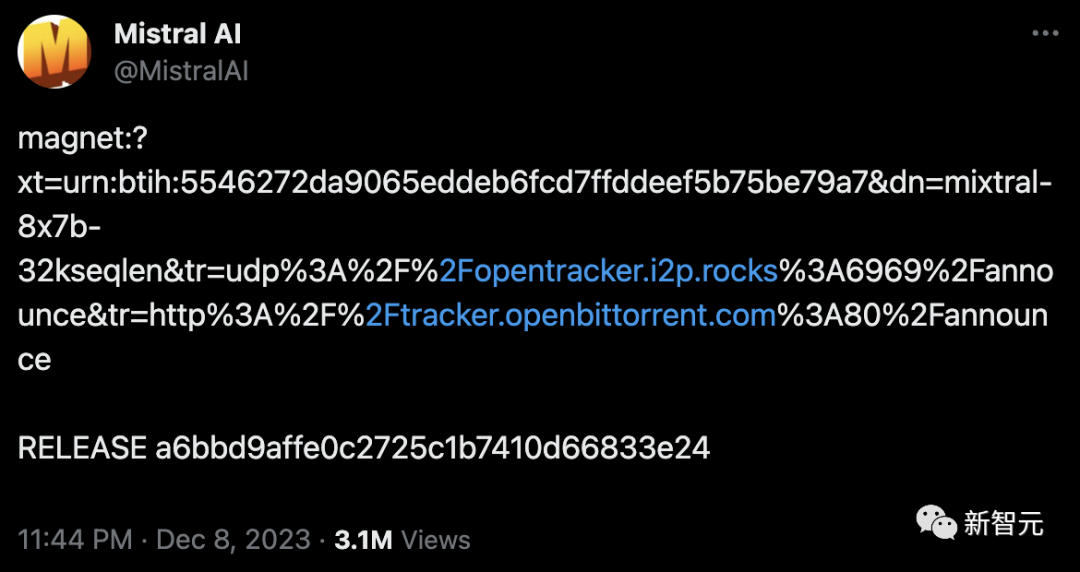
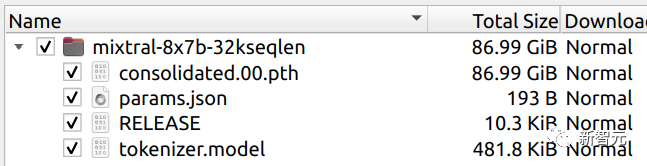
无发布会,无宣传视频,一条磁力链接,就让开发者们夜不能寐。
这家成立于法国的AI初创公司,在开通官方账号后仅发布了三条内容。
6月,Mistral AI上线。7页PPT,获得欧洲历史上最大的种子轮融资。
9月,Mistral 7B发布,号称是当时最强的70亿参数开源模型。
12月,类GPT-4架构的开源版本Mistral 8x7B发布。几天后,外媒金融时报公布Mistral AI最新一轮融资4.15亿美元,估值高达20亿美元,翻了8倍。
如今20多人的公司,创下了开源公司史上最快增长纪录。

