# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。
从章鱼通过改变皮肤颜色来融入周围环境,到人类大脑在受伤后重新连接神经网络,无不体现着那句经典的名言——「物竞天择,适者生存」。
然而,对于LLM来说,想要加入哪怕只是一句话的新知识,都必须要再训练一次。
针对这一挑战,来自Sakana AI的研究团队刚刚提出了一种全新的方法——Transformer²。它可以通过实时选择性地调整权重矩阵中的单一组件,使LLM能够适应未见过的任务。

文章链接:https://arxiv.org/pdf/2501.06252
代码链接:https://github.com/SakanaAI/self-adaptive-llms
传统上,LLM的后训练通过一次全面的训练来优化模型,使其具备广泛的能力。
从简化的角度,这种「one shot」微调框架看起来很理想,但在实际操作中却很难实现。例如,后训练需要大量资源,导致计算成本和训练时间显著增加。此外,当引入更多样化的数据时,很难同时克服过拟合和任务干扰。
相比之下,自适应模型提供了一种更灵活高效的方法。与其一次性训练LLM来应对所有任务,不如开发专家模块,根据需求将其离线开发并增强到基础LLM中。
然而,创建多个专家模块,对LLM进行微调,显著增加了需要训练的参数数量,而且容易过拟合,模块之间的组合也不够灵活。
对此,新框架通过有选择性地调整模型权重中的关键组件,让LLM能够实时适应新任务。
Transformer²的名称体现了它的两步过程:首先,模型分析传入的任务,理解其需求;然后应用任务专用的适应性调整,生成最佳结果。
Transformer²在多种任务(如数学、编码、推理和视觉理解)中表现出了显著的进步,在效率和特定任务的表现上超越了传统静态方法如LoRA,同时所需的参数大大减少。

