# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能快速发展的今天,提示工程(Prompt Engineering)已经成为AI应用开发中不可或缺的环节。然而,当我们需要生成适应不同场景的情感文本时,传统的单一目标提示优化方法往往显得力不从心。例如,在新闻标题中表达愤怒情绪时需要委婉专业,而在社交媒体上则可以更加直接和口语化。如何让一个提示系统能够同时适应这些不同的表达需求,成为了一个亟待解决的问题。

来自斯图加特大学和班贝格大学的研究团队提出了一种突破性的解决方案——多目标提示优化方法(Multi-Objective Prompt Optimization,简称MOPO)。这种方法不仅能够同时优化多个目标,还能让用户根据具体需求选择最适合的提示策略。
研究团队通过一个具体的例子来理解MOPO的实际效果。以天气预警信息生成为例,需要同时适应新闻标题和社交媒体两种场景。
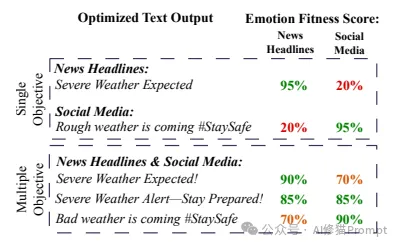
单目标vs多目标优化的文本生成效果对比。 该图展示了在天气预警场景下,不同优化策略生成的文本及其在新闻和社交媒体两个维度上的适应度分数:
1.单目标优化效果
2.多目标优化效果
从这个案例可以看出,MOPO成功实现了在不同场景下的平衡:
这个例子很好地展示了MOPO在实际应用中的优势:能够根据不同场景的需求,生成既保持专业性又具有适当表达方式的文本。
MOPO的最大创新在于其独特的三层优化架构。每一层都承担着不同的功能,共同构成了一个完整的优化系统:
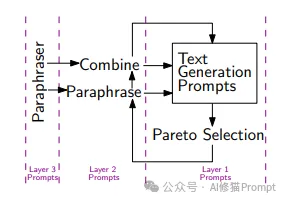
第一层(Layer-1)是基础提示层,负责生成满足基本任务需求的提示。例如"写一段表达喜悦的文本"这样的基础提示。这一层的提示直接决定了生成文本的基本框架和内容方向。

第二层(Layer-2)是优化操作层,包含两种关键操作:重写(Paraphrase)和组合(Combine)。重写操作通过改变提示的表达方式来探索更好的效果,而组合操作则尝试将不同提示的优点结合起来。这一层的设计让系统能够不断进化和改进提示质量。

第三层(Layer-3)是选择层,负责从众多候选提示中筛选出最优的结果。这一层采用了帕累托最优化原则,确保选出的提示在多个目标上都达到较好的平衡。

MOPO算法的核心流程伪代码。 该算法伪代码详细展示了MOPO系统如何通过迭代优化实现多目标提示的生成和筛选:

1.初始化阶段(Input部分)
2.迭代优化过程(while循环部分)
3.选择机制(Selection部分)
4.输出结果(Output部分)
这个算法展示了MOPO如何将遗传算法的思想应用到提示优化中,通过不断的迭代和优化,最终得到能够适应多个场景的高质量提示。关于遗传算法您可以看下谷歌DeepMind2024年的重要论文《Prompt迭代,你应该了解DeepMind自主进化的提示系统》,我在《AI修猫Prompt公众号文章赞赏赠与资料分类汇总》
MOPO的创新之处不仅在于整体架构,更体现在其核心操作的具体实现上。系统主要通过两种操作来优化提示:组合(Combine)和重写(Paraphrase)。
MOPO中的Combine操作算法流程。 该算法详细描述了MOPO如何实现提示的组合优化:

1.输入部分
2.执行过程
3.输出结果
组合操作的核心目标是将不同提示的优点进行有效融合。例如,当一个提示在正式性上表现良好,另一个在情感表达上更为出色时,组合操作会尝试创造一个兼具这两种特点的新提示。
MOPO中的Paraphrase操作算法流程。 该算法详细展示了MOPO如何通过多层次重写来优化提示:

1.输入部分
2.重写过程
3.输出结果
重写操作通过多层次的语言变换,帮助系统探索更多可能的表达方式。它不仅能保持原有提示的核心语义,还能通过不同的表达方式来适应不同的应用场景。
这两种操作相互配合,构成了MOPO的核心优化机制。组合操作确保了不同提示优点的融合,而重写操作则保证了表达方式的多样性。通过这种双重优化机制,MOPO能够生成在多个目标上都表现良好的提示。
MOPO采用了改进的遗传算法来实现多目标优化。研究团队巧妙地将传统遗传算法中的交叉(Crossover)和变异(Mutation)操作转化为语言模型可以理解和执行的提示操作。
在交叉操作中,系统会选择两个表现良好的提示,通过语言模型将它们的优点结合起来,生成新的提示。例如,一个提示可能擅长生成正式的表达,另一个则更适合口语化表达,交叉操作会尝试创造一个能够同时满足这两种风格的新提示。
变异操作则通过改写现有提示来探索新的可能性。系统会要求语言模型用不同的方式表达同样的意思,从而产生新的变体。这种操作有助于增加提示的多样性,避免优化过程陷入局部最优。
研究团队使用了三个不同特点的数据集来验证MOPO的效果:

MOPO算法的多目标优化效果。 该三维散点图展示了从第1代(深蓝色点)到第10代(黄色点)中表现最好的10个提示在三个评估维度(ISEAR、TEC和Affective Text)上的分布情况。
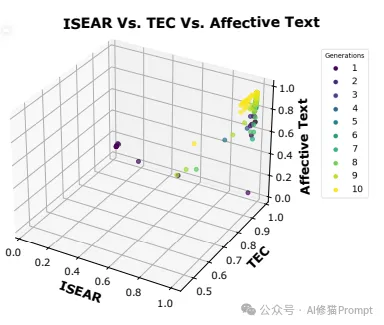
从图中可以清晰地观察到:
1.优化进程:随着代数的增加(颜色从深蓝变为黄色),提示在三个维度上的表现都有明显提升。
2.多目标平衡:后期生成的提示(黄色点)能够在多个目标上同时达到较高分数,证明了MOPO在多目标优化方面的有效性。
3.收敛效果:到最后几代时,大多数提示都能达到接近1的高分,表明算法具有良好的收敛性能。
这个结果直观地证明了MOPO能够通过迭代优化,逐步提升提示在多个目标上的综合表现,最终实现多领域情感文本生成的需求。
实验结果令人振奋。在多目标优化后,MOPO生成的提示在跨域表现上有了显著提升:
单一情感的优化分析
为了深入理解MOPO在具体情感类型上的优化效果,研究团队以"joy"(喜悦)情感为例进行详细分析。
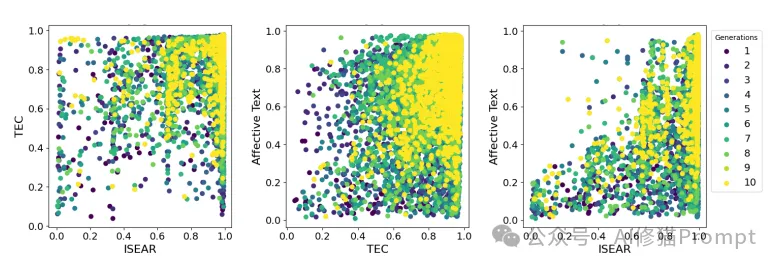
喜悦情感在不同数据集间的优化效果对比。 该图展示了从第1代到第10代,提示在生成喜悦情感文本时在ISEAR、TEC和Affective Text三个数据集之间的两两对比关系。每个散点图比较了两个数据集之间的得分,点的颜色从深蓝到黄表示从第1代到第10代的演化过程。
从图中可以观察到以下关键发现:
1.持续优化:随着代数增加(颜色从深蓝变为黄色),点的分布逐渐向右上角(高分区域)集中,表明MOPO能够持续改进提示的质量。
2.跨数据集平衡:在最后一代(黄色点),大多数提示在不同数据集之间都达到了接近1的高分,说明MOPO成功实现了跨数据集的优化平衡。
3.优化稳定性:从散点的分布可以看出,优化过程是渐进且稳定的,没有出现剧烈的性能波动。
这个分析证明了MOPO不仅能在整体上实现多目标优化,在处理具体情感类型时也能取得出色的效果。系统能够生成在不同数据集上都表现良好的情感提示,这对于实际应用具有重要意义。
尽管MOPO取得了显著成果,研究团队也坦诚指出了当前系统存在的一些局限:
1.计算资源消耗:多目标优化需要更多的计算资源和时间,这可能会影响系统的实时性能。
2.参数敏感性:系统的性能受到多个参数的影响,如遗传操作的采样数量、文本生成的参数设置等,这些参数的调整需要专业经验。
3.目标函数的局限:当前使用的情感分类器可能无法完全捕捉文本的细微差别,这可能导致某些优化结果不够理想。
4.实验迭代次数:由于资源限制,每组实验只进行了一次,这可能无法完全反映系统的稳定性和可重复性。
基于MOPO的研究成果,我们可以为Prompt工程师提供以下实践建议:
1.多目标思维:在设计提示时,要考虑文本在不同场景下的表现需求,不要局限于单一目标。
2.分层优化:可以借鉴MOPO的三层架构思想,将复杂的提示优化任务分解为多个层次逐步完成。
3.平衡取舍:在多个目标之间寻找平衡点,不必追求在某一个维度上的极致表现。
4.灵活应用:根据具体应用场景的需求,选择合适的优化策略和参数设置。
MOPO的出现为提示优化领域带来了新的可能。它不仅解决了跨域文本生成的实际问题,更为提示工程的未来发展提供了新的思路。对于Prompt工程师来说,理解和掌握MOPO的核心理念和方法,将有助于设计出更加灵活和强大的AI应用。提示优化您也可以看一下:《重磅突破:首个自适应LLM的智能提示优化系统MAPS,让用例生成效率提升超30%》
文章来微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