所以,闭源大模型真的走到头了?
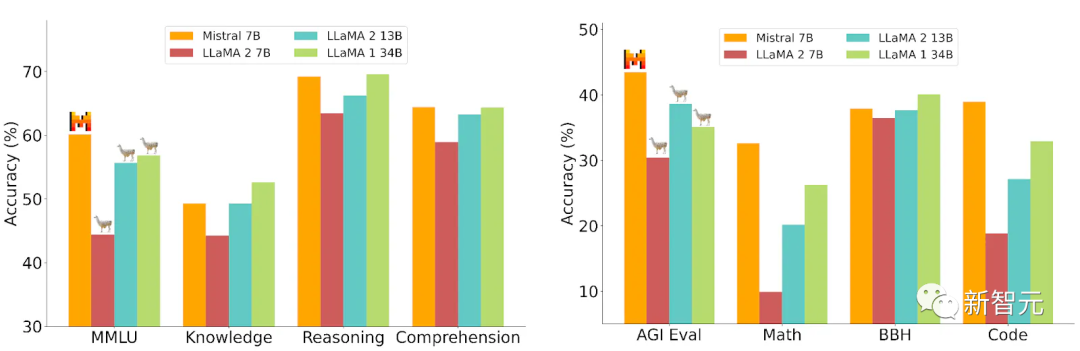
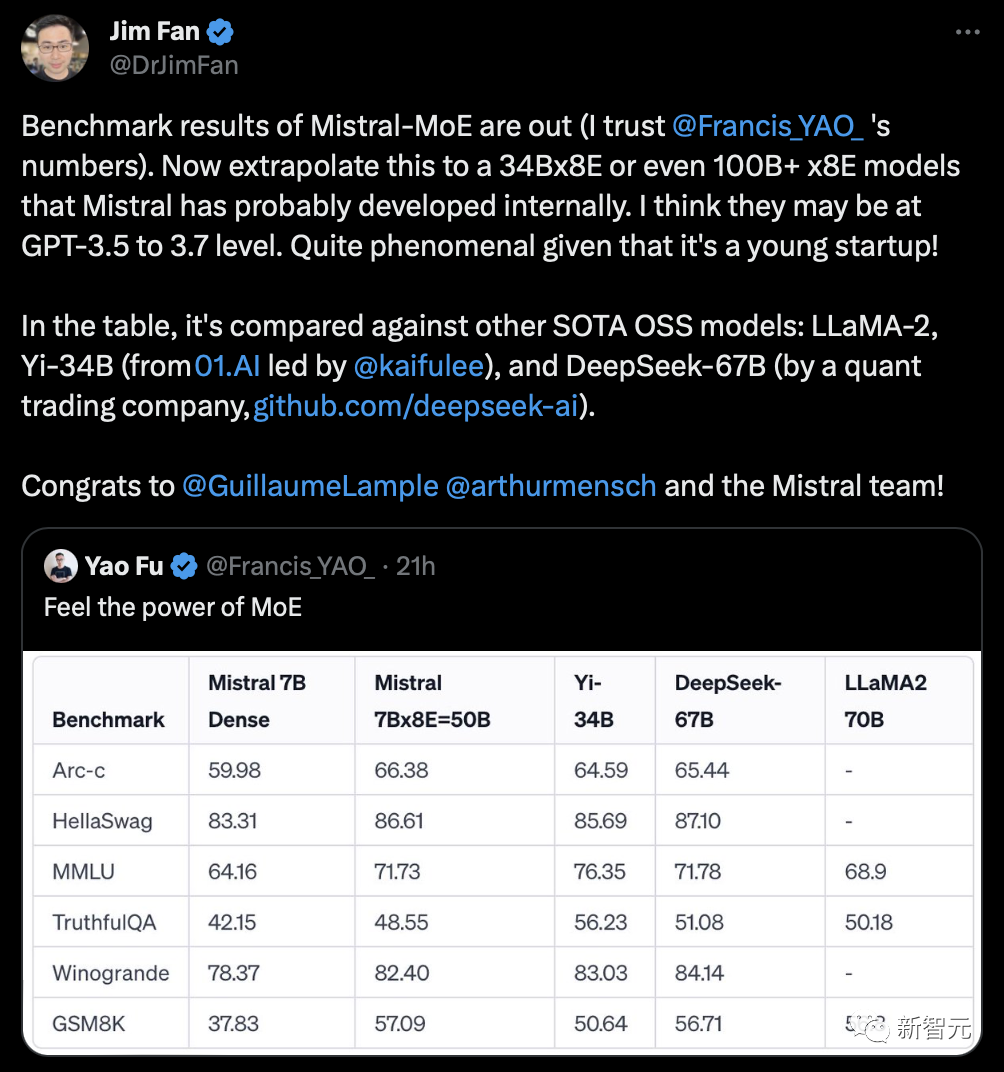
更令人震惊的是,就在刚刚,Mistral-MoE的基准测试结果出炉——
可以看到,这8个70亿参数的小模型组合起来,直接在多个跑分上超过了多达700亿参数的Llama 2。

来源:OpenCompass
英伟达高级研究科学家Jim Fan推测,Mistral可能已经在开发34Bx8E,甚至100B+x8E的模型了。而它们的性能,或许已经达到了GPT-3.5/3.7的水平。
这里简单介绍一下,所谓专家混合模型(MoE),就是把复杂的任务分割成一系列更小、更容易处理的子任务,每个子任务由一个特定领域的「专家」负责。
1. 专家层:这些是专门训练的小型神经网络,每个网络都在其擅长的领域有着卓越的表现。
2. 门控网络:这是MoE架构中的决策核心。它负责判断哪个专家最适合处理某个特定的输入数据。门控网络会计算输入数据与每个专家的兼容性得分,然后依据这些得分决定每个专家在处理任务中的作用。
这些组件共同作用,确保适合的任务由合适的专家来处理。门控网络有效地将输入数据引导至最合适的专家,而专家们则专注于自己擅长的领域。这种合作性训练使得整体模型变得更加多功能和强大。