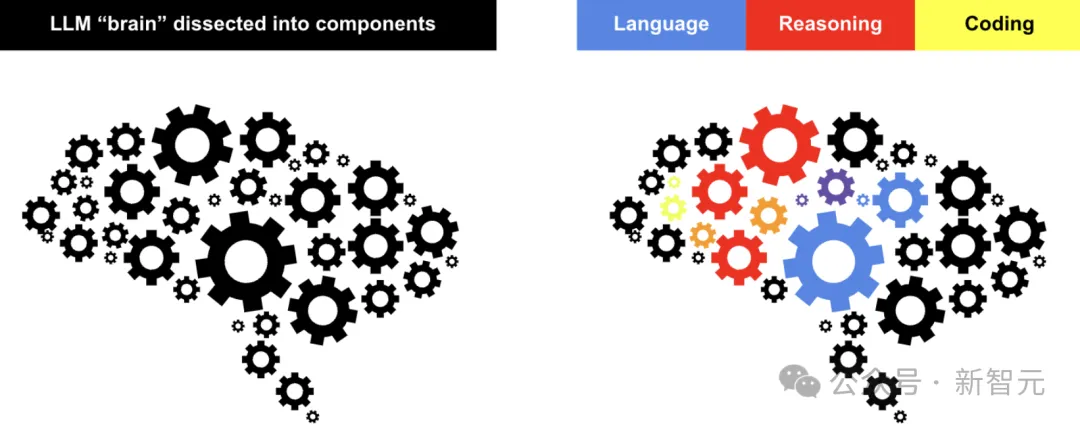
人类大脑通过互联的神经通路,存储知识并处理信息。
而LLM将知识存储在权重矩阵中。这些矩阵构成了LLM的「大脑」,保存了它从训练数据中学习到的核心内容。
要理解这个「大脑」,并确保它能够有效地适应新任务,需要深入分析其内部结构。
而奇异值分解(SVD)提供了宝贵的洞察力。
可以将SVD看作是一名外科医生,正在对LLM的大脑进行细致操作。这名外科医生将LLM中存储的庞大复杂的知识分解成更小、更有意义且独立的部分(例如,针对数学、语言理解等的不同路径或组件)。
SVD通过识别LLM权重矩阵中的主成分来实现这一目标。
在新研究中发现,增强某些成分的信号,同时抑制其他部分的信号,可以提高LLM在下游任务中的表现。
基于这一发现,Transformer²迈出了下一步,向动态、任务特定的适应性发展,让LLM能在多种复杂场景中表现得更加出色。
Transformer²通过两步过程重新定义了LLM如何应对多样的任务。
其核心在于能够动态调整权重矩阵中的关键组件。
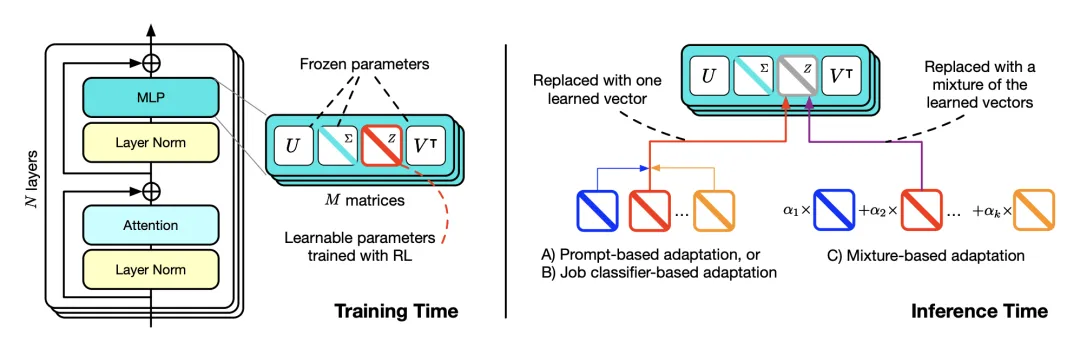
在训练阶段,引入了奇异值微调(SVF)方法,该方法使用强化学习(RL)来增强或抑制不同「大脑」组件的信号,以应对多种下游任务。
在推理阶段,新方法采用三种不同的策略来识别任务的特征,并根据任务要求调整模型的权重。
下图概述了新方法。
左图:使用SVD将LLM的「大脑」(即权重矩阵)分解为若干独立的组件。
右图:利用RL训练这些组件的组合以应对不同任务。组件可能在多个任务中共享。例如,在上图中,紫色齿轮在语言理解和推理任务之间是共享的。推理时,首先识别任务类型,然后动态调整组件的组合。
在训练阶段,SVF学习一组z向量,其中每个下游任务对应一个z向量。
每个z向量可以视作该任务的专家,它是一个紧凑的表示,指定了权重矩阵中每个组件的期望强度,充当「放大器」或「衰减器」,调节不同组件对模型行为的影响。
例如,假设SVD将权重矩阵分解为五个组件[A,B,C,D,E]。
对于数学任务,学习到的z向量可能是[1,0.8,0,0.3,0.5],这表明组件A对数学任务至关重要,而组件C几乎不影响其表现。
对于语言理解任务,z向量可能是[0.1,0.3,1,0.7,0.5],表明尽管C组件对数学任务的贡献较小,但它对语言理解任务至关重要。
SVF利用RL在预定义的下游任务集上学习这些z向量。
学习到的z向量使Transformer²能够适应各种新的下游任务,同时仅引入最少量的附加参数(即z向量)。
在推理阶段,新框架使用两阶段适应策略,有效地结合了任务专用的z向量。
在第一次推理阶段,给定任务或单个输入提示,Transformer²通过以下三种适应方法之一来分析测试时的条件。
在第二阶段,Transformer²结合这些z向量来调节权重,从而生成最适合新设置的最终响应。
新研究总结了三种任务检测/适应方法如下:
1.基于提示的适应:使用专门设计的适应性提示,对任务分类(如数学、编程),并选择一个预训练的z向量。
2.基于分类器的适应:使用SVF训练的任务分类器在推理时识别任务,并选择合适的z向量。
3.少样本适应:通过加权插值结合多个预训练的z向量。简单的优化算法根据在少样本评估集上的表现调整这些权重。
这三种方法共同确保了Transformer²能够实现强大且高效的任务适应,为其在多种场景下的出色表现奠定了基础。
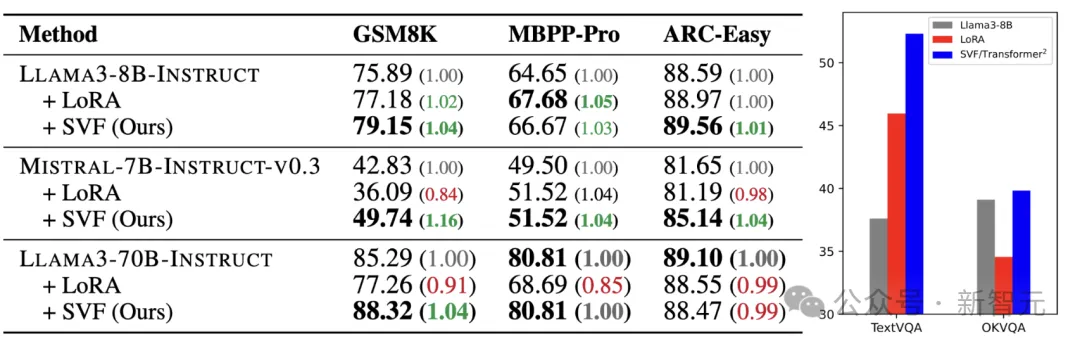
作者将这些方法应用于Llama和Mistral LLM,在广泛的任务上进行测试,包括数学(GSM8K,MATH)、代码(MBPP-Pro,HumanEval)、推理(ARC-Easy,ARC-Challenge)和视觉问答(TextVQA,OKVQA)。
首先通过SVF在这些任务上获取z向量,并与LoRA进行了比较。
下表中的结果表明,SVF在文本任务上优于LoRA,特别是在GSM8K任务上有显著提升。这可以归因于RL训练目标。与LoRA的微调方法不同,RL不要求每个问题都有「完美解决方案」。右侧的直方图也展示了SVF在视觉领域的惊人表现。
随后将适应框架与LoRA在未见过的任务上进行对比评估,特别是在MATH、HumanEval和ARC-Challenge任务上。
下表左侧展示了,随着方法复杂度的提升,新架构的策略在所有任务上都取得了逐步的性能提升。
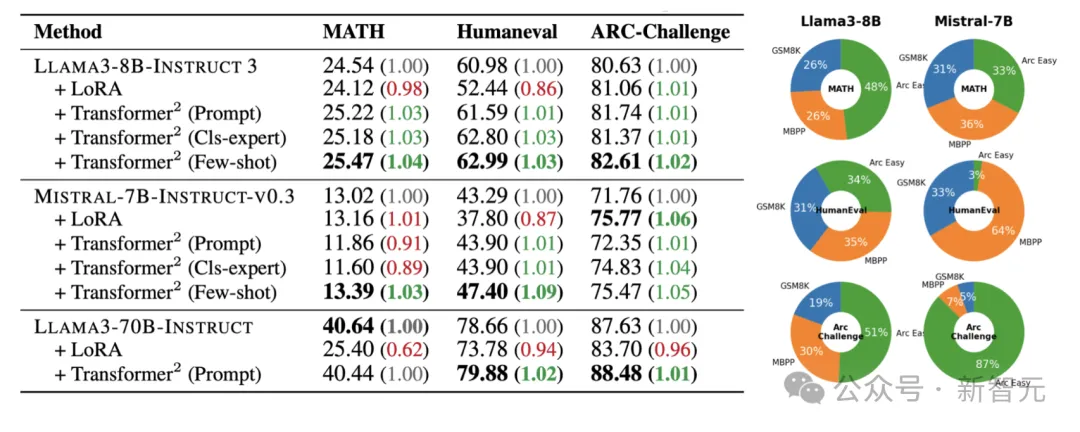
在未见任务上的测试集表现。左图:在未见任务上的自适应。右图:学习到的z向量插值权重。
而右图分析了少样本(few-shot)学习如何结合不同的z向量来处理任务。
在解决MATH问题时,出乎意料的是,模型并非仅依赖于其专门为GSM8K(数学)任务训练的z向量。这表明,复杂的数学推理任务有益于结合数学、编程和逻辑推理能力。
在其他任务和模型中也观察到了类似的意外组合,凸显了该框架能够综合多种专业知识,从而实现最佳表现。
最后,作者探索了一个挑战传统AI发展理念的有趣问题:能否将一个模型的知识转移到另一个模型中?令人兴奋的是,将Llama学习到的z向量转移到Mistral时,作者观察到后者在大多数任务上表现出提升。下表中给出了详细的结果。
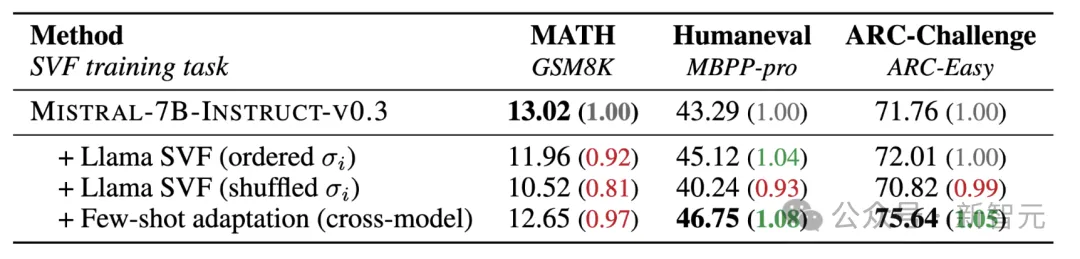
尽管这些发现具有前景,但需要注意的是,这两个模型具有相似的架构,这可能是它们能够兼容的原因。
不同AI模型之间是否能实现知识共享仍然是一个悬而未决的问题。
然而,这些结果暗示了一个令人兴奋的可能性:打开特定任务技能的解耦与重用的大门,为更新的、更大的模型提供支持。
但这仅仅是开始。Transformer²为呈现了未来的场景:AI系统不再是为固定任务训练的静态实体。相反,它们将体现「活体智能」,即不断学习、演化和适应的模型。
像Transformer²这样的自适应系统弥合了静态AI与「活体智能」之间的差距,为高效、个性化、完全集成的AI工具铺平道路,这些工具将推动各个行业的进步以及我们日常生活的发展。

共同一作Qi Sun,目前是东京工业大学研究助理。他从2023年开始在Sakana AI做兼职研究员。2024年10月,他获得了东京科学大学的博士学位。此前,他在东京工业大学获得硕士学位,在大连理工大学获得学士学位。

共同一作Yujin Tang,2024年1月起担任Sakana AI的研究科学家,研究领域为强化学习和机器人。此前在DeepMind、谷歌等公司从事研发工作。他在东京大学获得博士学位,在早稻田大学获得硕士学位,在上海交通大学获得学士学位。
参考资料:
https://arxiv.org/abs/2501.06252
https://sakana.ai/transformer-squared/
文章来自于“新智元”,作者“KingHZ 好困”。




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