有人在评论区发出灵魂拷问:MoE是什么?
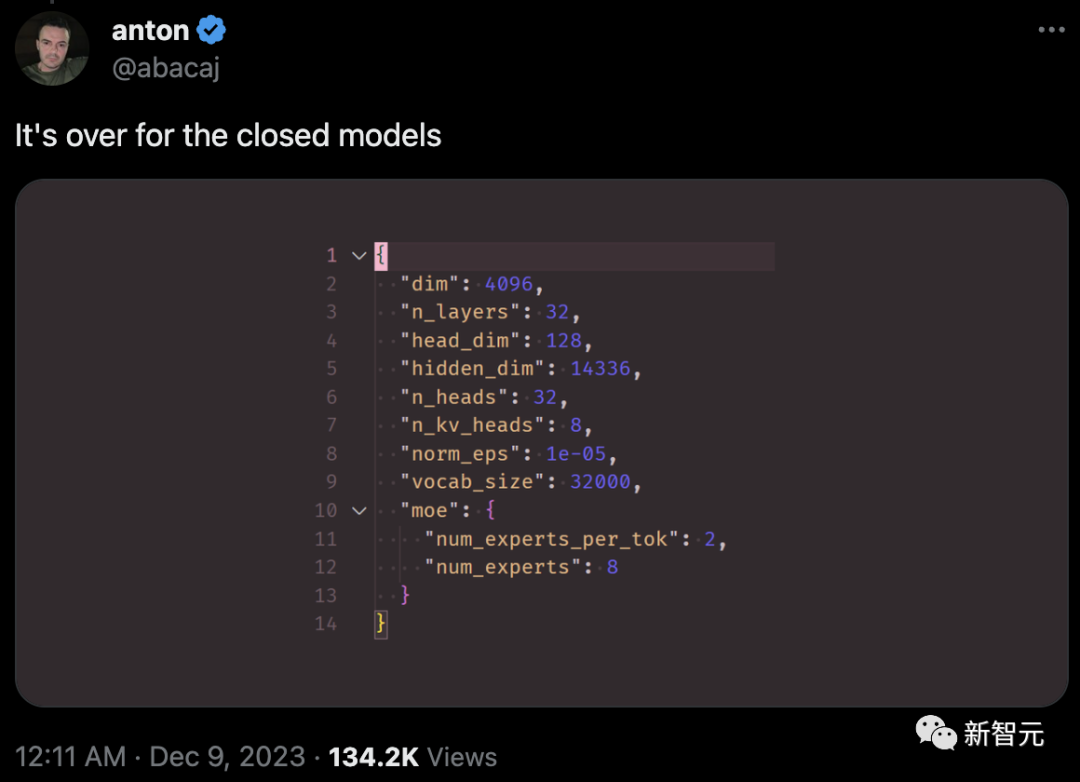
根据网友分析,Mistral 8x7B在每个token的推理过程中,只使用了2个专家。
以下是从模型元数据中提取的信息:
{"dim": 4096, "n_layers": 32, "head_dim": 128, "hidden_dim": 14336, "n_heads": 32, "n_kv_heads": 8, "norm_eps": 1e-05, "vocab_size": 32000, "moe": {"num_experts_per_tok": 2, "num_experts": 8}
与GPT-4(网传版)相比,Mistral 8x7B具有类似的架构,但在规模上有所缩减:
- 专家数量为8个,而不是16个(减少了一半)
- 每个专家拥有70亿参数,而不是1660亿(减少了约24倍)
- 总计420亿参数(估计值),而不是1.8万亿(减少了约42倍)
- 与原始GPT-4相同的32K上下文窗口

此前曾曝出,GPT-4很可能是由8个或者是16个MoE构成
目前,已经有不少开源模型平台上线了Mistral 8×7B,感兴趣的读者可以亲自试一试它的性能。
LangSmith:https://smith.langchain.com/
Perplexity Labs:https://labs.perplexity.ai/
OpenRouter:https://openrouter.ai/models/fireworks/mixtral-8x7b-fw-chat
网友惊呼,Mistral AI才是OpenAI该有的样子!

有人表示,这个基准测试结果,简直就是初创公司版本的超级英雄故事!
无论是Mistral和Midjourney,显然已经破解了密码,接下来,要超越GPT-4只是问题。

深度学习大牛Sebastian Raschka表示,基准测试中最好再加入Zephyr 7B这一列,因为它是基于Mistral 7B的。这样,我们就可以直观地看出Mistral微调和Mistral MoE的对比。

有人表示质疑:这些指标主要是对基础模型有意义,而不是对聊天/指令微调。
Raschka回答说,没错,但这仍然可以看作是一种健全性检测,因为指令微调经常会损害模型的知识,以及基于QA的性能。
对于指令微调模型,添加MT-Bench和AlpacaEval等对话基准测试是有意义的。
并且,Raschka也强调,自己只是假设Mistral MoE没有经过指令微调,现在急需一份paper。
而且,Raschka也怀疑道:Mistral MoE真的能超越Llama 2 7B吗?
几个月前就有传言,说原始的Mistra 7B模型可能在基准数据集上进行了训练,那么这次的Mistral 8x7B是否也是如此?
软件工程师Anton回答说,我们也并不能确定GPT-4没有在基准测试上训练。考虑到Mistral团队是前Llama的作者,希望他们能避免污染的问题。
Raschka表示,非常希望研究界为这些LLM组织一场Kaggle竞赛,其中一定要有包含尚未使用数据的全新基准数据集。
也有人讨论到,所以现在大模型的瓶颈究竟是什么?是数据,计算,还是一些神奇的Transformer微调?
这些模型之间最大的区别,似乎只是数据集。OpenAI有人提到过,他们训练了大量的类GPT模型,与训练数据相比,架构更改对性能的影响不大。

有人表示,对「7Bx8E=50B」的说法很感兴趣。是否是因为此处的「集成」是基于LoRa方法,从而节省了很多参数?
(7x8=56,而6B对于LoRa方法来说节省得很少,主要是因为它可以重复使用预训练权重)
有人已经期待,有望替代Transformer的全新Mamba架构能够完成这项工作,这样Mistral-MoE就可以更快、更便宜地扩展。

OpenAI科学家Karpathy的言语中,还暗戳戳嘲讽了一把谷歌Gemini的虚假视频演示。

毕竟,比起提前剪辑好的视频demo,Mistral AI的宣传方式实在太朴素了。
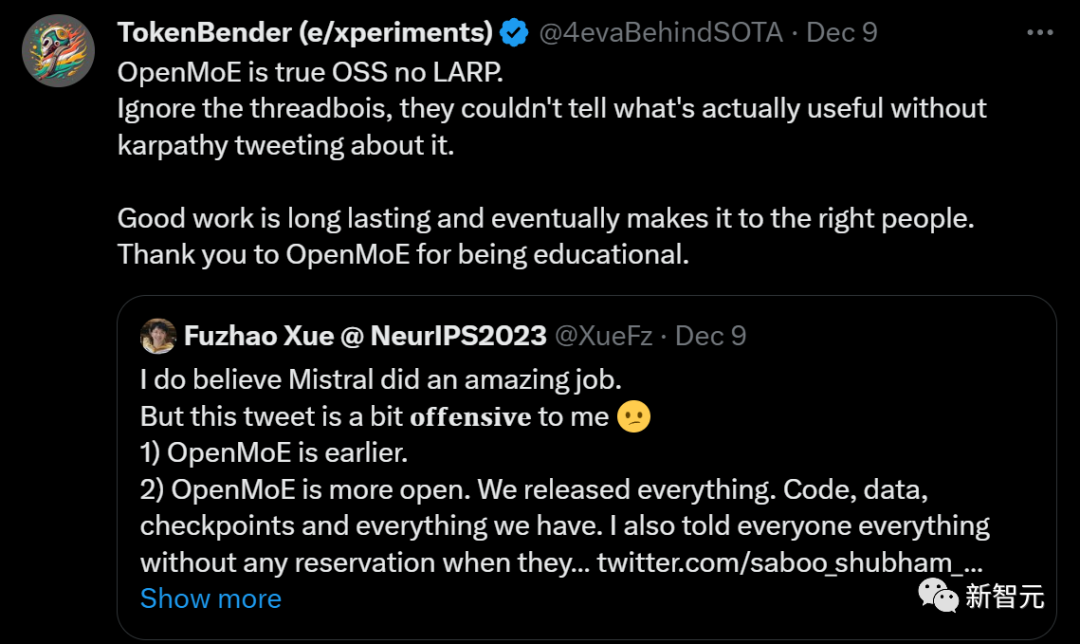
不过,对于Mitral MoE是第一个开源MoE大模型的说法,有人出来辟了谣。
在Mistral放出这个开源的7B×8E的MoE之前,英伟达和谷歌也放出过其他完全开源的MoE。

曾在英伟达实习的新加坡国立大学博士生Fuzhao Xue表示,他们的团队在4个月前也开源了一个80亿参数的MoE模型。
由前Meta和谷歌研究人员创立,这家总部位于巴黎的初创公司Mistral AI,仅凭6个月的时间逆袭成功。
值得一提的是,Mistral AI已在最新一轮融资中筹集3.85亿欧元(约合4.15亿美元)。

这次融资让仅有22名员工的明星公司,估值飙升至约20亿美元。
这次参与投资的,包括硅谷的风险投资公司Andreessen Horowitz(a16z)、英伟达、Salesforce等。

6个月前,该公司刚刚成立仅几周,员工仅6人,还未做出任何产品,却拿着7页的PPT斩获了1.13亿美元巨额融资。
现在,Mistral AI估值相当于翻了近10倍。
说来这家公司的名头,可能并不像OpenAI名满天下,但是它的技术能够与ChatGPT相匹敌,算得上是OpenAI劲敌之一。
而它们分别是两个极端派————开源和闭源的代表。

Mistral AI坚信其技术以开源软件的形式共享,让任何人都可以自由地复制、修改和再利用这些计算机代码。
这为那些希望迅速构建自己的聊天机器人的外部开发者提供了所需的一切。
然而,在OpenAI、谷歌等竞争对手看来,开源会带来风险,原始技术可能被用于传播假信息和其他有害内容。
Mistral AI背后开源理念的起源,离不开核心创始人,创办这家公司的初心。
今年5月,Meta巴黎AI实验室的研究人员Timothée Lacroix和Guillaume Lample,以及DeepMind的前员工Arthur Mensch共同创立Mistral AI。

论文地址:https://arxiv.org/pdf/2302.13971.pdf
人人皆知,Meta一直是推崇开源公司中的佼佼者。回顾2023年,这家科技巨头已经开源了诸多大模型,包括LLaMA 2、Code LLaMA等等。
因此,不难理解Timothée Lacroix和Guillaume Lample创始人从前东家继承了这一传统。

有趣的是,创始人姓氏的首字母恰好组成了「L.L.M.」。
这不仅是姓名首字母简写,也恰好是团队正在开发的大语言模型(Large Language Model)的缩写。
这场人工智能竞赛中,OpenAI、微软、谷歌等科技公司早已成为行业的佼佼者,并在LLM研发上上斥资数千亿美元。
凭借充足的互联网数据养料,使得大模型能自主生成文本,从而回答问题、创作诗歌甚至写代码,让全球所有公司看到了这项技术的巨大潜力。
因此OpenAI、谷歌在发布新AI系统前,都将花费数月时间,做好LLM的安全措施,防止这项技术散播虚假信息、仇恨言论及其他有害内容。
Mistral AI的首席执行官Mensch表示,团队为LLM设计了一种更高效、更具成本效益的训练方法。而且模型的运行成本不到他们的一半。
有人粗略估计,每月大约300万美元的Mistral 7B可以满足全球免费ChatGPT用户100%的使用量。

6他们对自家模型的既定目标,就是大幅击败ChatGPT-3.5,以及Bard。

然而,很多AI研究者、科技公司高、还有风险投资家认为,真正赢得AI竞赛的将是——那些构建同样技术并免费提供给大众的公司,且不设任何安全限制。
Mistral AI的诞生,如今被视为法国挑战美国科技巨头的一个机遇。
自互联网时代开启以来,欧洲鲜有在全球影响重大的科技公司,但在AI领域,Mistral AI让欧洲看到了取得进展的可能。
另一边,投资者们正大力投资那些信奉「开源理念」的初创公司。

去年12月,曾在OpenAI和DeepMind担任研究科学家创立了Perplexity AI,在最近完成了一轮7000万美元的融资,公司估值达到了5亿美元。
风险投资公司a16z的合伙人Anjney Midha对新一轮Mistral的投资表示:
我们坚信 AI 应该是开放源代码的。推动现代计算的许多主要技术都是开源的,包括计算机操作系统、编程语言和数据库。广泛分享人工智能底层代码是最安全的途径,因为这样可以有更多人参与审查这项技术,发现并解决潜在的缺陷。
没有任何一个工程团队能够发现所有问题。大型社区在构建更便宜、更快、更优、更安全的软件方面更有优势。
创始人Mensch在采访中透露,公司目前还没有盈利,不过会在「年底前」发生改变。
目前,Mistral AI已经研发了一个访问AI模型的新平台,以供第三方公司使用。
参考资料:
https://www.nytimes.com/2023/12/10/technology/mistral-ai-funding.html
https://twitter.com/DrJimFan/status/1733864317227786622
https://github.com/open-compass/MixtralKit/blob/main/README_zh-CN.md
文章来自于 微信公众号“新智元”


【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
